Sicherheits- und Vertrauenscenter
Ihre Datensicherheit ist unsere Priorität

Der Ansatz für verantwortungsvolle KI von Databricks
Databricks vertritt die Ansicht, dass der Fortschritt bei der KI auf dem Aufbau von Vertrauen in intelligente Anwendungen beruht. Dazu müssen wir uns bei der Entwicklung und Nutzung von KI an verantwortungsvolle Praktiken halten. Das setzt voraus, dass jedes Unternehmen die Verantwortung und Kontrolle über seine Daten und seine KI-Modelle hat – mit umfassender Überwachung, Datenschutzkontrollen und Governance während der gesamten KI-Entwicklung und -Implementierung.
Das Responsible AI Testing Framework von Databricks: GenAI-Modelle für das Red Teaming
Das Red Teaming ist im KI-Bereich und insbesondere bei Large Language Models ein wichtiger Bestandteil der sicheren Entwicklung und Implementierung von Modellen. Databricks führt das Red Teaming regelmäßig für intern entwickelte KI-Modelle und Systeme durch. Nachstehend finden Sie einen Überblick über unser Responsible AI Testing Framework. Er zeigt, welche Verfahren wir intern in unserem Adversarial ML Lab verwenden, um unsere Modelle zu testen, und weitere Techniken, die wir für den künftigen Einsatz beim Red Teaming in unserem Labor evaluieren.
WICHTIGER HINWEIS: Wir müssen an dieser Stelle einräumen, dass der Bereich des KI-Red-Teaming noch in den Kinderschuhen steckt und das extrem hohe Innovationstempo Chancen wie Herausforderungen gleichermaßen mit sich bringt. Wir sind bestrebt, kontinuierlich neue Ansätze für Angriffe und Gegenangriffe zu evaluieren und diese ggf. in den Prüfprozess für unsere Modelle einzubringen.
Hier sehen Sie eine schematische Darstellung unseres GenAI Testing Framework:
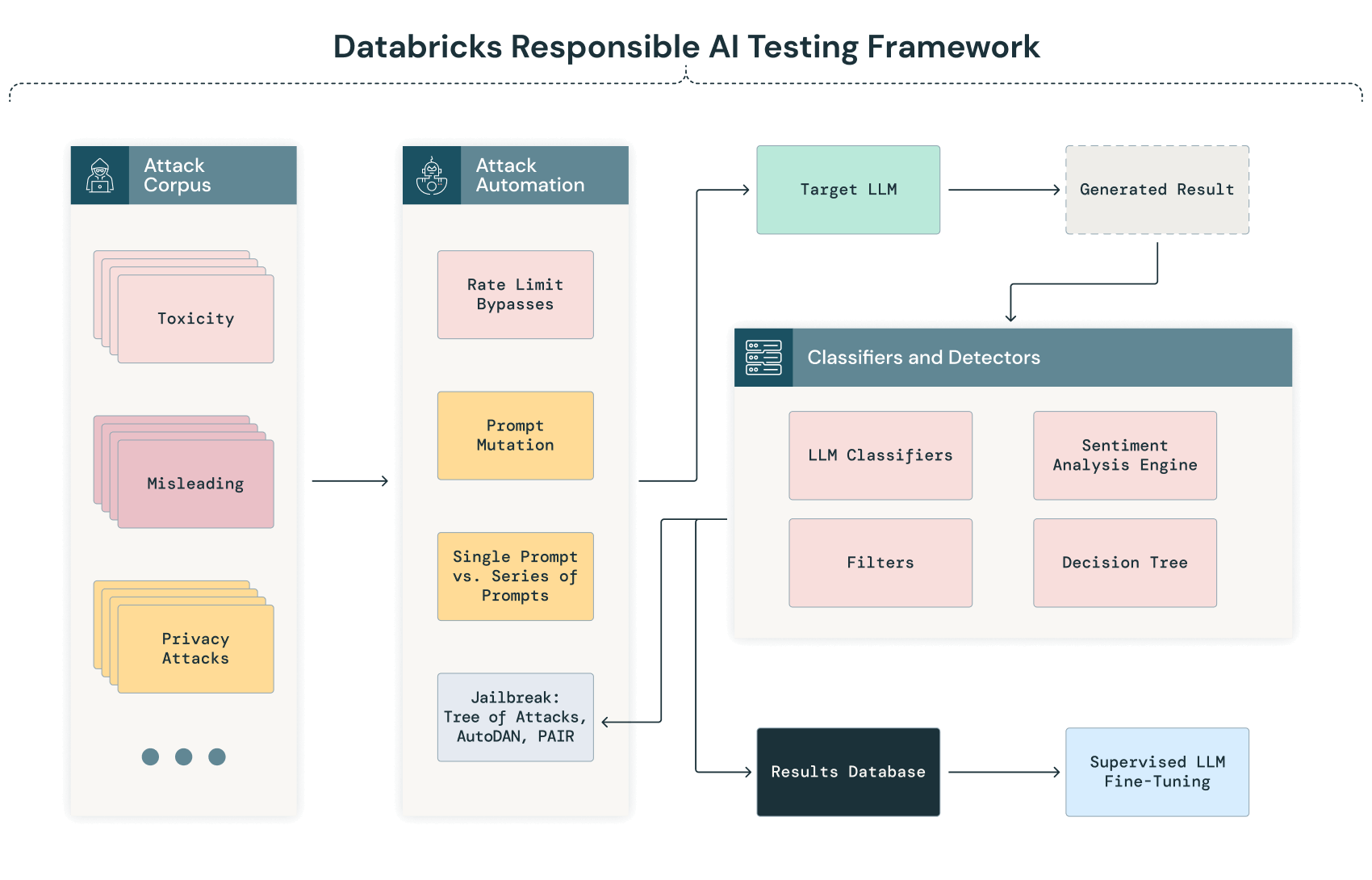
Automatisierte Prüfung und Klassifizierung
Die Anfangsphase unseres KI-Red-Teaming-Verfahrens umfasst einen automatisierten Prozess, bei dem dem Modell systematisch eine Reihe verschiedener Textkorpora übermittelt wird. Dieser Prozess zielt darauf ab, die Antworten des Modells in einer Vielzahl von Szenarien zu prüfen und potenzielle Schwachstellen, Abweichungen oder Datenschutzbedenken automatisch zu identifizieren, bevor eine eingehendere manuelle Analyse erfolgt.
Während das LLM diese Eingaben verarbeitet, werden seine Ausgaben automatisch erfasst und anhand vordefinierter Kriterien klassifiziert. Diese Klassifizierung kann NLP-Techniken (Natural Language Processing) und andere KI-Modelle umfassen, die darauf trainiert sind, Anomalien, Verzerrungen oder Abweichungen von der erwarteten Ausführung zu erkennen. Eine Ausgabe könnte beispielsweise zur manuellen Überprüfung vorgemerkt werden, wenn sie mögliche Verzerrungen, unsinnige Antworten oder Hinweise auf Datenschutzverletzungen aufweist.
LLM-Jailbreaking
Databricks nutzt verschiedene Verfahren für das Jailbreaking von LLMs:
- Direkte Anweisungen (Direct Instructions, DI): Vom Angreifer abgesetzte Prompts, die explizit nach schädlichen Inhalten fragen.
- DAN-Prompts (Do Anything Now): Eine Vielzahl von Angriffen, die das Modell zu einem "Do Anything Now"-Chat-Agent machen sollen. Ein solcher Chat-Agent kann beliebige Aufgaben ohne Berücksichtigung ethischer oder sicherheitsrelevanter Aspekte erledigen.
- Angriffe nach Art von Riley Goodside: Eine Abfolge von Angriffen, bei denen das Modell direkt aufgefordert wird, die eingegebenen Prompts zu ignorieren. Bekannt gemacht wurde diese Angriffsform von Riley Goodside.
- Agency Enterprise PromptInject Corpus: Einspielen des Agency Enterprise Prompt Injection-Korpus, der beim NeurIPS ML Safety Workshop 2022 mit dem Best Paper Awards ausgezeichnet wurde.
- Prompt Automatic Iterative Refinement (PAIR): Ein auf Angriffe spezialisiertes Large Language Model wird verwendet, um den Prompt immer wieder zu verfeinern und ihn auf einen Jailbreak auszurichten.
- Tree of Attacks With Pruning (TAP): Ähnelt einem PAIR-Angriff, jedoch wird ein zusätzliches LLM verwendet, um festzustellen, wann die generierten Prompts vom eigentlichen Thema abzuweichen beginnen, und sie dann aus der Angriffsstruktur zu streichen.
Jailbreak-Tests liefern zusätzliche Erkenntnisse über die Fähigkeit eines Modells, zu generalisieren und auf Prompts zu reagieren, die deutlich von den Trainingsdaten abweichen oder einen anderen Zugang zu geschützten Informationen bieten. Auf diese Weise können wir auch feststellen, wie ein Angriff LLMs dazu bewegen kann, schädliche oder anderweitig unerwünschte Inhalte auszugeben.
Da dieser Bereich derzeit stetiger Weiterentwicklung unterliegt, werden wir auch künftig neue Verfahren in Betracht ziehen und bewerten, sobald sich die Rahmenbedingungen beim Jailbreaking ändern.
Manuelle Prüfung und Analyse
Im Anschluss an die automatisierte Phase erfolgt beim KI-Red-Teaming eine manuelle Überprüfung der gemeldeten Ergebnisse sowie – um die Wahrscheinlichkeit zu erhöhen, dass alle kritischen Probleme erkannt werden – eine stichprobenartige Prüfung der nicht auffälligen Ausgaben. Diese manuelle Analyse ermöglicht eine nuancierte Deutung und Validierung der im Rahmen des automatisierten Prozesses ermittelten Probleme.
Der manuelle Aufwand beim KI-Red-Teaming ist beträchtlich, da die automatisierten Scans möglicherweise Ergebnisse liefern, die keine Bedenken aufkommen lassen; bei der manuellen Beurteilung durch das Red Team werden jedoch ggf. Varianten untersucht, bei denen Prompts optimiert oder verkettet werden, um Schwachstellen zu finden, die sonst von den automatisierten Scans nicht erkannt würden.
Sicherheit in der Modelllieferkette
Im Zuge der Weiterentwicklung unserer Bemühungen beim KI-Red-Teaming führen wir auch Prozesse zur Bewertung der Sicherheit der KI-Modelllieferkette – vom Training über die Implementierung bis hin zur Distribution – ein. Derzeit werden unter anderem die folgenden Bereiche evaluiert:
- Kompromittierung von Trainingsdaten („Poisoning“ durch Beschriftungsmanipulation oder Einspeisung von Schaddaten)
- Kompromittierung der Trainingsinfrastruktur (GPU, VM usw.)
- Zugriff auf die eingesetzten LLMs, um Gewichtungen und Hyperparameter zu manipulieren
- Manipulation von Filtern und anderen eingesetzten Abwehrmechanismen
- Kompromittierung der Modelldistribution, etwa durch Beeinflussung vertrauenswürdiger Dritter (Hugging Face)
Fortlaufende Feedbackschleife
Als weiterer Bereich bei unserem KI-Red-Teaming wird ein Prozess für eine fortlaufende Feedbackschleife für Verbesserungen hinzukommen. Hiermit sollen Erkenntnisse aus automatischen Scans und manuellen Analysen erfasst werden. Ziel dieser fortlaufenden Verbesserungsschleife ist es, unsere Modelle noch robuster zu machen und an den höchsten Leistungsstandards auszurichten.
Kategorien der vom Databricks Red Team verwendeten Tests
Databricks nutzt eine Reihe kuratierter Korpora, die während der Tests an das Modell gesendet werden. Diese so genannten „Probes“ sind spezielle Tests oder Experimente, die das KI-System auf verschiedene Weise herausfordern sollen. Bei jedem Test, der ein erfolgreiches, nicht gegen die Richtlinien verstoßendes Ergebnis liefert, überprüft das Red-Team auf Fehlverhalten in der Modellantwort, indem es verschiedene Varianten desselben Tests ausprobiert. Im LLM-Kontext können die vom Databricks Red Team verwendeten Tests wie folgt kategorisiert werden:
Sicherheitstests
- Eingabemanipulation: Testet die Reaktion des Modells auf veränderte, verzerrte oder schädliche Eingaben, um Sicherheitslücken in der Datenverarbeitung aufzudecken.
- Vermeidungstechniken: Versucht, die Sicherheitseinrichtungen oder Filter eines Modells zu umgehen, um schädliche oder unerwünschte Ausgaben zu bewirken.
- Modellinversion: Versucht, sensible Informationen aus dem Modell zu extrahieren und dadurch den Datenschutz zu umgehen.
Tests zu ethischem Verhalten und Voreingenommenheit
- Bias-Erkennung: Bewertet das Modell anhand der Analyse der Antworten auf bestimmte Prompts auf Vorurteile in Bezug auf Ethnie, Geschlecht, Alter usw.
- Ethische Dilemmata: Legt dem Modell Szenarien vor, die seine Ausrichtung an ethischen Normen und Werten testen.
Tests auf Robustheit und Zuverlässigkeit
- Angriffe von außen: Schleust geringfügig veränderte Eingaben ein, die das Modell täuschen und zu falschen Ergebnissen führen sollen.
- Konsistenzprüfungen: Testet die Fähigkeit des Modells, konsistente und zuverlässige Antworten bei ähnlichen oder wiederholten Abfragen zu liefern.
Tests auf Compliance und Sicherheit
- Einhaltung gesetzlicher Vorschriften: Prüft Ergebnisse und Prozesse des Modells auf Übereinstimmung mit geltenden Vorschriften.
- Sicherheitsszenarien: Bewertet das Verhalten des Modells in Szenarien, in denen die Sicherheit eine entscheidende Rolle spielt. Dadurch sollen Schäden oder riskante Empfehlungen vermieden werden.
- Datenschutztests: Prüft das Modell auf Einhaltung von Datenschutzstandards und -vorschriften wie z. B. DSGVO oder HIPAA. Anhand dieser Tests wird beurteilt, ob das Modell in seinen Ausgaben unzulässigerweise personenbezogene oder vertrauliche Informationen preisgibt oder es manipuliert werden könnte, um solche Daten zu extrahieren.
- Steuerbarkeit: Testet, wie einfach ein menschlicher Bediener in das Modell eingreifen oder die Ergebnisse und das Verhalten des Modells kontrollieren kann.


