
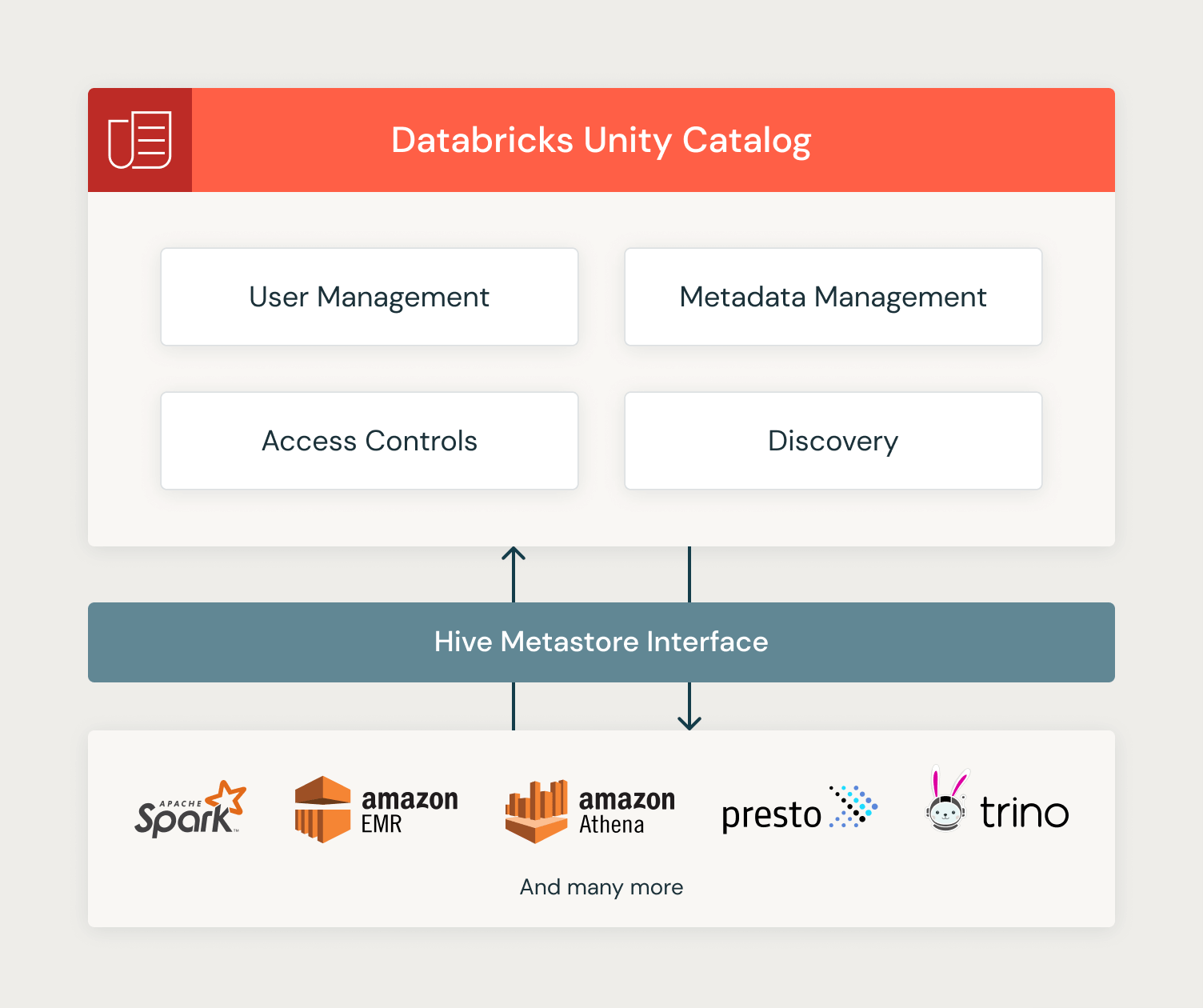

Unity Catalogによる分散型データガバナンスと孤立した環境の実現
Original : Distributed Data Governance and Isolated Environments with Unity Catalog 翻訳: junichi.maruyama データ、アナリティクス、AIに業務を依存する組織では、効果的なデータガバナンスが不可欠です。多くの組織で、集中型データガバナンスの価値提案に対する認識が高まってきています。しかし、最高の意図を持っていても、適切な組織プロセスとリソースがなければ、集中型ガバナンスの導入は困難な場合があります。多くの組織では、最高データ責任者(CDO)の役割がまだ確立されておらず、誰��が組織全体のデータガバナンス方針を定義し、実行するのかについて疑問が残ります。 その結果、組織全体のデータガバナンスポリシーを定義し実行する責任が一元化されていないことが多く、組織内のビジネスライン、サブユニット、その他の部門間でポリシーが異なったり、管理団体が異なったりすることになります。簡単のため、このパターンを分散型ガバナンスと呼ぶことにしま

Serving Up a Primer for Unity Catalog Onboarding
Introduction This blog is part of our Admin Essentials series, where we'll focus on topics important to those managing and maintaining Databricks environments...

ようこそOkera: AIを中心としたアプローチでガバナンスを実現する
Original: Welcome Okera: Adopting an AI-centric approach to governance 翻訳: junichi.maruyama Databricksは10年にわたり、世界中の組織のためにデータとAIの民主化に力を注いできました。そして、昨年11月のChatGPTのデビュー、そして最近の Dolly 2.0 の導入以来、すべてのお客様が、AIと大規模言語モデル(LLM)の力をビジネスでどのように活用できるかを私たちに尋ねています。また、その直後には、この新しい世界でデータのセキュリティとプライバシーをどのように守ることができるのか、という質問も寄せられています。 そこで当社は、世界初のAI中心のデータガバナンスプラットフォームであるOkeraを買収する正式契約を締結したことを発表します。Okeraは、データとAIのスペクトルにわたって、データプライバシーとガバナンスの課題を解決します。データの可視性と透明性を簡素化し、LLMの時代に不可欠なデータの理解や、その