


This is a guest blog from our friends at Sellpoints.
Saman is a Data Engineer at Sellpoints, where he responsible for developing, optimizing, and maintaining our backend ETL. Chris is a Data Scientist at Sellpoints, where he is responsible for creating and maintaining analytics pipelines, and developing user behavior models.
The simplest way to describe Sellpoints is we help brands and retailers convert shoppers into buyers using data analytics. The two primary areas of business for Sellpoints include some of the largest and most complex data sets imaginable; we build and syndicate interactive content for the largest online retailers to help brands increase conversions, and we provide advanced display advertising solutions for our clients. We study behavior trends as users browse retail sites, interact with our widgets, or see targeted display ads. Tracking these events amounts to an average of 5,500 unique data points per second.
The Data Team’s primary role is to turn our raw event tracking data into aggregated user behavior information, useful for decision-making by our account managers and clients. We track how people interact with retailer websites prior to purchasing. Our individual log lines represent a single interaction between a customer and some content related to a product, which we then aggregate to answer questions such as “how many visits does a person make prior to purchasing,” or “how much of this demonstration video do people watch before closing the window, and are customers more likely to purchase after viewing?” The Data Team here at Sellpoints is responsible for creating user behavior models, producing analytical reports and visualizations for the content we track, and maintaining the visualization infrastructure.
In this blog, we will describe how Sellpoints is able to not only implement our entire backend ETL using the Databricks platform, but unify the entire ETL.
Use Case: Centralized ETL
Sellpoints needed a big data processing platform, one that would be able to replicate our existing ETL, based in Amazon Web Services (AWS), but improve speed and potentially integrate data sources beyond S3, including MySQL and FTP. We also wanted the ability to test MLlib, Apache Spark’s machine learning library. We were extremely happy to be accepted as one of Databricks early customers, and outline our goals:
Short Term Goals:
- Replicate existing Hive-based ETL in SparkSQL – processing raw CSV log files into useable tables, optimizing the file size, and partitioning as necessary
- Aggregate data into tables for visualization
- Extract visualization tables with Tableau
Long Term Goals:
- Rewrite ETL in Scala/Spark and optimize for speed
- Integrate MySQL via the JDBC
- Test and productize MLlib algorithms
- Integrate Databricks further into our stack
We have a small Data Team at Sellpoints, consisting of three Data Engineers, one Data Scientist, and a couple Analysts. Because our team is small and we do not have the DevOps resources to maintain a large cluster ourselves, Databricks is the perfect solution. Their platform allows the analysts to spin up clusters with the click of a button, without having to deal with installing packages or specific versions of software. Additionally, Databricks provides a notebook environment for Spark and makes data discovery incredibly intuitive. The ease of use is unparalleled and allows users across our entire Data Team to investigate our raw data.
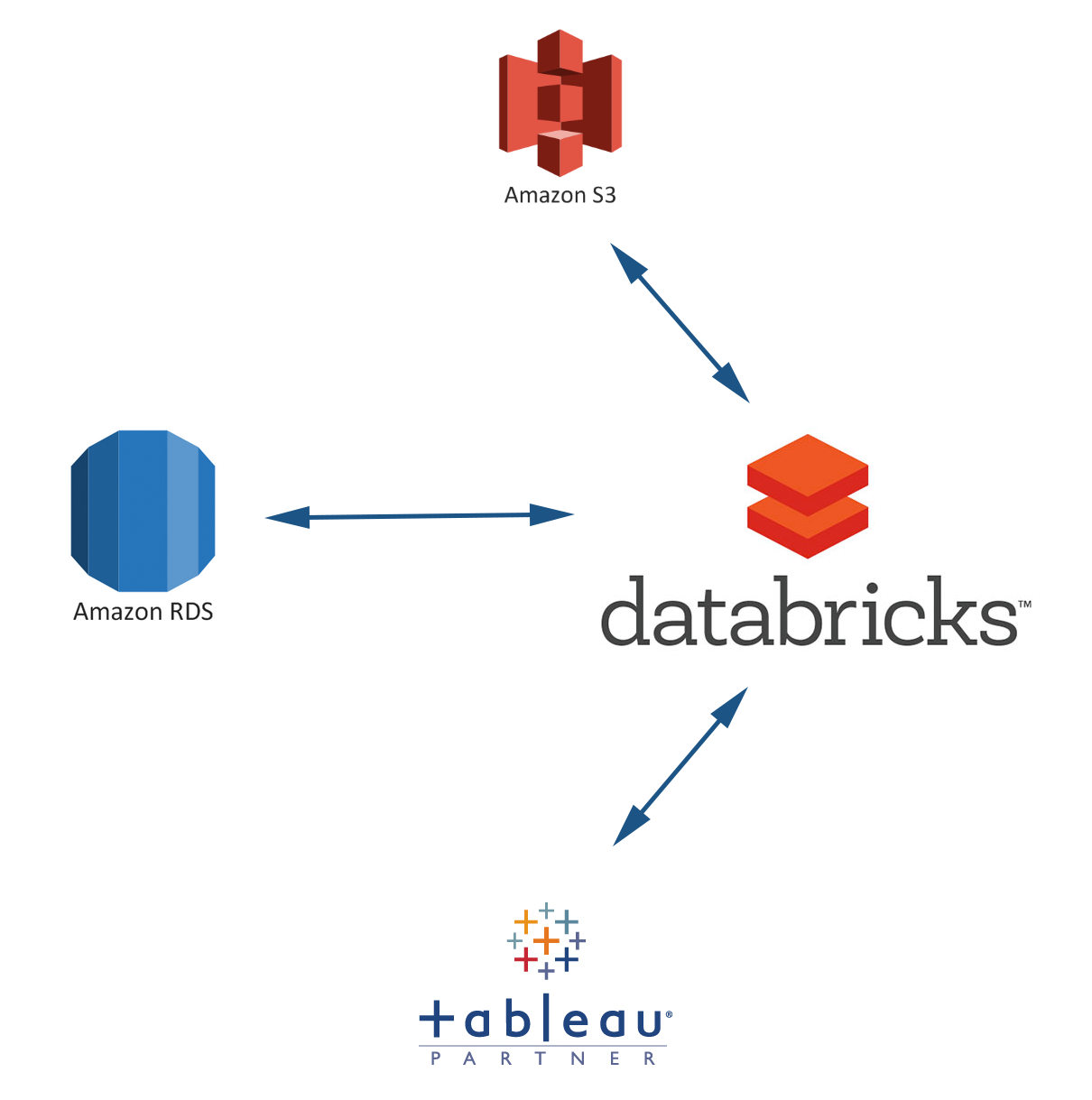
Architecture and Technical Details
Our immediate goal was to replicate our existing Hive-based ETL in SparkSQL, which turned out to be a breeze. SparkSQL can directly implement Hive libraries and utilizes a virtually identical syntax, so transferring our existing ETL was as simple as copy/paste and uploading the Hive CSV Serde. Soon after, Databricks released their native Spark CSV Serde, and we implemented it without issue. We also needed to extract these tables into Tableau, which Databricks again made simple. Databricks implements a Thrift server by default for JDBC calls, and Tableau has a SparkSQL connector that utilizes the JDBC. We needed to modify one setting here:
spark.sql.thriftServer.incrementalCollect = true
This tells the Thrift server that data should be sent in small increments rather than collecting all the data into the driver node and then pushing it out, which will cause the driver to run out of space quite quickly if you’re extracting a non-trivial amount of data. With that, replicating our ETL in Databricks was complete. We were now leveraging Databricks to process 100GB/day of raw CSV data.
Our next steps involved learning Scala/Spark and the various optimizations that can be made inside Spark, while also starting to integrate other data sources. We had an SQL query that was taking over 2 hours to complete, but the output was being saved to S3 for consumption by Databricks. The query took so long because it involved joining 11 tables together and building a lookup with 10 fields. While optimizations could’ve been made to the structure of the MySQL db or the query itself, we thought, why not do it in Databricks? We were able to reduce the query time from 2 hours down to less than 2 minutes; and again, since the SparkSQL syntax encompasses all the basic SQL commands, implementing the query was as easy as copy/paste (N.B. we needed to modify our AWS settings in order to get this to work). A simplified version of the code below:
import com.mysql.jdbc.Driver
// create database connection
val host = "Internal IP Address of mysql db (10.x.x.x)"
val port = "3306"
val user = "username"
val password = "password"
val dbName = "databaseName"
val dbURL = s"jdbc:mysql://$host:$port/$dbName?user=$user&password=$password"
//load table as a val
val table =
sqlContext
.read
.format("jdbc")
.options(
Map(
"url" -> s"$dbURL",
"dbtable" -> "dbName.tableToLoad",
"driver" -> "com.mysql.jdbc.Driver"))
.load()
//register as a temporary SparkSQL table
table.registerTempTable("tableName")
//run the query
val tableData =
sqlContext.sql("""
SELECT *
FROM tableName""")
We also receive and send out files on a daily basis via FTP. We need to download and store copies of these files, so we started downloading them to S3 using Databricks. This allowed us to further centralize our ETL in Databricks . A simplified version of the code below:
import org.apache.commons.net.ftp.FTPClient;
import org.apache.commons.net.ftp.FTPFile;
import org.apache.commons.net.ftp.FTPReply;
import java.io.File;
import java.io.FileOutputStream;
val ftpURL = "ftp.url.com"
val user = "username"
val pswd = "password"
val ftp = new FTPClient()
ftp.connect(ftpURL)
ftp.enterLocalPassiveMode()
ftp.login(user,pswd)
val folderPath = "pathToDownloadFrom"
val files = ftp.listFiles(s"/$folderPath").map(_.getName)
dbutils.fs.mkdirs(s"""/$savePath""")
val outputFile = new File(s"""/dbfs/$savePath/filename.txt""")
val output = new FileOutputStream(outputFile)
ftp.retrieveFile(s"/$folder/filename.txt", output)
output.close()
ftp.logout
We switched over from saving our processed data as CSV to Parquet. Parquet is columnar, which means that when you’re only using some of the columns in your data, it is able to ignore the other columns. This has massive speed gains when you have trillions of rows, and allows us to decrease time waiting for initial results. We try to keep our individual parquet files around 120MB in size, which is the default block size for Spark and allows the cluster to load data quickly (which we found to be a bottleneck when using small CSV files).
Consolidating our ETL steps into a single location has added benefits when we get to actually analyzing the data. We always try to stay on the cutting edge of machine learning and offline analysis techniques for identifying new user segments, which requires that we maintain a recent set of testable user data, while also being able to compare the output of new techniques to what we’re currently using. Being able to consolidate all of our data into a single platform has sped up our iteration process considerably, especially since this single platform includes the MLlib project.
Benefits and Lessons Learned
In the 1.5 years since implementing Databricks, we’ve been able to:
- Speed up our first-step ETL by ~4x
- Integrate mysql and ftp data sources directly into Databricks, and speed up those portions of the ETL by 100x
- Optimize our processed data for analysis
We have also learned a lot during this process. A few tips and lessons include:
- Store your data as Parquet files
- Leverage the processing power of Spark and implement any RDS ETL in Databricks via the JDBC
- Partition your data as granularly as possible while maintaining larger file sizes - loading data is slow, but processing is fast!
To learn more about how Sellpoints is using Databricks, read the case study.
A special thank you to Ivan Dejanovic for his edits and patience.