

Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Try this notebook in Databricks
This blog is the first blog in our “Genomics Analysis at Scale” series. In this series, we will demonstrate how the Databricks Unified Analytics Platform for Genomics enables customers to analyze population-scale genomic data. Starting from the output of our genomics pipeline, this series will provide a tutorial on using Databricks to run sample quality control, joint genotyping, cohort quality control, and advanced statistical genetics analyses.
Since the completion of the Human Genome Project in 2003, there has been an explosion in data fueled by a dramatic drop in the cost of DNA sequencing, from $3B1 for the first genome to under $1,000 today.
[1] The Human Genome Project was a $3B project led by the Department of Energy and the National Institutes of Health began in 1990 and completed in 2003.
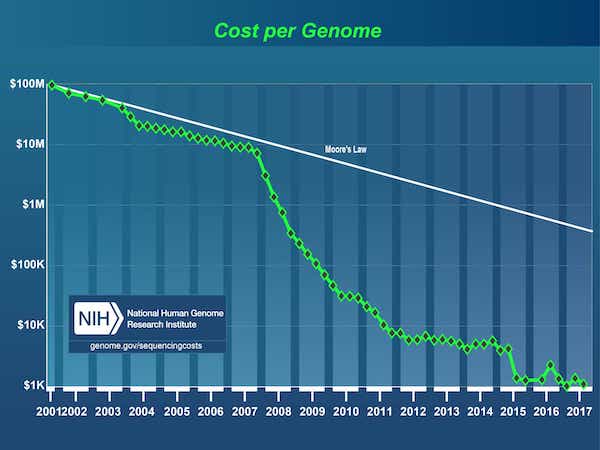
Source: DNA Sequencing Costs: Data
Consequently, the field of genomics has now matured to a stage where companies have started to do DNA sequencing at population-scale. However, sequencing the DNA code is only the first step, the raw data then needs to be transformed into a format suitable for analysis. Typically this is done by gluing together a series of bioinformatics tools with custom scripts and processing the data on a single node, one sample at a time, until we wind up with a collection of genomic variants. Bioinformatics scientists today spend the majority of their time building out and maintaining these pipelines. As genomic data sets have expanded into the petabyte scale, it has become challenging to answer even the following simple questions in a timely manner:
- How many samples have we sequenced this month?
- What is the total number of unique variants detected?
- How many variants did we see across different classes of variation?
Further compounding this problem, data from thousands of individuals cannot be stored, tracked nor versioned while also remaining accessible and queryable. Consequently, researchers often duplicate subsets of their genomic data when performing their analyses, causing the overall storage footprint and costs to escalate. In an attempt to alleviate this problem, today researchers employ a strategy of “data freezes”, typically between six months to two years, where they halt work on new data and instead focus on a frozen copy of existing data. There is no solution to incrementally build up analyses over shorter time frames, causing research progress to slow down.
There is a compelling need for robust software that can consume genomic data at industrial scale, while also retaining the flexibility for scientists to explore the data, iterate on their analytical pipelines, and derive new insights.
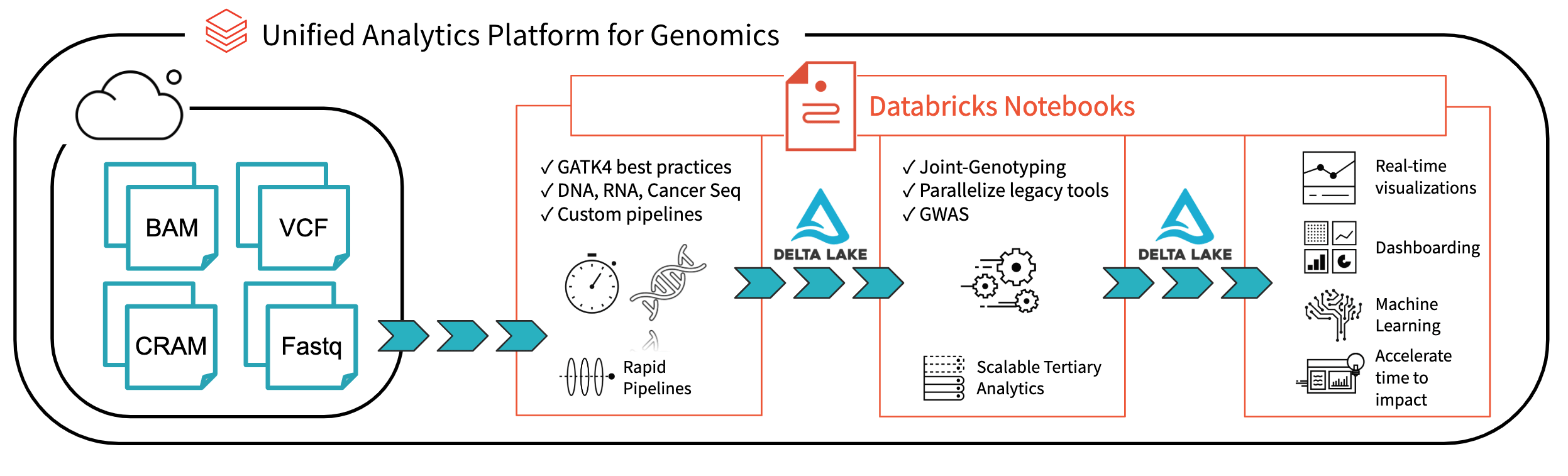
Fig 1. Architecture for end-to-end genomics analysis with Databricks
With Databricks Delta: A Unified Management System for Real-time Big Data Analytics, the Databricks platform has taken a major step towards solving the data governance, data access, and data analysis issues faced by researchers today. With Databricks Delta Lake, you can store all your genomic data in one place, and create analyses that update in real-time as new data is ingested. Combined with optimizations in our Unified Analytics Platform for Genomics (UAP4G) for reading, writing, and processing genomics file formats, we offer an end-to-end solution for genomics pipelines workflows. The UAP4G architecture offers flexibility, allowing customers to plug in their own pipelines and develop their own tertiary analytics. As an example, we’ve highlighted the following dashboard showing quality control metrics and visualizations that can be calculated and presented in an automated fashion and customized to suit your specific requirements.
https://www.youtube.com/watch?v=73fMhDKXykU
In the rest of this blog, we will walk through the steps we took to build the quality control dashboard above, which updates in real time as samples finish processing. By using a Delta-based pipeline for processing genomic data, our customers can now operate their pipelines in a way that provides real-time, sample-by-sample visibility. With Databricks notebooks (and integrations such as GitHub and MLflow) they can track and version analyses in a way that will ensure their results are reproducible. Their bioinformaticians can devote less time to maintaining pipelines and spend more time making discoveries. We see the UAP4G as the engine that will drive the transformation from ad-hoc analyses to production genomics on an industrial scale, enabling better insights into the link between genetics and disease.
Read Sample Data
Let’s start by reading variation data from a small cohort of samples; the following statement reads in data for a specific sampleId and saves it using the Databricks Delta format (in the delta_stream_output folder).
spark.read. \
format("parquet"). \
load("dbfs:/annotations_etl_parquet/sampleId=" + "SRS000030_SRR709972"). \
write. \
format("delta"). \
save(delta_stream_outpath)Note, the annotations_etl_parquet folder contains annotations generated from the 1000 genomes dataset stored in parquet format. The ETL and processing of these annotations were performed using Databricks’ Unified Analytics Platform for Genomics.
Start Streaming the Databricks Delta Table
In the following statement, we are creating the exomes Apache Spark DataFrame which is reading a stream (via readStream) of data using the Databricks Delta format. This is a continuously running or dynamic DataFrame, i.e. the exomes DataFrame will load new data as data is written into the delta_stream_output folder. To view the exomes DataFrame, we can run a DataFrame query to find the count of variants grouped by the sampleId.
# Read the stream of data
exomes = spark.readStream.format("delta").load(delta_stream_outpath)
# Display the data via DataFrame query
display(exomes.groupBy("sampleId").count().withColumnRenamed("count", "variants"))When executing the display statement, the Databricks notebook provides a streaming dashboard to monitor the streaming jobs. Immediately below the streaming job are the results of the display statement (i.e. the count of variants by sample_id).
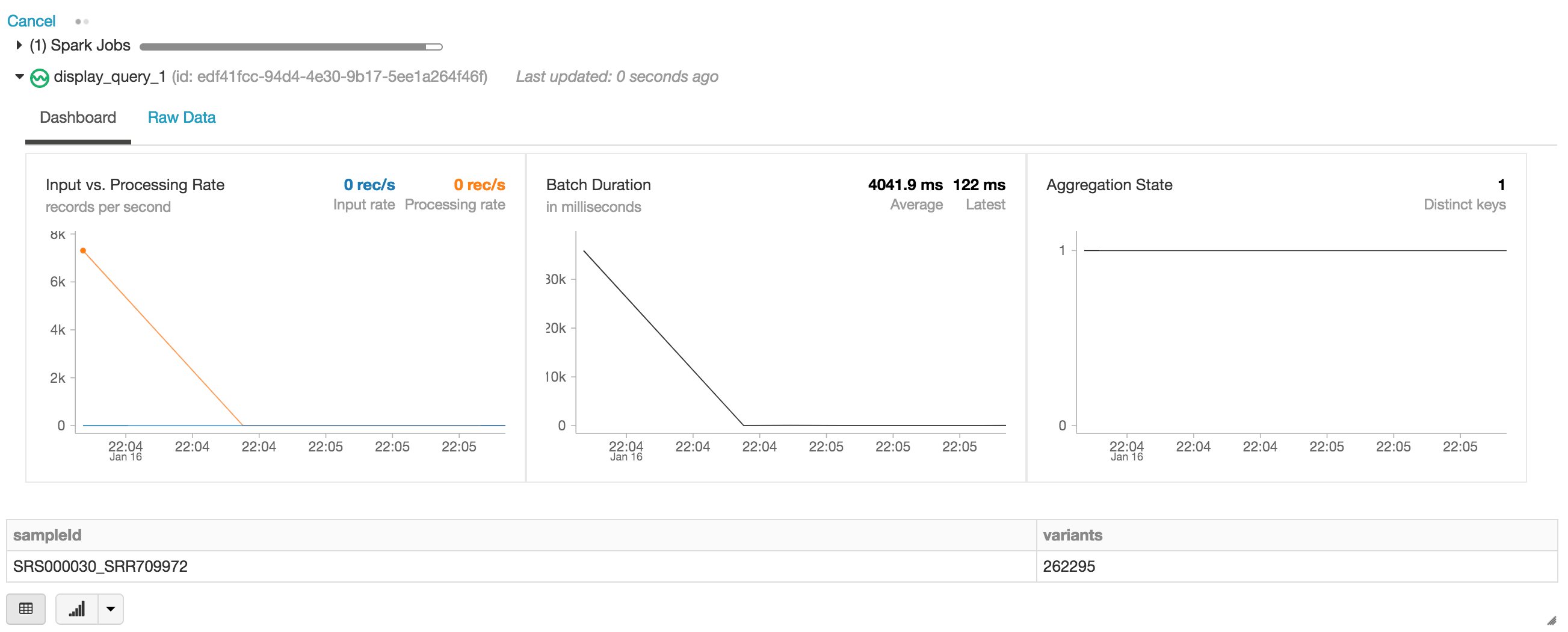
Let’s continue answering our initial set of questions by running other DataFrame queries based on our exomes DataFrame.
Single Nucleotide Variant Count
To continue the example, we can quickly calculate the number of single nucleotide variants (SNVs), as displayed in the following graph.
%sql
select referenceAllele, alternateAllele, count(1) as GroupCount
from snvs
group by referenceAllele, alternateAllele
order by GroupCount desc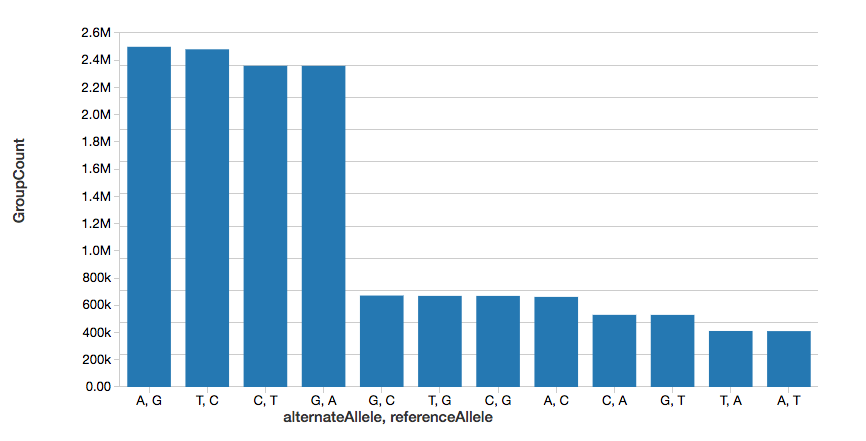
Note, the display command is part of the Databricks workspace that allows you to view your DataFrame using Databricks visualizations (i.e. no coding required).
Variant Count
Since we have annotated our variants with functional effects, we can continue our analysis by looking at the spread of variant effects we see. The majority of the variants detected flank regions that code for proteins, these are known as noncoding variants.
display(exomes.groupBy("mutationType").count())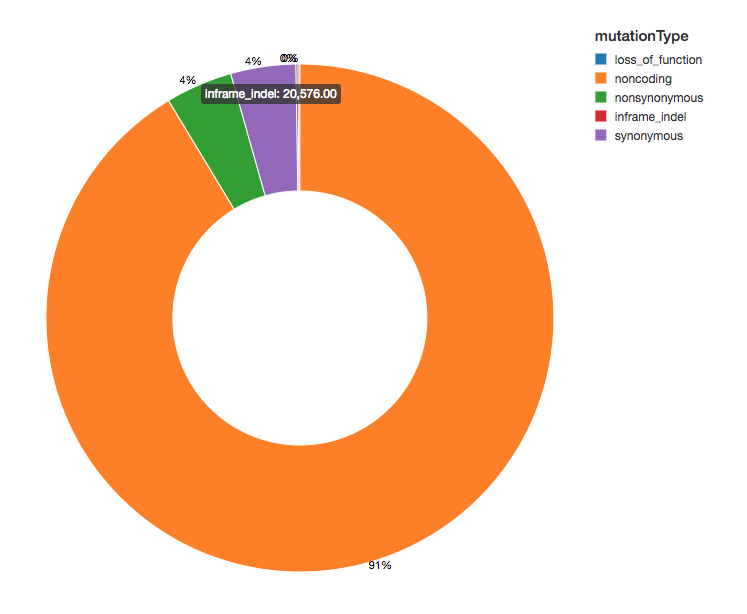
Amino Acid Substitution Heatmap
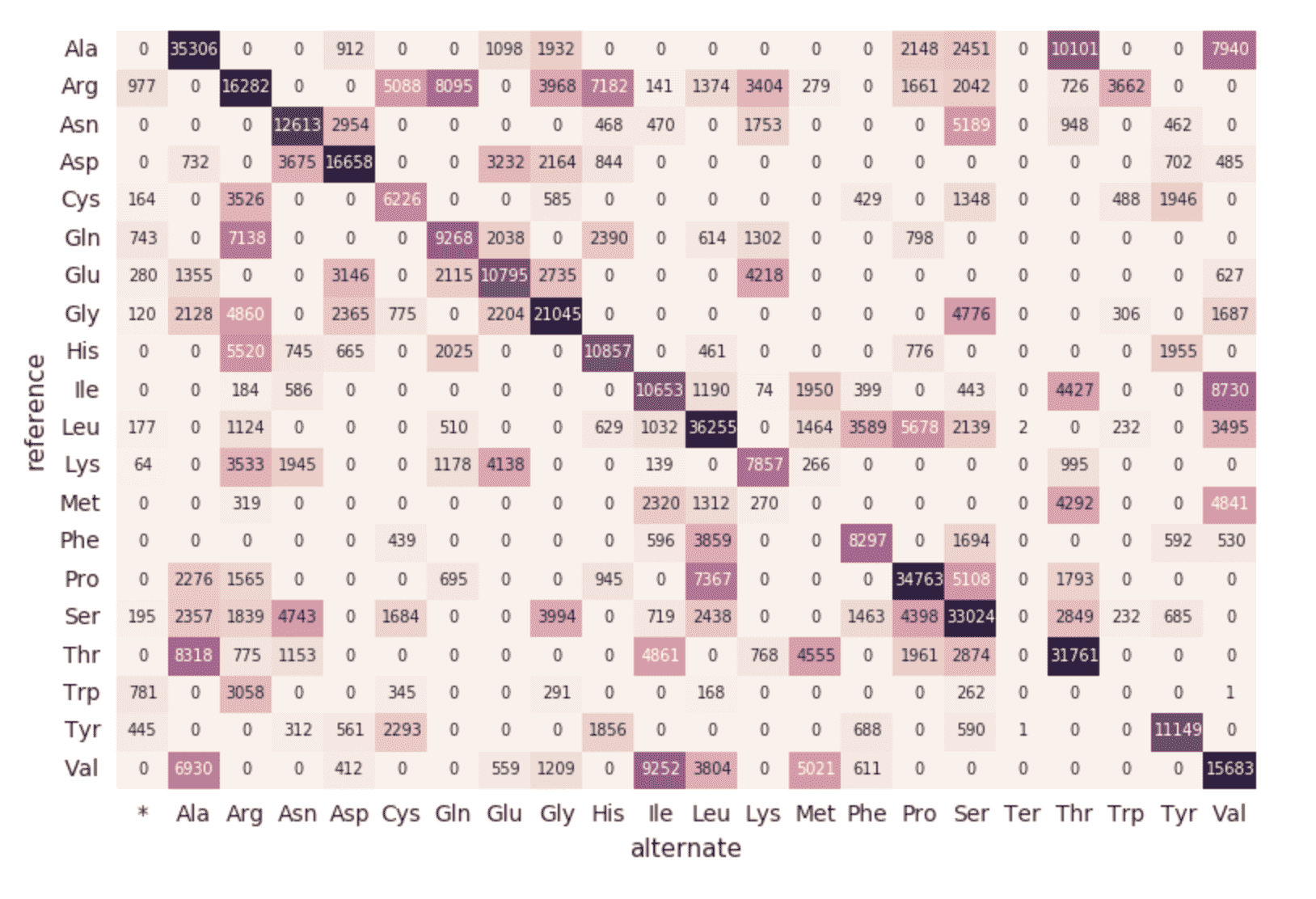
Continuing with our exomes DataFrame, let’s calculate the amino acid substitution counts with the following code snippet. Similar to the previous DataFrames, we will create another dynamic DataFrame (aa_counts) so that as new data is processed by the exomes DataFrame, it will subsequently be reflected in the amino acid substitution counts as well. We are also writing the data into memory (i.e. .format(“memory”)) and processed batches every 60s (i.e. trigger(processingTime=’60 seconds’)) so the downstream Pandas heatmap code can process and visualize the heatmap.
# Calculate amino acid substitution counts
coding = get_coding_mutations(exomes)
aa_substitutions = get_amino_acid_substitutions(coding.select("proteinHgvs"), "proteinHgvs")
aa_counts = count_amino_acid_substitution_combinations(aa_substitutions)
aa_counts. \
writeStream. \
format("memory"). \
queryName("amino_acid_substitutions"). \
outputMode("complete"). \
trigger(processingTime='60 seconds'). \
start()The following code snippet reads the preceding amino_acid_substitutions Spark table, determines the max count, creates a new Pandas pivot table from the Spark table, and then plots out the heatmap.
# Use pandas and matplotlib to build heatmap
amino_acid_substitutions = spark.read.table("amino_acid_substitutions")
max_count = amino_acid_substitutions.agg(fx.max("substitutions")).collect()[0][0]
aa_counts_pd = amino_acid_substitutions.toPandas()
aa_counts_pd = pd.pivot_table(aa_counts_pd, values='substitutions', index=['reference'], columns=['alternate'], fill_value=0)
fig, ax = plt.subplots()
with sns.axes_style("white"):
ax = sns.heatmap(aa_counts_pd, vmax=max_count*0.4, cbar=False, annot=True, annot_kws={"size": 7}, fmt="d")
plt.tight_layout()
display(fig)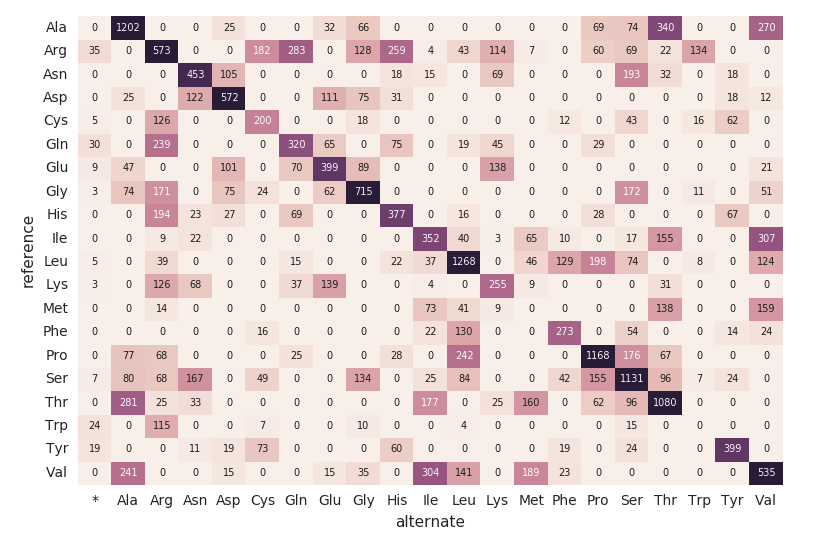
Migrating to a Continuous Pipeline
Up to this point, the preceding code snippets and visualizations represent a single run for a single sampleId. But because we’re using Structured Streaming and Databricks Delta, this code can be used (without any changes) to construct a production data pipeline that computes quality control statistics continuously as samples roll through our pipeline. To demonstrate this, we can run the following code snippet that will load our entire dataset.
import time
parquets = "dbfs:/databricks-datasets/genomics/annotations_etl_parquet/"
files = dbutils.fs.ls(parquets)
counter=0
for sample in files:
counter+=1
annotation_path = sample.path
sampleId = annotation_path.split("/")[4].split("=")[1]
variants = spark.read.format("parquet").load(str(annotation_path))
print("running " + sampleId)
if(sampleId != "SRS000030_SRR709972"):
variants.write.format("delta"). \
mode("append"). \
save(delta_stream_outpath)
time.sleep(10)As described in the earlier code snippets, the source of the exomes DataFrame are the files loaded into the delta_stream_output folder. Initially, we had loaded a set of files for a single sampleId (i.e., sampleId = “SRS000030_SRR709972”). The preceding code snippet now takes all of the generated parquet samples (i.e. parquets) and incrementally loads those files by sampleId into the same delta_stream_output folder. The following animated GIF shows the abbreviated output of the preceding code snippet.
https://www.youtube.com/watch?v=JPngSC5Md-Q
Visualizing your Genomics Pipeline
When you scroll back to the top of your notebook, you will notice that the exomes DataFrame is now automatically loading the new sampleIds. Because the structured streaming component of our genomics pipeline runs continuously, it processes data as soon as new files are loaded into the delta_stream_outputpath folder. By using the Databricks Delta format, we can ensure the transactional consistency of the data streaming into the exomes DataFrame.
https://www.youtube.com/watch?v=Q7KdPsc5mbY
As opposed to the initial creation of our exomes DataFrame, notice how the structured streaming monitoring dashboard is now loading data (i.e., the fluctuating “input vs. processing rate”, fluctuating “batch duration”, and an increase of distinct keys in the “aggregations state”). As the exomes DataFrame is processing, notice the new rows of sampleIds (and variant counts). This same action can also be seen for the associated group by mutation type query.
https://www.youtube.com/watch?v=sT179SCknGM
With Databricks Delta, any new data is transactionally consistent in each and every step of our genomics pipeline. This is important because it ensures your pipeline is consistent (maintains consistency of your data, i.e. ensures all of the data is “correct”), reliable (either the transaction succeeds or fails completely), and can handle real-time updates (the ability to handle many transactions concurrently and any outage of failure will not impact the data). Thus even the data in our downstream amino acid substitution map (which had a number of additional ETL steps) is refreshed seamlessly.
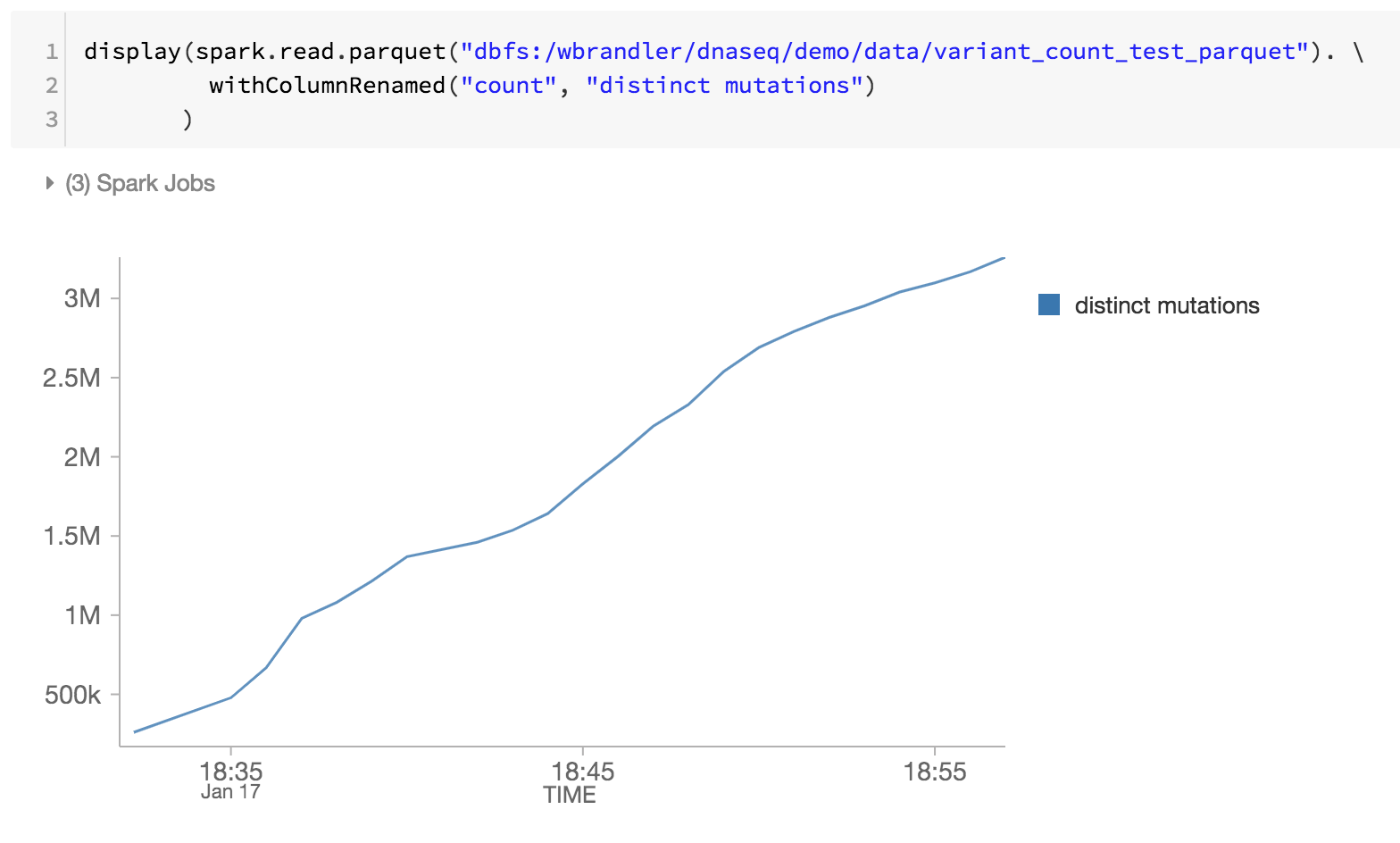
As the last step of our genomics pipeline, we are also monitoring the distinct mutations by reviewing the Databricks Delta parquet files within DBFS (i.e. increase of distinct mutations over time).
Summary
Using the foundation of the Databricks Unified Analytics Platform - with particular focus with Databricks Delta - bioinformaticians and researchers can apply distributed analytics with transactional consistency using Databricks Unified Analytics Platform for Genomics. These abstractions allow data practitioners to simplify genomics pipelines. Here we have created a genomic sample quality control pipeline that continuously processes data as new samples are processed, without manual intervention. Whether you are performing ETL or performing sophisticated analytics, your data will flow through your genomics pipeline rapidly and without disruption. Try it yourself today by downloading the Simplifying Genomics Pipelines at Scale with Databricks Delta notebook.
Get Started Analyzing Genomics at Scale:
- Read our Unified Analytics for Genomics solution guide
- Download the Simplifying Genomics Pipelines at Scale with Databricks Delta notebook
- Sign-up for a free trial of Databricks Unified Analytics for Genomics
Acknowledgments
Thanks to Yongsheng Huang and Michael Ortega for their contributions.
Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.