Today, we are thrilled to announce that Delta Live Tables (DLT) is generally available (GA) on the Amazon AWS and Microsoft Azure clouds, and publicly available on Google Cloud! In this blog post, we explore how DLT is helping data engineers and analysts in leading companies easily build production-ready streaming or batch pipelines, automatically manage infrastructure at scale, and deliver a new generation of data, analytics, and AI applications.
Customers win with simple streaming and batch ETL on the Lakehouse
Processing streaming and batch workloads for ETL is a fundamental initiative for analytics, data science and ML workloads – a trend that is continuing to accelerate given the vast amount of data that organizations are generating. But processing this raw, unstructured data into clean, documented, and trusted information is a critical step before it can be used to drive business insights. We’ve learned from our customers that turning SQL queries into production ETL pipelines typically involves a lot of tedious, complicated operational work. Even at a small scale, the majority of a data engineer’s time is spent on tooling and managing infrastructure rather than transformation. We also learned from our customers that observability and governance were extremely difficult to implement and, as a result, often left out of the solution entirely. This led to spending lots of time on undifferentiated tasks and led to data that was untrustworthy, not reliable, and costly.
This is why we built Delta LiveTables, the first ETL framework that uses a simple declarative approach to building reliable data pipelines and automatically managing your infrastructure at scale so data analysts and engineers can spend less time on tooling and focus on getting value from data. DLT allows data engineers and analysts to drastically reduce implementation time by accelerating development and automating complex operational tasks.
Delta Live Tables is already powering production use cases at leading companies around the globe. From startups to enterprises, over 400 companies including ADP, Shell, H&R Block, Jumbo, Bread Finance, JLL and more have used DLT to power the next generation of self-served analytics and data applications:
- ADP: “At ADP, we are migrating our human resource management data to an integrated data store on the Lakehouse. Delta Live Tables has helped our team build in quality controls, and because of the declarative APIs, support for batch and real-time using only SQL, it has enabled our team to save time and effort in managing our data.” - Jack Berkowitz, Chief Data Officer at ADP
- Audantic: “Our goal is to continue to leverage machine learning to develop innovative products that expand our reach into new markets and geographies. Databricks is a foundational part of this strategy that will help us get there faster and more efficiently. Delta Live Tables is enabling us to do some things on the scale and performance side that we haven’t been able to do before - with an 86% reduction in time-to-market. We now run our pipelines on a daily basis compared to a weekly or even monthly basis before — that's an order of magnitude improvement.” - Joel Lowery, Chief Information Officer at Audantic
- Shell: “At Shell, we are aggregating all our sensor data into an integrated data store. Delta Live Tables has helped our teams save time and effort in managing data at [the multi-trillion-record scale] and continuously improving our AI engineering capability. With this capability augmenting the existing lakehouse architecture, Databricks is disrupting the ETL and data warehouse markets, which is important for companies like ours. We are excited to continue to work with Databricks as an innovation partner.” - Dan Jeavons, General Manager Data Science at Shell
- Bread Finance: "Delta Live Tables enables collaboration and removes data engineering resource blockers, allowing our analytics and BI teams to self-serve without needing to know Spark or Scala. In fact, one of our data analysts -- with no prior Databricks or Spark experience -- was able to build a DLT pipeline to turn file streams on S3 into usable exploratory datasets within a matter of hours using mostly SQL." - Christina Taylor, Senior Data Engineer at Bread Finance
Modern software engineering for ETL processing
DLT allows analysts and data engineers to easily build production-ready streaming or batch ETL pipelines in SQL and Python. It simplifies ETL development by uniquely capturing a declarative description of the full data pipelines to understand dependencies live and automate away virtually all of the inherent operational complexity. With DLT, engineers can concentrate on delivering data rather than operating and maintaining pipelines, and take advantage of key benefits:
- Accelerate ETL development: Unlike solutions that require you to manually hand-stitch fragments of code to build end-to-end pipelines, DLT makes it possible to declaratively express entire data flows in SQL and Python. In addition, DLT natively enables modern software engineering best practices like the ability to develop in environment(s) separate from production, the ability to easily test it before deploying, deploy and manage environments using parameterization, unit testing and documentation. As a result, you can simplify the development, testing, deployment, operations and monitoring of ETL pipelines with first-class constructs for expressing transformations, CI/CD, SLAs and quality expectations, and seamlessly handling batch and streaming in a single API.
- Automatically manage infrastructure: DLT was built from the ground-up to automatically manage your infrastructure and automate complex and time-consuming activities. Sizing clusters for optimal performance given changing, unpredictable data volumes can be challenging and lead to overprovisioning. DLT automatically scales compute to meet performance SLAs by providing the user with the option to set the minimum and maximum number of instances and let DLT size up the cluster according to cluster utilization. In addition, tasks like orchestration, error handling and recovery, and performance optimization are all handled automatically. With DLT, you can focus on data transformation instead of operations.
- Data confidence: Deliver reliable data with built-in quality controls, testing, monitoring and enforcement to ensure accurate and useful BI, Data Science, and ML. DLT makes it easy to create trusted data sources by including first-class support for data quality management and monitoring tools using a feature called Expectations. Expectations help prevent bad data from flowing into tables, track data quality over time, and provide tools to troubleshoot bad data with granular pipeline observability so you get a high-fidelity lineage diagram of your pipeline, track dependencies, and aggregate data quality metrics across all of your pipelines.
- Simplified batch and streaming: Provide the freshest/up-to-date data for apps with data self-optimized and auto-scaling data pipelines for batch or streaming processing and choose optimal cost-performance. Unlike other products that force you to deal with streaming and batch workloads separately, DLT supports any type of data workload with a single API so data engineers and analysts alike can build cloud-scale data pipelines faster and without needing to have advanced data engineering skills.
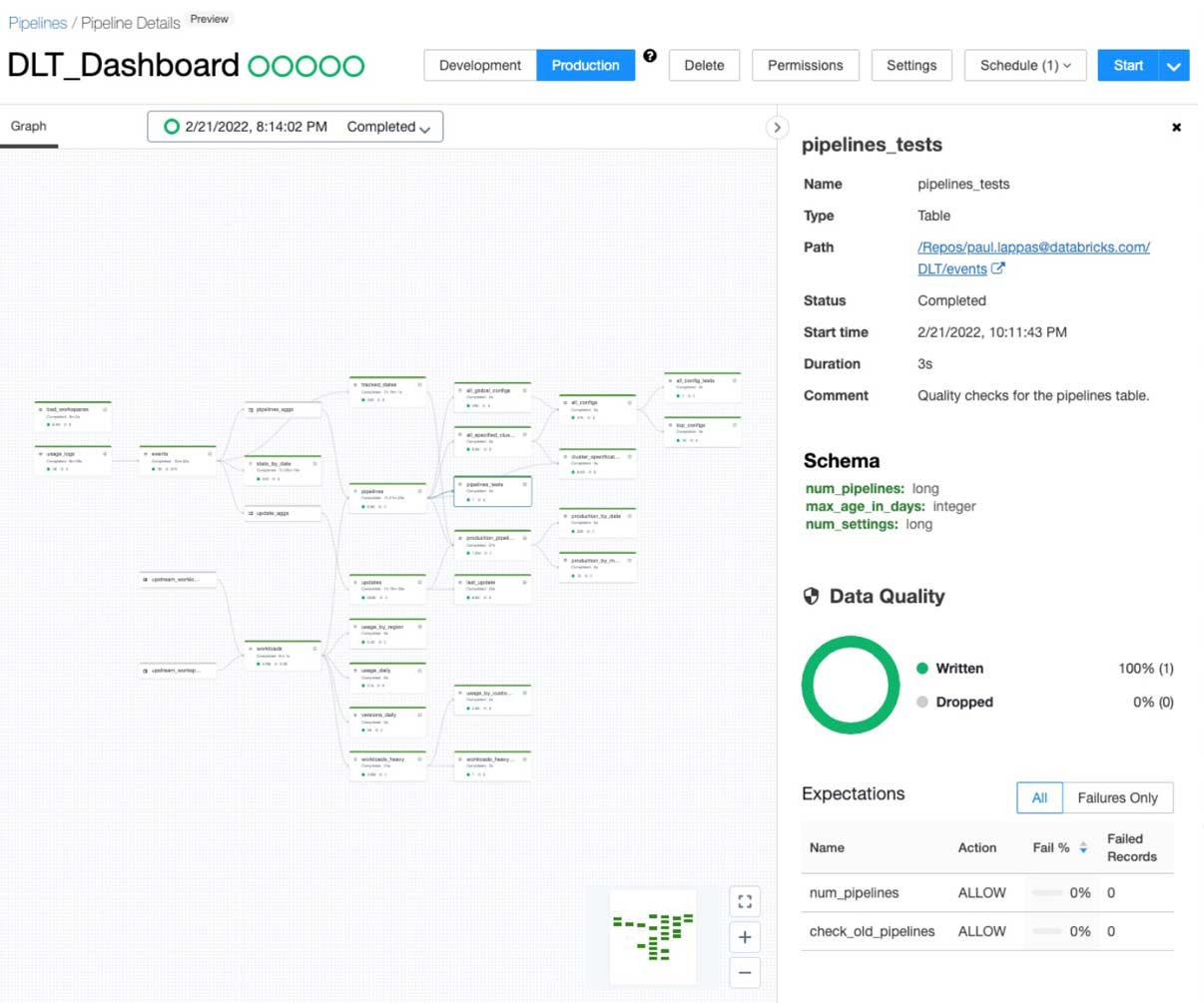
Since the preview launch of DLT, we have enabled several enterprise capabilities and UX improvements. We have extended our UI to make it easier to schedule DLT pipelines, view errors, manage ACLs, improved table lineage visuals, and added a data quality observability UI and metrics. In addition, we have released support for Change Data Capture (CDC) to efficiently and easily capture continually arriving data, as well as launched a preview of Enhanced Auto Scaling that provides superior performance for streaming workloads.
Get started with Delta Live Tables on the Lakehouse
Watch the demo below to discover the ease of use of DLT for data engineers and analysts alike:
If you already are a Databricks customer, simply follow the guide to get started. Read the release notes to learn more about what’s included in this GA release. If you are not an existing Databricks customer, sign up for a free trial and you can view our detailed DLT Pricing here.
What's next
Sign up for our Delta Live Tables Webinar with Michael Armbrust and JLL on April 14th to dive in and learn more about Delta Live Tables at Databricks.com.



