Blog
Featured Story![Databricks Lakebase is generally available]()

Product
February 3, 2026/5 min read
Databricks Lakebase is now Generally Available
What's new![Knowledge Assistant GA]()
![State of AI Agents]()

Product
January 27, 2026/3 min read
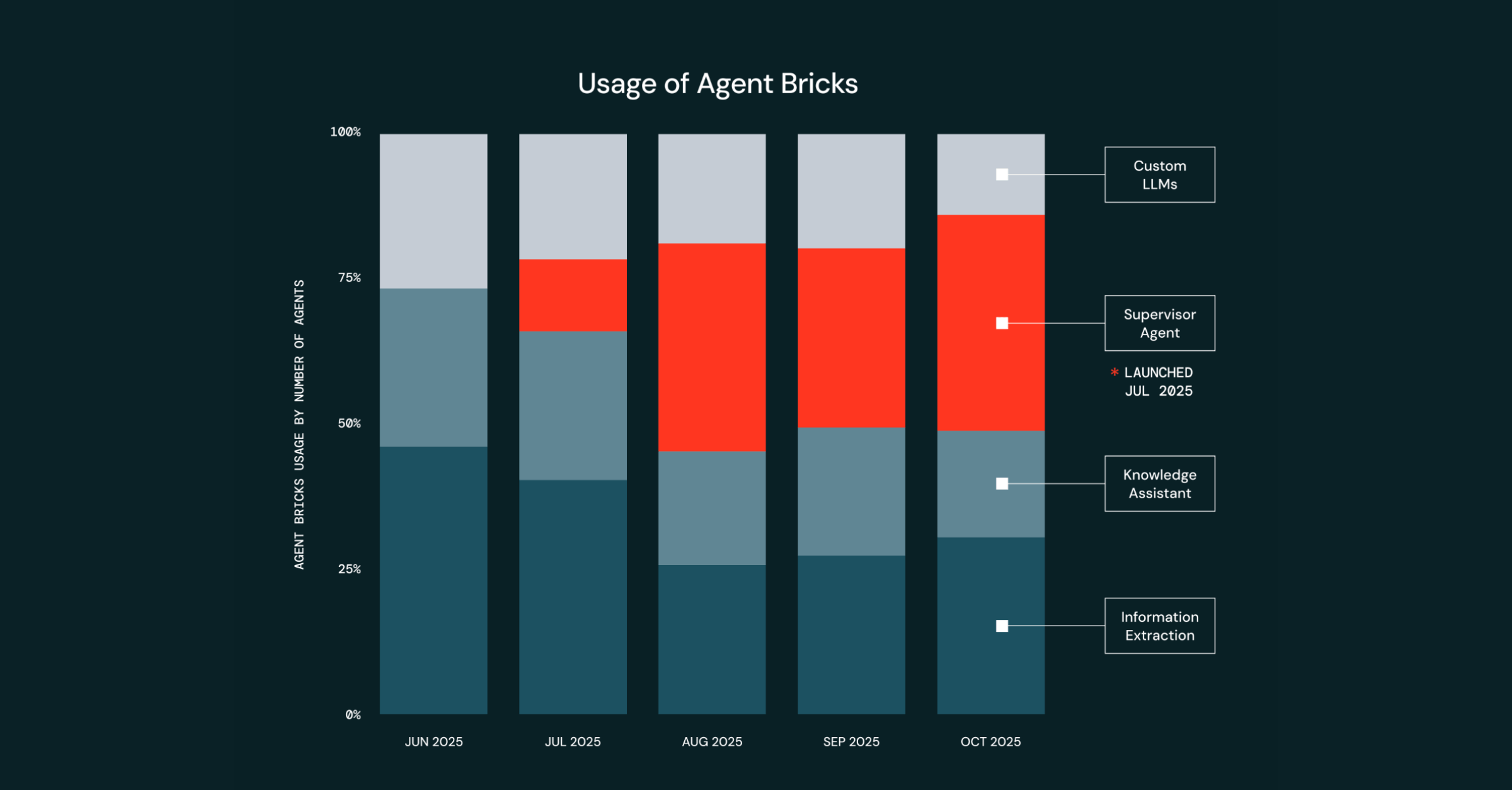
Agent Bricks Knowledge Assistant Is Now Generally Available: Turning Enterprise Knowledge into Answers
Insights
January 27, 2026/3 min read
Enterprise AI Agent Trends: Top Use Cases, Governance + Evaluations and More
Recent posts

Partners
February 7, 2026/8 min read
SAP and Salesforce Data Integration for Supplier Analytics on Databricks

Product
February 6, 2026/14 min read
How to Build Production-Ready Genie Spaces, and Build Trust Along the Way
Announcements
February 6, 2026/5 min read
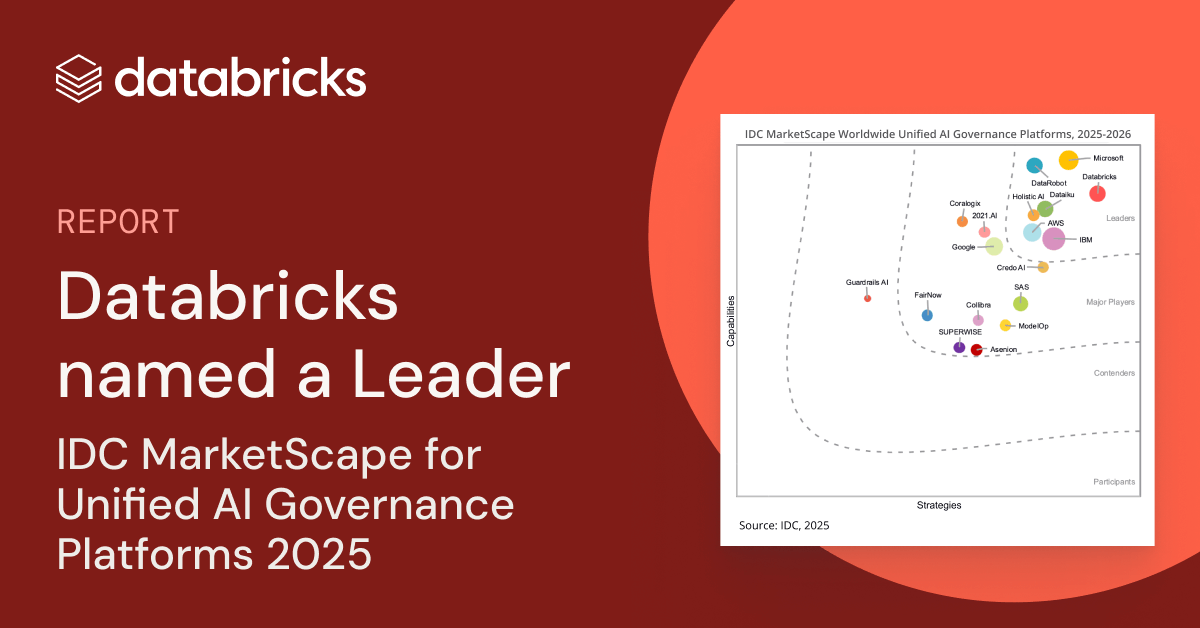
Databricks Named a Leader in the IDC MarketScape: Worldwide Unified AI Governance Platforms 2025-2026 Vendor Assessment
Product
February 5, 2026/10 min read
Tutorial: 3 Free Databricks Analytics Projects You Can Do In An Afternoon
Solutions
February 5, 2026/12 min read
From Data to Dialogue: A Best Practices Guide for Building High-Performing Genie Spaces

Healthcare & Life Sciences
February 4, 2026/4 min read
Accelerating Drug Discovery: From FASTA Files to GenAI Insights on Databricks

Data Strategy
February 3, 2026/9 min read
Delta Lake Explained: Boost Data Reliability in Cloud Storage

Engineering
February 3, 2026/16 min read
Self-Optimizing Football Chatbot Guided by Domain Experts on Databricks

Mosaic Research
February 3, 2026/9 min read
MemAlign: Building Better LLM Judges From Human Feedback With Scalable Memory

Data Leader
February 2, 2026/4 min read
Infrastructure & Strategies Driving the Next Wave of Enterprise AI




Data Intelligence for All

Never miss a Databricks post
Subscribe to our blog and get the latest posts delivered to your inbox