Databricks Reference Applications
by Vida Ha
At Databricks, we are often asked how to go beyond the basic Apache Spark tutorials and start building real applications with Spark. As a result, we are developing reference applications on github to demonstrate that. We believe this is a great way to learn Spark, and we plan on incorporating more features of Spark into the applications over time. We also hope to highlight any technologies that are compatible with Spark and include best practices.
Log Analyzer Application
Our first reference application is log analysis with Spark. Logs are a large and common data set that contain a rich set of information. Log data can be used for monitoring web servers, improving business and customer intelligence, building recommendation systems, preventing fraud, and much more. Spark is a wonderful tool to use on logs - Spark can process logs faster than Hadoop MapReduce, it is easy to code so we can compute many statistics with ease, and many of Spark’s libraries can be used on log data. Also, Spark SQL can be used for querying logs using familiar SQL syntax and Spark Streaming can be used to provide real-time logs analysis.
The log analysis reference application is broken down into sections with detailed explanations and small code examples to demonstrate various features of Spark. We start off with a gentle example of processing historical log data using standalone Spark, then cover how to do the same analysis with Spark SQL, before covering Spark Streaming. Along the way, we highlight any caveats or recommended best practices for using Spark - such as how to refactor your code for reuse between the batch and streaming libraries. The examples are self-contained and emphasize one aspect of Spark at a time, so you can experiment and modify the examples to deepen your understanding of that topic.
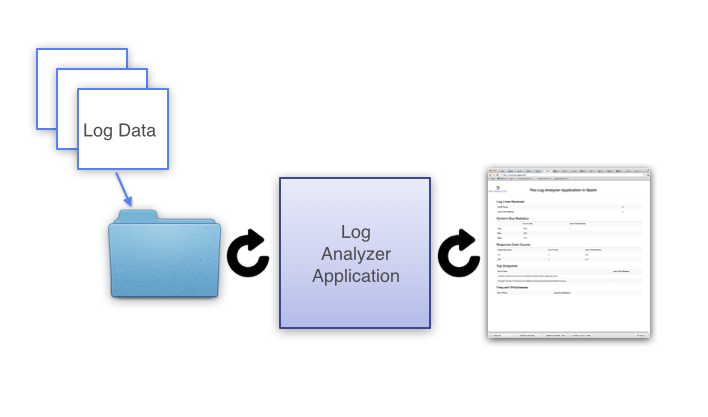
Code from the examples is combined to form a sample end-to-end application as shown in the diagram above. For now, the final application is an MVP log analysis streaming application. The application monitors a directory for new log input files, and when it receives one - the file is processed. Spark Streaming is used to compute statistics for the last N time as well as all of time, and refreshed. Each time interval, an html file is written which reflects the latest log data in the folder.
Twitter Streaming Language Classifier
The second reference application is a popular demo that the Databricks team has given, and was video taped here:
This application demonstrates the following:
- Collecting Twitter data using Spark Streaming.
- Examine the tweets using Spark SQL and training a Kmeans clustering model for classifying the language of a tweet using Spark MLLib.
- Applying the model in realtime using Spark MLLib and Spark Streaming.
Now, we are releasing the code so you can run the demo yourself and walk through how it works.
Get Started with the Databricks Reference Applications
These applications are just a start though - we will add more and improve our reference applications over time. Please follow these steps to get started:
- Read the documentation online in book format.
- Go to our github repo to view the code for the reference applications.
- Please open an issue on github with any useful feedback about our reference applications.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.