Announcing SparkR: R on Apache Spark
I am excited to announce that the upcoming Apache Spark 1.4 release will include SparkR, an R package that allows data scientists to analyze large datasets and interactively run jobs on them from the R shell.
R is a popular statistical programming language with a number of extensions that support data processing and machine learning tasks. However, interactive data analysis in R is usually limited as the runtime is single-threaded and can only process data sets that fit in a single machine’s memory. SparkR, an R package initially developed at the AMPLab, provides an R frontend to Apache Spark and using Spark’s distributed computation engine allows us to run large scale data analysis from the R shell.
Project History
The SparkR project was initially started in the AMPLab as an effort to explore different techniques to integrate the usability of R with the scalability of Spark. Based on these efforts, an initial developer preview of SparkR was first open sourced in January 2014. The project was then developed in the AMPLab for the next year and we made many performance and usability improvements through open source contributions to SparkR. SparkR was recently merged into the Apache Spark project and will be released as an alpha component of Apache Spark in the 1.4 release.
SparkR DataFrames
The central component in the SparkR 1.4 release is the SparkR DataFrame, a distributed data frame implemented on top of Spark. Data frames are a fundamental data structure used for data processing in R and the concept of data frames has been extended to other languages with libraries like Pandas etc. Projects like dplyr have further simplified expressing complex data manipulation tasks on data frames. SparkR DataFrames present an API similar to dplyr and local R data frames but can scale to large data sets using support for distributed computation in Spark.
The following example shows some of the aspects of the DataFrame API in SparkR. (You can see the full example at https://gist.github.com/shivaram/d0cd4aa5c4381edd6f85)
Benefits of Spark integration
In addition to having an easy to use API, SparkR inherits many benefits from being tightly integrated with Spark. These include: Data Sources API: By tying into Spark SQL’s data sources API SparkR can read in data from a variety of sources include Hive tables, JSON files, Parquet files etc. Data Frame Optimizations: SparkR DataFrames also inherit all of the optimizations made to the computation engine in terms of code generation, memory management. For example, the following chart compares the runtime performance of running group-by aggregation on 10 million integer pairs on a single machine in R, Python and Scala (it uses the same dataset as https://www.databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html). From the graph we can see that using the optimizations in the computation engine makes SparkR performance similar to that of Scala / Python. 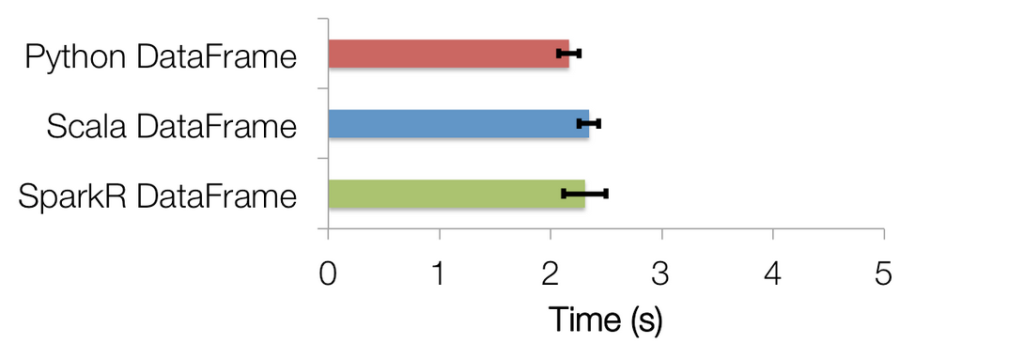 Scalability to many cores and machines: Operations executed on SparkR DataFrames get automatically distributed across all the cores and machines available on the Spark cluster. As a result SparkR DataFrames can be used on terabytes of data and run on clusters with thousands of machines.
Scalability to many cores and machines: Operations executed on SparkR DataFrames get automatically distributed across all the cores and machines available on the Spark cluster. As a result SparkR DataFrames can be used on terabytes of data and run on clusters with thousands of machines.
Looking forward
We have many other features planned for SparkR in upcoming releases: these include support for high level machine learning algorithms and making SparkR DataFrames a stable component of Spark. The SparkR package represents the work of many contributors from various organizations including AMPLab, Databricks, Alteryx and Intel. We’d like to thank our contributors and users who tried out early versions of SparkR and provided feedback. If you are interested in SparkR, do check out our talks at the upcoming Spark Summit 2015.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.