Improve your RAG application response quality with real-time structured data
by Mani Parkhe, Aakrati Talati, Sue Ann Hong, Craig Wiley, Chenen Liang and Mingyang Ge
Retrieval Augmented Generation (RAG) is an efficient mechanism to provide relevant data as context in Gen AI applications. Most RAG applications typically use vector indexes to search for relevant context from unstructured data such as documentation, wikis, and support tickets. Yesterday, we announced Databricks AI Search Public Preview that helps with exactly that. However, Gen AI response quality can be enhanced by augmenting these text-based contexts with relevant and personalized structured data. Imagine a Gen AI tool on a retail website where customers inquire, "Where's my recent order?" This AI must understand that the query is about a specific purchase, then gather up-to-date shipment information for line items, before using LLMs to generate a response. Developing these scalable applications demands substantial work, integrating technologies for handling both structured and unstructured data with Gen AI capabilities.
We are excited to announce the public preview of Databricks Feature & Function Serving, a low latency real-time service designed to serve structured data from the Databricks Data Intelligence Platform. You can instantly access pre-computed ML features as well as perform real-time data transformations by serving any Python function from Unity Catalog. The retrieved data can then be used in real-time rule engines, classical ML, and Gen AI applications.
Using Feature and Function Serving (AWS)(Azure) for structured data in coordination with Databricks AI Search (AWS)(Azure) for unstructured data significantly simplifies productionalization of Gen AI applications. Users can build and deploy these applications directly in Databricks and rely on existing data pipelines, governance, and other enterprise features. Databricks customers across various industries are using these technologies along with open source frameworks to build powerful Gen AI applications such as the ones described in the table below.
| Industry | Use Case |
| Retail |
|
| Education |
|
| Financial Services |
|
| Travel and Hospitality |
|
| Healthcare and Life Sciences |
|
| Insurance |
|
| Technology and Manufacturing |
|
| Media and Entertainment |
|
Serving structured data to RAG applications
To demonstrate how structured data can help enhance the quality of a Gen AI application, we use the following example for a travel planning chatbot. The example shows how user preferences (example: "ocean view" or "family friendly") can be paired with unstructured information sourced about hotels to search for hotel matches. Typically hotel prices dynamically change based on demand and seasonality. A price calculator built into the Gen AI application ensures that the recommendations are within the user's budget. The Gen AI application that powers the bot uses Databricks AI Search and Databricks Feature and Function Serving as building blocks to serve the necessary personalized user preferences and budget and hotel information using LangChain's agents API.
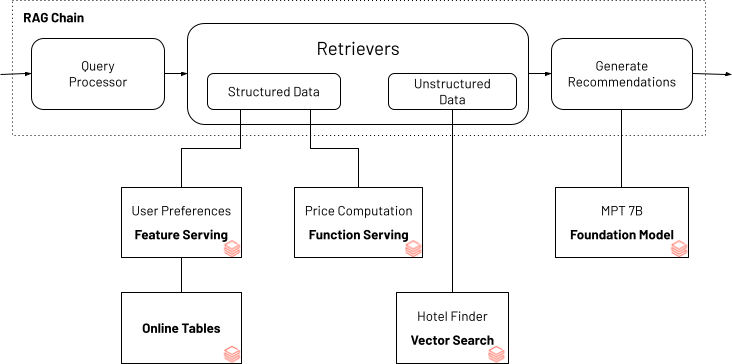
*Travel planning bot that accounts for user preference and budget
You can find the complete notebook for this RAG Chain application as depicted above. This application can be run locally within the notebook or deployed as an endpoint accessible by a chatbot user interface.
Access your data and functions as real-time endpoints
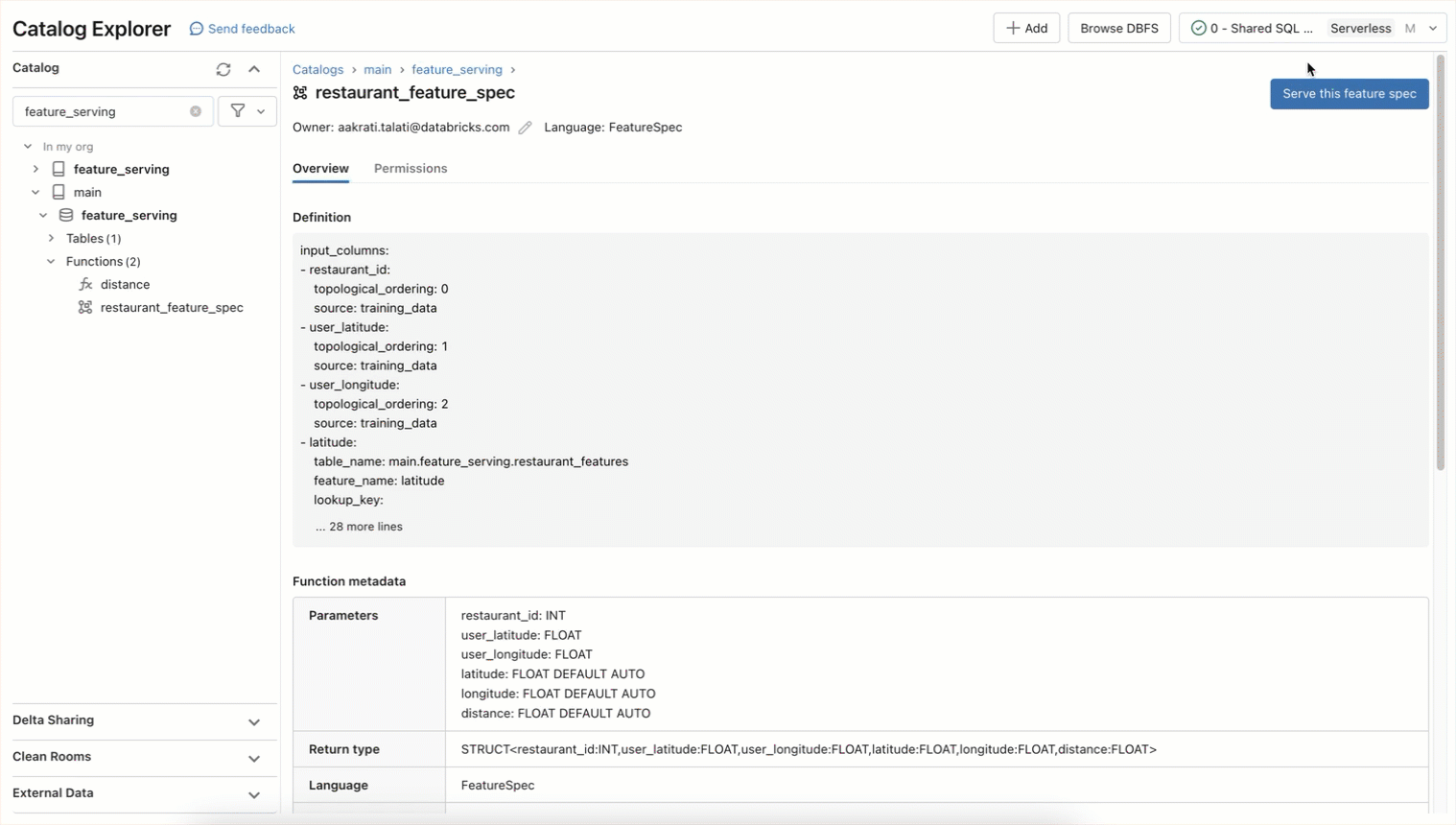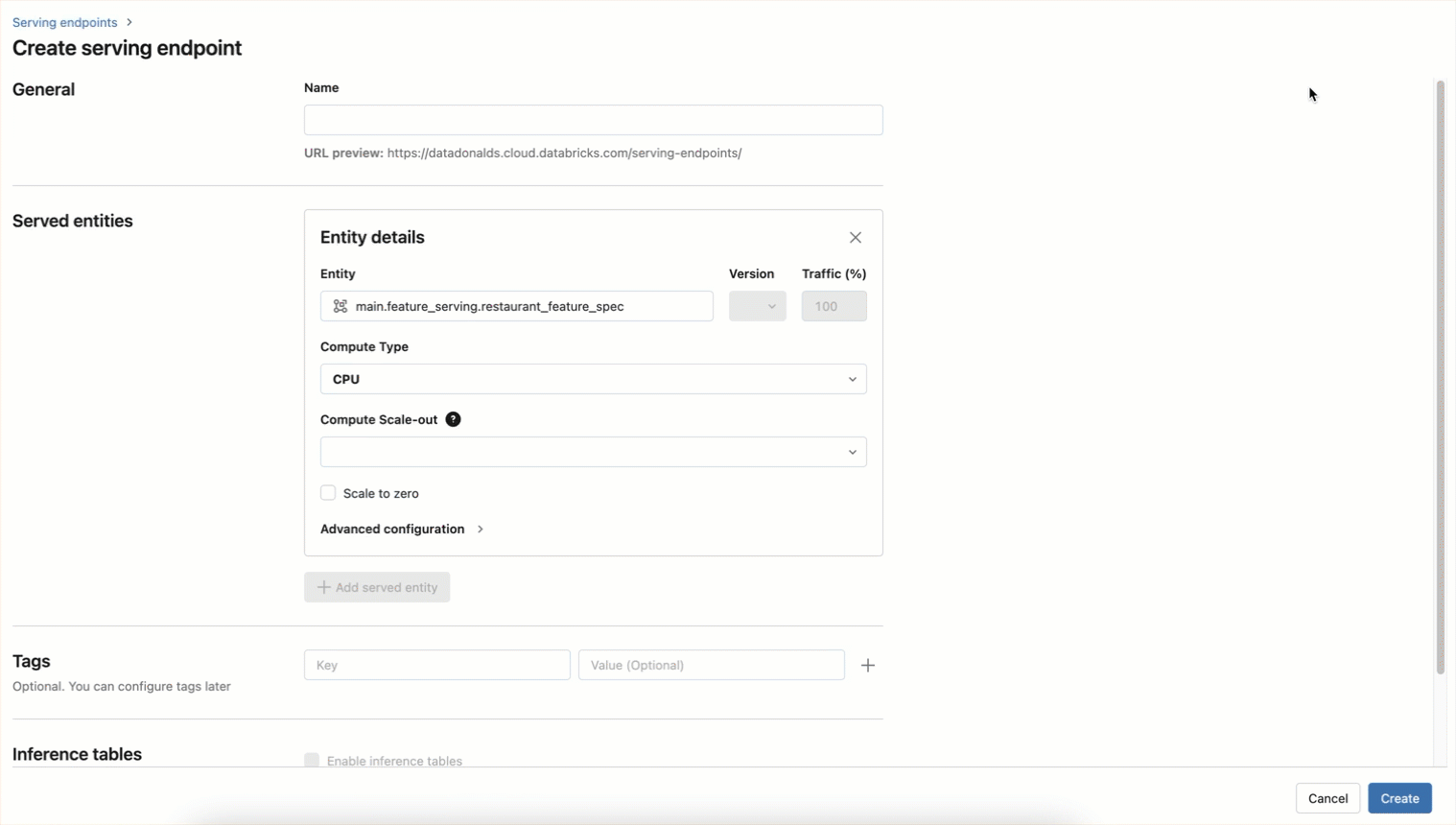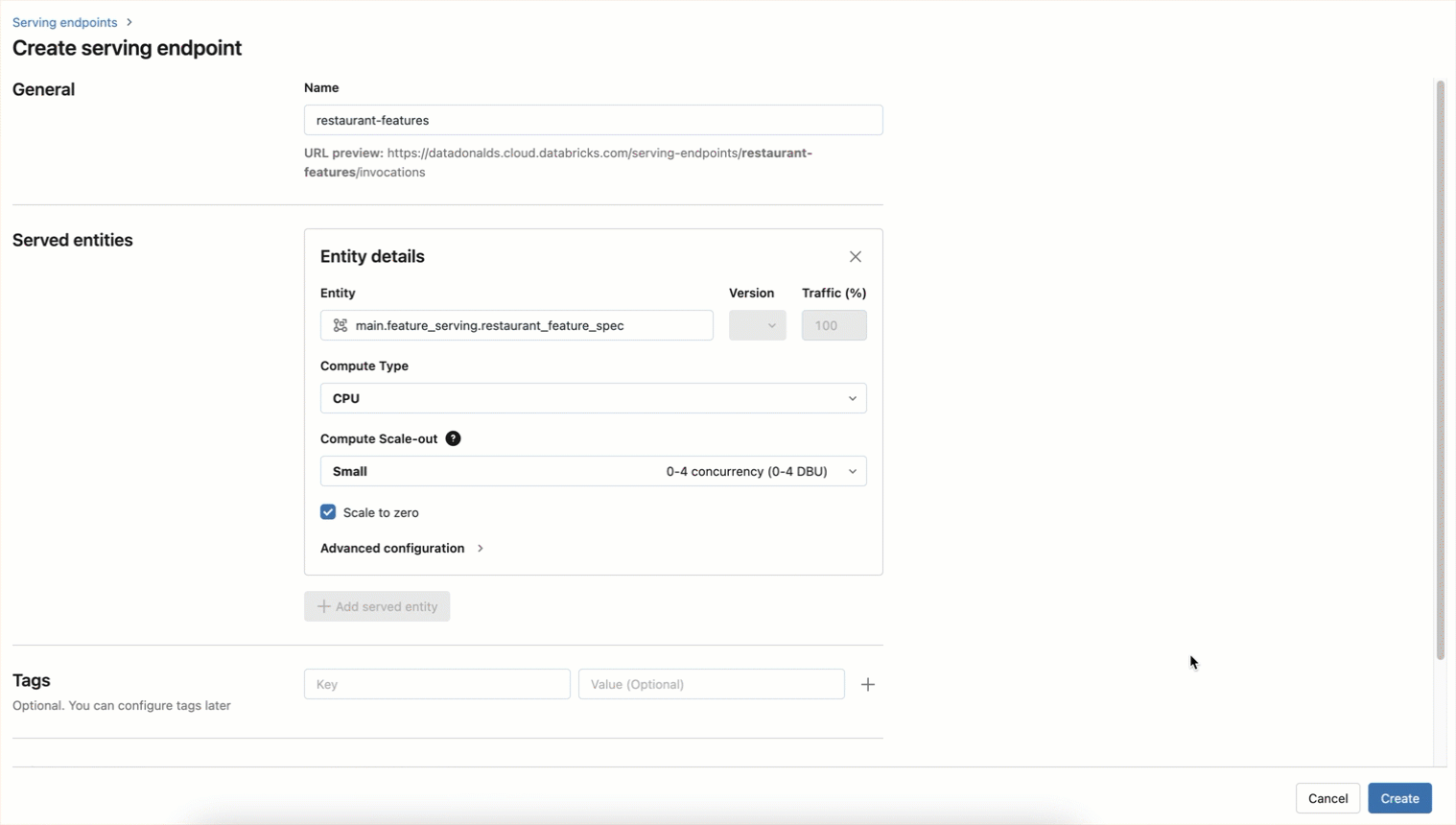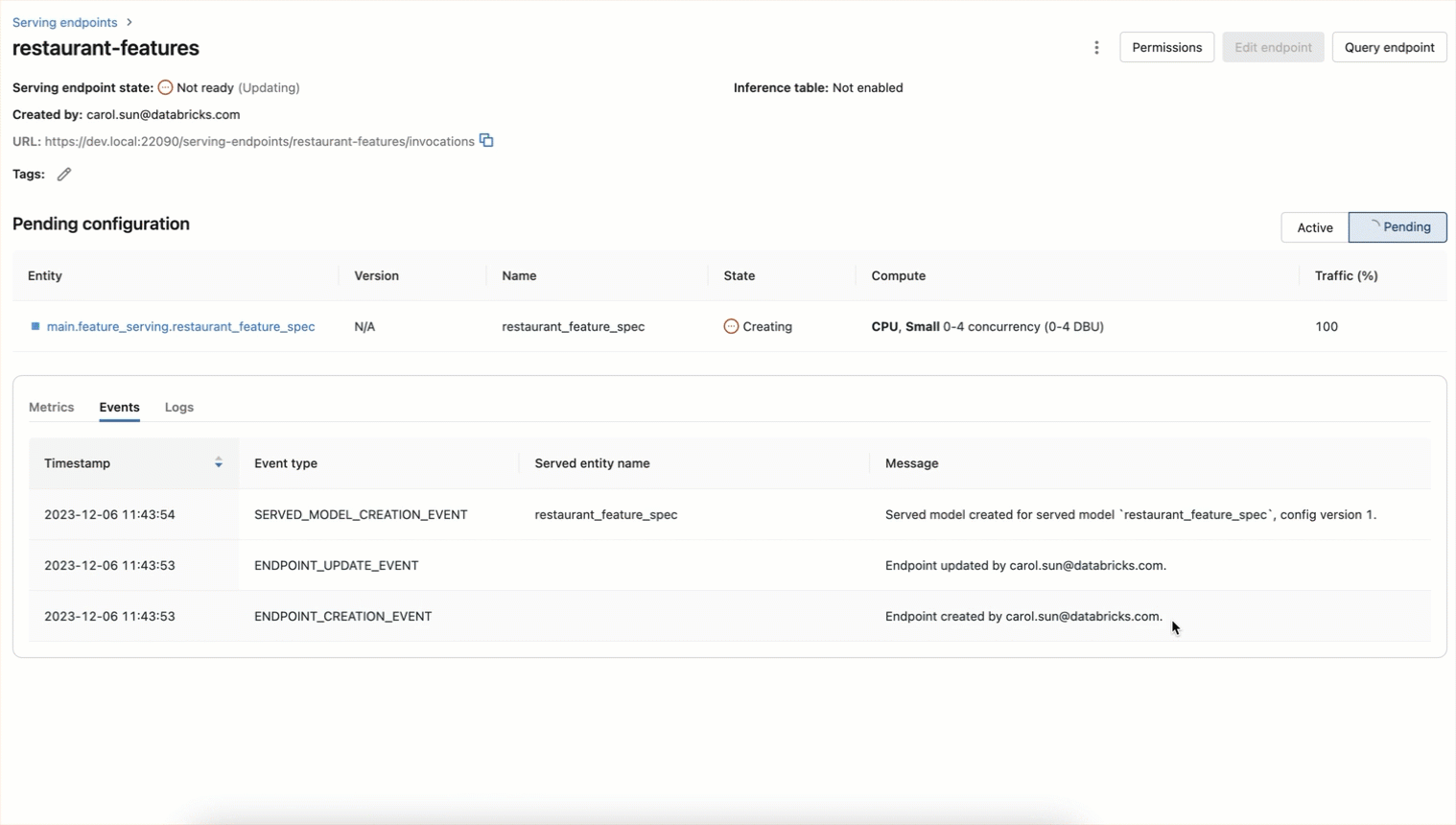
With Feature Engineering in Unity Catalog you can already use any table with a primary key to serve features for training and serving. Databricks Model Serving supports using Python functions to compute features on-demand. Built using the same technology available under the hood for Databricks Model Serving, feature and function endpoints can be used to access any pre-computed feature or compute them on-demand. With a simple syntax you can define a feature spec function in Unity Catalog that can encode the directed acyclic graph to compute and serve features as a REST endpoint.
This feature spec function can be served in real-time as a REST endpoint. All endpoints are accessible in the Serving left navigation tab including features, function, custom trained models, and foundation models. Provision the endpoint using this API
The endpoint can also be created using a UI workflow as shown below
Now features be accessed in real-time by querying the endpoint:
To serve structured data to real-time AI applications, precomputed data needs to be deployed to operational databases. Users can already use external online stores as a source of precomputed features--for example DynamoDB and Cosmos DB are commonly used to serve features in Databricks Model Serving. Databricks Online Tables (AWS)(Azure) adds new functionality that simplifies synchronization of precomputed features to a data format optimized for low latency data lookups. You can sync any table with a primary key as an online table and the system will set up an automatic pipeline to ensure data freshness.
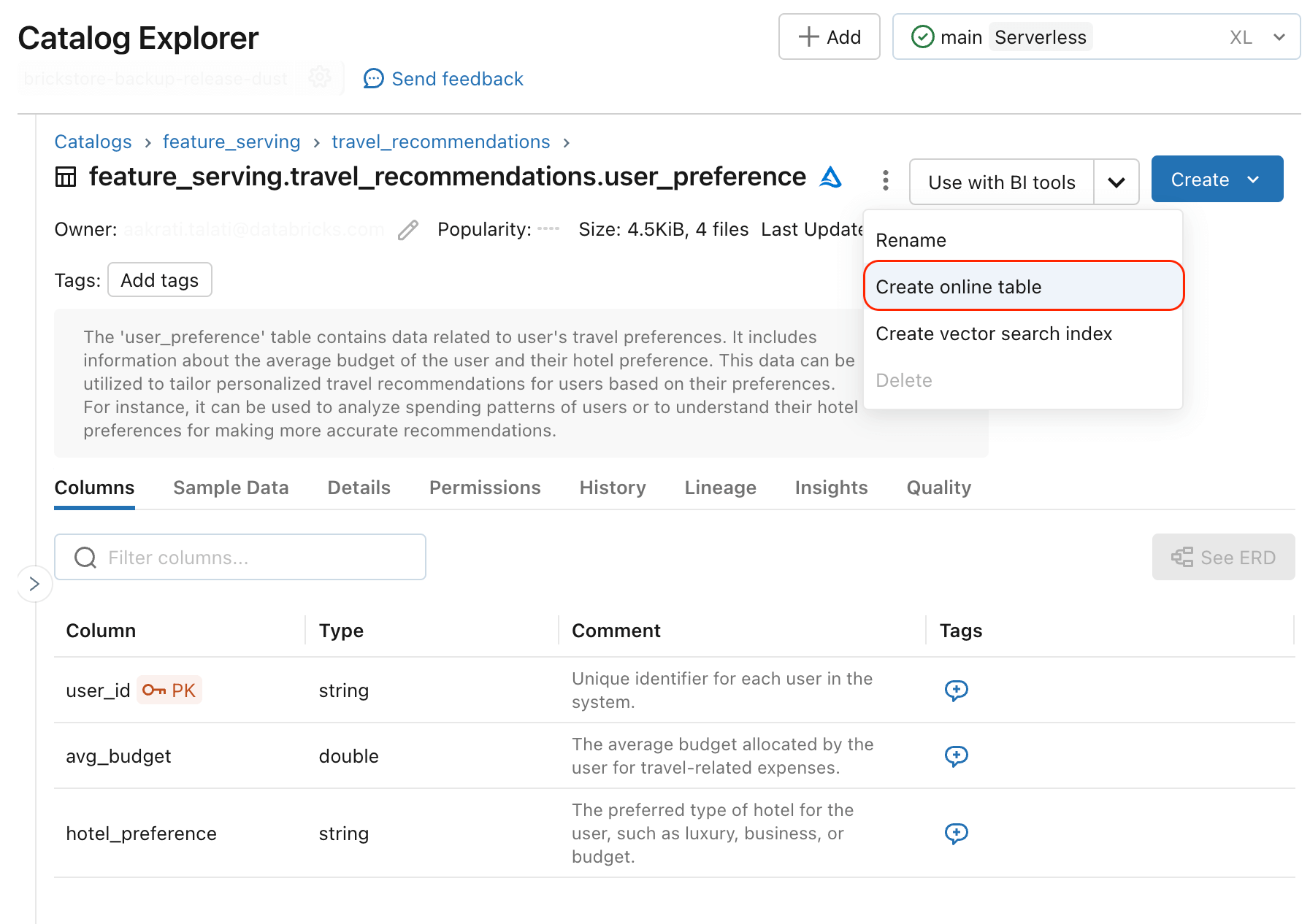
Any Unity Catalog table with primary keys can be used to serve features in Gen AI applications using Databricks Online Tables.
Next Steps
Use this notebook example illustrated above to customize your RAG applications
Sign–up for a Databricks Generative AI Webinar available on-demand
Feature and Function Serving (AWS)(Azure) is available in Public Preview. Refer to API documentation and additional examples.
Databricks Online Tables (AWS)(Azure) are available as Gated Public Preview. Use this form to sign up for enablement.
Read the summary announcements (making high quality RAG applications) made earlier this week.
Generative AI Engineer Learning Pathway: take self-paced, on-demand and instructor-led courses on Generative AI
Looking to solve Generative AI use cases? Compete in the Databricks & AWS Generative AI Hackathon! Sign up here.
Have a use case you'd like to share with Databricks? Contact us at feature-serving@databricks.com
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.