Spark on Databricks
The best platform to run your Spark workloads, from the original creators of Apache Spark™
Simplicity, best-in-class operational excellence and price/performance benefits make the Databricks Lakehouse Platform the best place to run your Apache Spark™ workloads
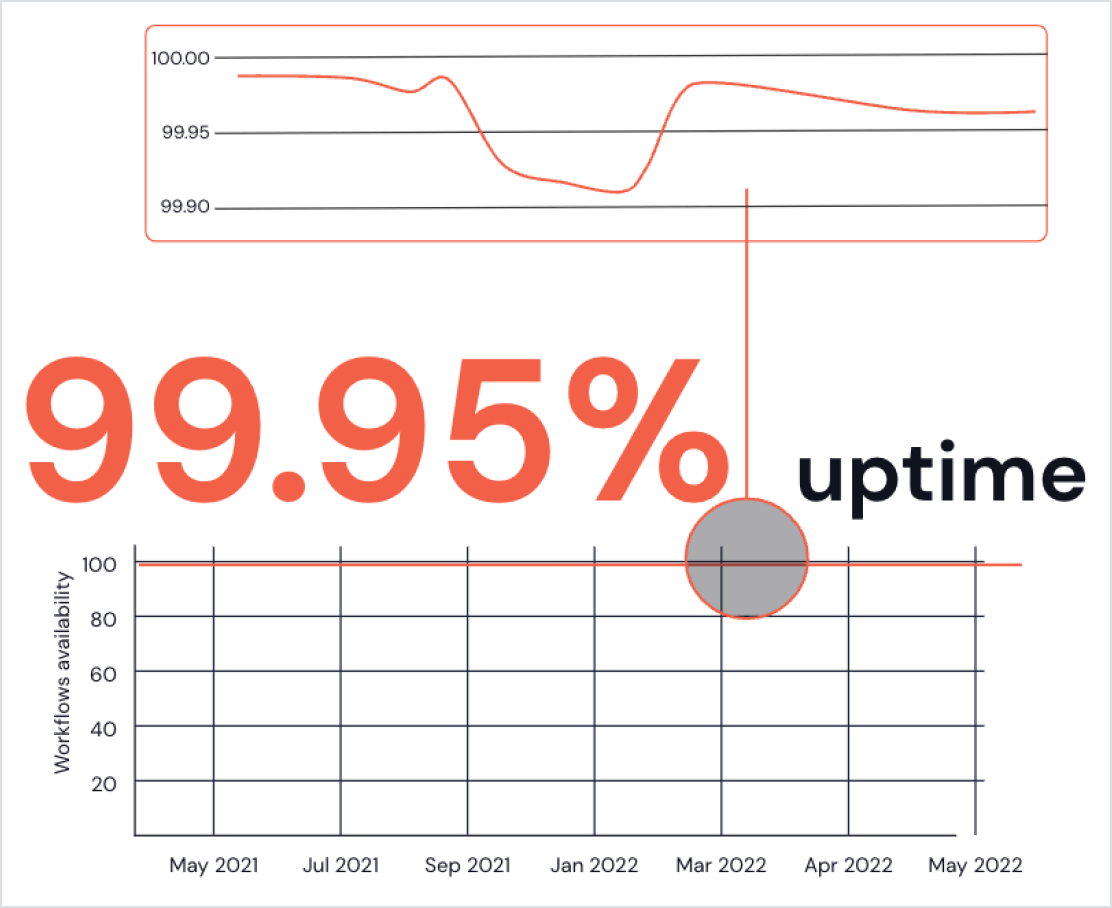
Best-in-class operational excellence
We help thousands of customers launch millions of VMs every day to run their Spark applications. And we support the latest developer tools and guidance, ensuring that you can develop and deploy your Spark applications with confidence and ease.
- Run your Spark applications individually or deploy them with ease on Databricks Workflows
- Run Spark notebooks with other task types for declarative data pipelines on fully managed compute resources
- Workflow monitoring allows you to easily track the performance of your Spark applications over time and diagnosis problems within a few clicks
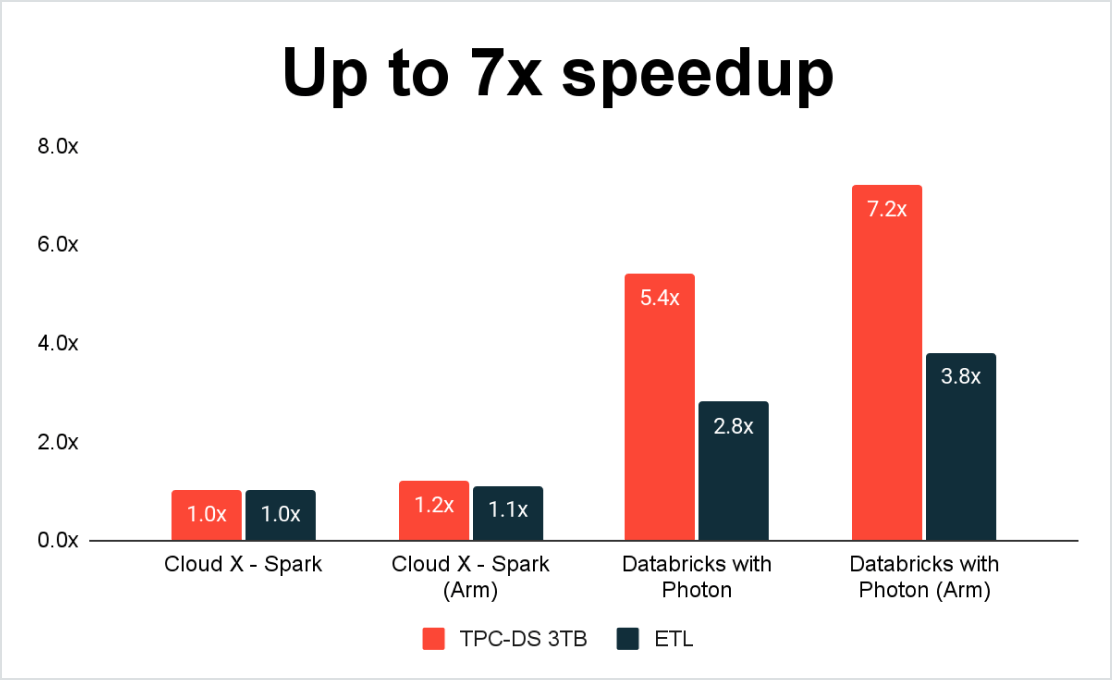
Best price/performance for Spark workloads
Running your Spark workloads on the Databricks Lakehouse Platform means you benefit from Photon – a fast C++, vectorized execution engine for Spark and SQL workloads that runs behind Spark’s existing programming interfaces. Photon provides record-breaking query performance at low cost while leveraging the latest in modern hardware architectures such as AWS Graviton.
In addition to lightning-fast performance, Spark on Databricks achieves lower overall TCO through capabilities such as dynamic autoscaling, so you only pay for what you use. Databricks also offers GPU and spot instances.

End-to-end analytics and unified governance with the Databricks Lakehouse Platform
While other platforms require you to integrate multiple tools and manage different governance models, Databricks unifies data warehouse, data lake and data streaming in one simple Lakehouse Platform to handle all your data engineering, analytics and AI use cases end-to-end. It’s built on an open and reliable data foundation that efficiently handles all data types, unifies batch and streaming, and applies one common security and governance model across all your data and cloud platforms.

Continued innovation
The 2022 SIGMOD Systems Award recognized Spark as an innovative, widely used, open source, unified data processing system encompassing relational, streaming and machine learning workloads.
And the innovation continues. Recently we introduced Spark Connect and Project Lightspeed.
Spark Connect decouples the client and server for better stability and allows for Spark applications everywhere.
Project Lightspeed, the next generation of Spark Structured Streaming, further delivers on predictable low latency and enhanced functionality for processing events.
Ready to get started?