Entregando Conteúdo de Marketing Gerativo aos Clientes
Combinando Dados do Cliente e IA Gerativa para Melhor Conectar com os Clientes, Parte 2

Summary
- Personalização Escalável: A IA Generativa automatiza a criação de conteúdo de marketing personalizado usando dados do cliente de Databricks e Amperity.
- Integração Perfeita: Amperity sincroniza dados de público com Braze, permitindo a entrega precisa de conteúdo através da Ingestão de Dados na Nuvem.
- Entrega Dinâmica de Email: A modelagem Liquid no Braze personaliza as linhas de assunto e o conteúdo do corpo do email, aumentando o engajamento e as conversões.
Os profissionais de marketing sempre sonharam com o engajamento individualizado com o cliente, mas a criação do volume de mensagens necessárias para um engajamento personalizado nesse nível tem sido um grande desafio. Embora muitas organizações busquem um marketing mais personalizado, elas geralmente miram em grandes grupos de milhares ou milhões de clientes, nos quais ainda existe uma grande diversidade. Embora isso seja melhor do que uma abordagem genérica, que serve para todos, as organizações prefeririam ser mais precisas, se apenas tivessem a capacidade de se envolver em um nível mais granular.
Como mencionado em nosso blog anterior, a IA generativa pode ajudar a aliviar o desafio de criar conteúdo de marketing altamente personalizado. Embora alcançar um verdadeiro engajamento individual ainda possa ser difícil devido a algumas das limitações da tecnologia em seu estado atual, combinar detalhes do cliente com conteúdo de amostra e engenharia de prompts inteligentes pode ser usado para criar de forma econômica um volume gerenciável de variantes personalizadas. Aplicar modelos independentes para avaliar o conteúdo gerado antes de ser encaminhado para uma revisão final com um profissional de marketing experiente pode contribuir muito para garantir que esse conteúdo mais detalhado atenda aos padrões organizacionais enquanto está mais precisamente alinhado com as necessidades e preferências de um subsegmento específico.
Mas como transformamos isso em um fluxo de trabalho confiável? E, crucialmente, como realmente entregamos todas essas variantes de conteúdo aos clientes pretendidos usando nossas tecnologias de marketing existentes? Neste post, continuamos a construir o cenário do guia de presentes de fim de ano introduzido no blog anterior e demonstramos um fluxo de trabalho de ponta a ponta para entrega de conteúdo baseado em e-mail com Amperity e Braze, duas plataformas amplamente adotadas na pilha de MarTech empresarial.
Gerando o Conteúdo
Em nosso blog anterior, trabalhamos em como elaborar um prompt capaz de acionar um modelo de IA gerativo para criar uma mensagem de e-mail de marketing adaptada aos interesses de um subsegmento de público. O prompt empregou uma amostra de mensagem de e-mail para servir como guia e, em seguida, incumbiu o modelo de alterar o conteúdo para ressoar melhor com um público com sensibilidades específicas de preço e preferências de atividade (Figura 1).
Figura 1. O prompt desenvolvido para a criação de um guia de presentes de feriado personalizado
Para aplicar este prompt em escala, precisamos remover elementos específicos do cliente (como subcategoria de produto e preferências de preço neste exemplo) e inserir espaços reservados onde esses elementos podem ser inseridos conforme necessário, criando um modelo de prompt. Detalhes específicos do cliente podem então ser inseridos no prompt modelado (hospedado no ambiente Databricks) com detalhes do cliente hospedados na plataforma de dados do cliente (CDP).
Como estamos usando o Amperity para nossa demonstração de CDP, a integração é um processo bastante simples. Usando a capacidade Amperity Bridge, construída usando o protocolo Delta Sharing de código aberto suportado pelo ambiente Databricks, simplesmente criamos uma conexão entre as duas plataformas e expomos as informações apropriadas (Figura 2). (As etapas detalhadas para configurar a conexão da ponte podem ser encontradas aqui.)
Figura 2. Um vídeo explicativo de como se conectar ao Databricks através da Ponte Amperity
Nosso próximo passo é consultar os dados armazenados no CDP, acessíveis dentro do Databricks, para reunir detalhes para cada subsegmento. Uma vez definidos, podemos passar as informações associadas a cada um em nosso prompt para gerar mensagens personalizadas. Uma vez persistido, podemos então iterar sobre a saída, avaliando cada mensagem gerada contra vários critérios antes que esse conteúdo e os resultados da avaliação sejam apresentados a um profissional de marketing para revisão e aprovação final (Figura 3).
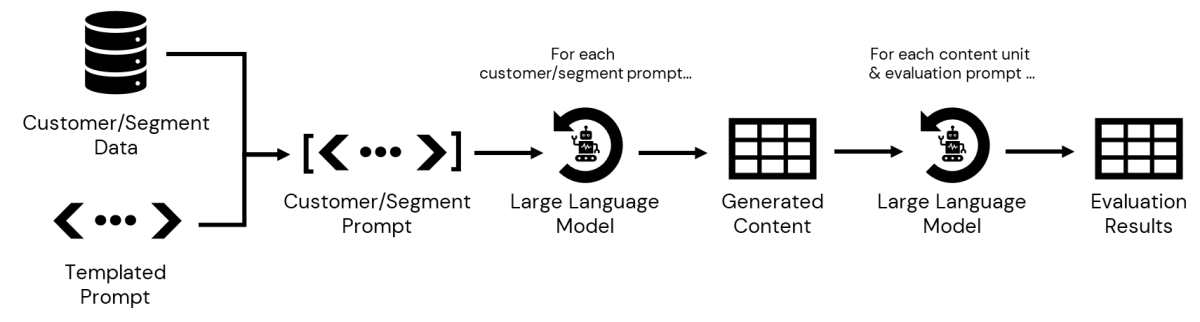
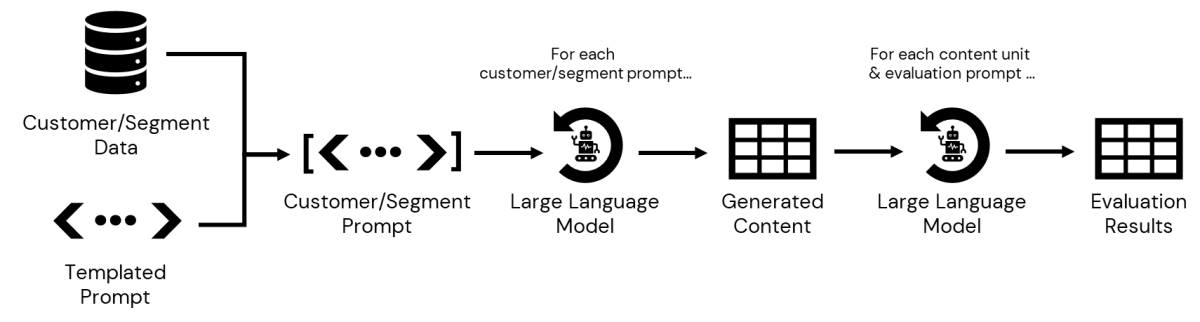{kind=link}
O resultado final deste processo é uma tabela de variantes de conteúdo, uma para cada combinação de ponto de preço preferido e subcategoria de produto, juntamente com uma tabela de saídas de avaliação para cada etapa de avaliação. Os dados estão agora prontos para revisão do profissional de marketing.
NOTA Para uma implementação técnica detalhada do fluxo de trabalho na Figura 3, confira este notebook.
Entregando o Conteúdo
Com nossas variantes de conteúdo criadas, podemos voltar nossa atenção para a entrega. Os detalhes exatos de como proceder neste passo dependem da plataforma de entrega específica que você está usando. Para nossa demonstração, vamos ver como esse conteúdo pode ser entregue usando o Braze, uma plataforma líder em entrega de conteúdo amplamente adotada em organizações de marketing.
Em um nível alto, as etapas envolvidas na entrega deste conteúdo via Braze são as seguintes:
- Envie variantes de conteúdo para o Braze
- Identifique os membros do público que receberão o conteúdo
- Conecte os membros da audiência com variantes de conteúdo específicas
Enviar Variantes de Conteúdo para o Braze
Dentro do Braze, o conteúdo empregado como parte de uma campanha é definido como um Catálogo Braze. Usando Ingestão de Dados na Nuvem Braze, este conteúdo pode ser lido do Databricks, desde que o conteúdo seja apresentado dentro de uma tabela ou visualização contendo um identificador único (ID), um campo datetime indicando quando o conteúdo foi atualizado pela última vez (UPDATED_AT), e um payload JSON (PAYLOAD) com elementos de título e corpo que serão usados para construir o conteúdo entregue.
Para ilustrar como poderíamos construir este conjunto de dados, vamos supor que a saída de nosso fluxo de trabalho de geração de conteúdo (conforme ilustrado na Figura 4) resultou em uma tabela de conteúdo com a seguinte estrutura, onde preferred_price_point e holiday_preferred_subcategory representam os detalhes do subsegmento exclusivos para cada registro na tabela:
Podemos definir uma visualização contra esta tabela para estruturá-la para implantação como um Catálogo Braze da seguinte maneira:
Dentro do Braze, agora podemos definir um catálogo para este conteúdo (Figura 3).
Figura 3. O Catálogo Braze destinado a abrigar nosso conteúdo gerado
Em seguida, configuramos uma sincronização de Ingestão de Dados na Nuvem (CDI), conectando a visualização do Databricks à estrutura do Catálogo Braze e configurando-a para sincronização, garantindo que ela permaneça atualizada (Figura 4).
Figura 4. O mapeamento de sincronização da Ingestão de Dados na Nuvem (CDI) mapeando o Catálogo Braze para a visualização de conteúdo Databricks
Identifique os Membros da Audiência
Agora precisamos dos detalhes dos indivíduos para quem pretendemos entregar este conteúdo. Como nosso objetivo é entregar este conteúdo via e-mail, precisaremos dos endereços de e-mail dos indivíduos alvo. Elementos como nome e sobrenome também podem ser necessários para que o conteúdo possa ser endereçado ao destinatário de maneira mais personalizada. E precisaremos de detalhes sobre como os indivíduos estão alinhados com a subcategoria de produto e preferências de preço. Este último elemento será essencial para conectar os membros do público com as variações de conteúdo específicas armazenadas no Catálogo Braze.
Como estamos usando o Amperity como nosso CDP, enviar essas informações para o Braze é uma simples questão de definir o grupo de destinatários como uma audiência e usar o conector Amperity para enviar esses detalhes (Figura 5).
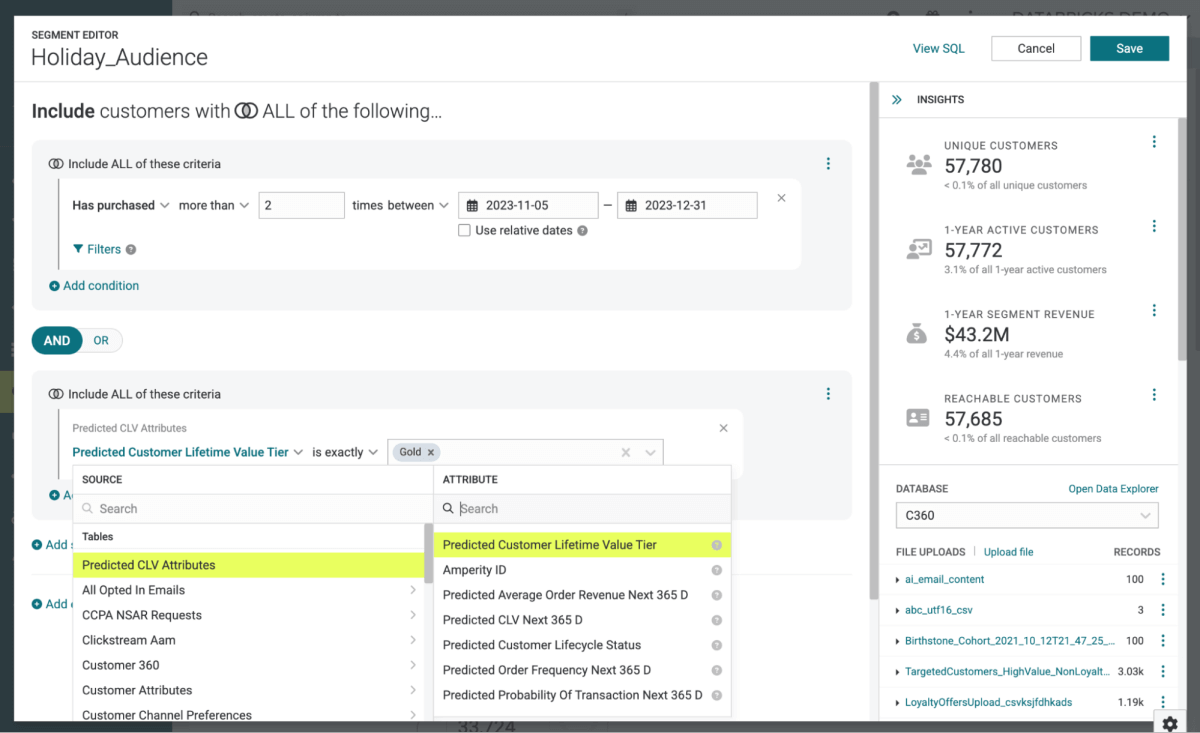
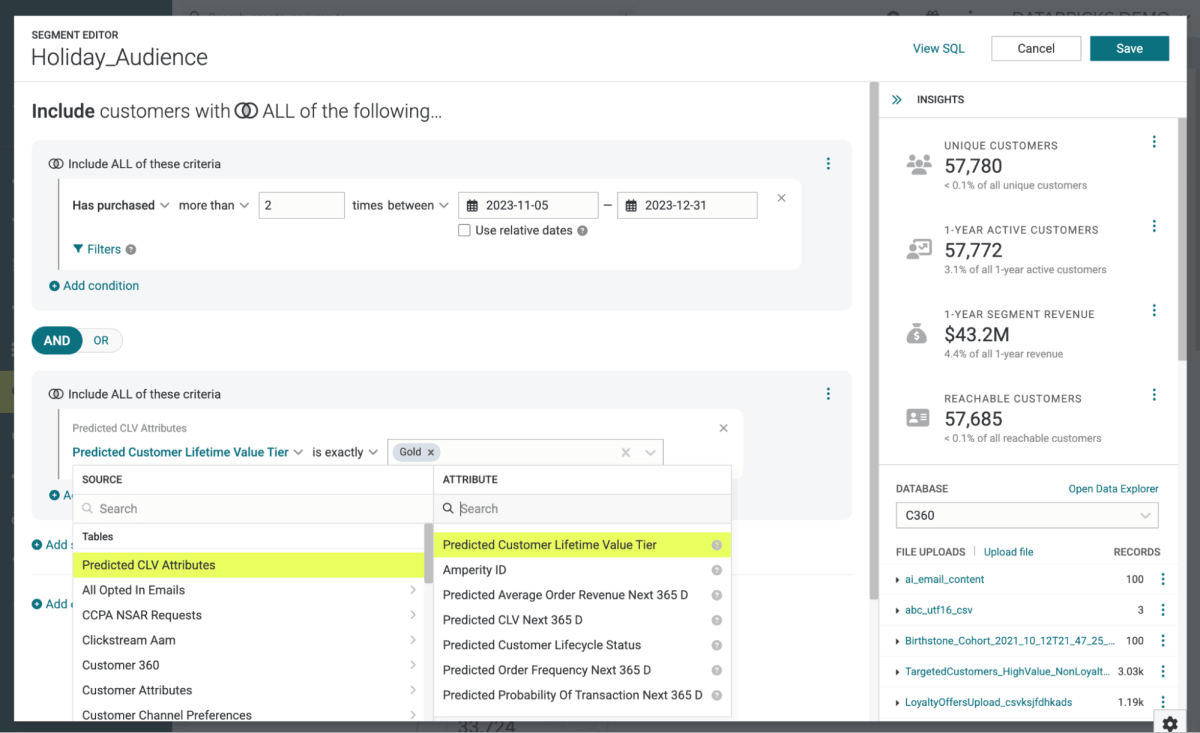{kind=link}
Conecte os Membros do Público com Variantes de Conteúdo
Com todos os elementos em seu lugar dentro do Braze, agora podemos conectar membros da audiência com variantes de conteúdo específicas e programar a entrega. Isso é feito dentro do Braze usando Modelo Liquid, uma linguagem de modelo de código aberto desenvolvida pela Shopify e escrita em Rudy. Esta linguagem é altamente acessível aos profissionais de marketing e permite que eles definam conteúdo personalizável para distribuição em larga escala.
Introdução
Databricks está sendo cada vez mais usado dentro das empresas como o hub central para capacidades de dados e análises. Com capacidades de IA gerativas integradas e altamente extensíveis, bem como integração profunda em uma variedade de plataformas complementares, como o CDP Amperity e a plataforma de entrega de conteúdo Braze, as organizações estão construindo uma ampla gama de aplicações, como a demonstrada neste blog, com o Databricks no centro.
Se você gostaria de aprender mais sobre como o Databricks pode ser usado para ajudar suas equipes de Marketing a criar e entregar conteúdo mais personalizado para seus clientes, entre em contato e vamos discutir as muitas opções disponíveis para desenvolver soluções usando a plataforma.
Este processo aproveita vários componentes-chave e utiliza o seguinte fluxo de trabalho:
- Estrutura de Conteúdo & Ingestão
- Uma visualização é criada a partir da tabela de variantes de conteúdo, estruturada para uso pelo Ingestão de Dados na Nuvem Braze
- Um Catálogo Braze é criado como um repositório para as variantes de conteúdo
- Uma sincronização de ingestão de dados na nuvem é configurada, e o Braze sincroniza as variantes de conteúdo da View para o Catálogo
- Ativação de Público Amperity - Amperity sincroniza o público de usuários para quem o conteúdo foi criado com o Braze para um direcionamento preciso.
- Construção de Campanha & Modelagem Liquid
- Linguagem de modelagem Liquid é usada para referenciar a linha correspondente no Catálogo de variantes de conteúdo.
- Liquid preenche dinamicamente o assunto e o corpo do e-mail, personalizado para cada usuário.
Passo 3: Construção da Campanha e Modelagem Liquid
A etapa final envolve a construção da campanha Braze.
Modelagem Liquid desempenha um papel fundamental aqui, permitindo a inserção dinâmica do conteúdo gerado com base em atributos de usuário armazenados nos perfis Braze. Esses atributos, sincronizados via ativação Amperity, são referenciados para criar um ID de linha de Catálogo correspondente. Este ID é então usado para buscar e inserir a linha de assunto gerada e o corpo do e-mail.
3a. Linha de Assunto do EmailUsando os filtros Liquid, combinamos os atributos `preferred_price_point` e `holiday_preferred_subcategory`, separados por um sublinhado, para criar uma variável local `identifier`:
Este `identifier` gerado dinamicamente é então usado para referenciar o ID correspondente no catálogo HolidayGenAI:
Figura 5. Captura de tela das configurações de envio com Liquid
Para um usuário com um `preferred_price_point` alto e `holiday_preferred_subcategory` de Caminhada, a saída Liquid resultante na linha de assunto do e-mail será derivada do título do item correspondente do catálogo:
Figura 6. Item do catálogo mostrando a linha relevante
3b. Corpo do Email
Podemos seguir a mesma abordagem para puxar o conteúdo gerado para o corpo do e-mail.
O resultado final é um e-mail que puxa dinamicamente o conteúdo do e-mail gerativo, personalizado para o ponto de preço preferido de cada usuário e subcategoria, gerando melhor engajamento e taxas de conversão mais altas.
Figura 7. Captura de tela do email
Este caso de uso poderia se expandir ainda mais para incluir a adição de imagens gerativas ou até mesmo o uso de Conteúdo Conectado para consultar um endpoint Databricks diretamente no momento do envio.
Para uma implementação técnica detalhada do fluxo de trabalho na Figura 3, confira este notebook.
(This blog post has been translated using AI-powered tools) Original Post

Varejo e bens de consumo
March 20, 2024/3 min de leitura
Unlock deeper marketing insights with Hightouch Campaign Intelligence and Databricks
Nunca perca uma postagem da Databricks
O que vem a seguir?

Varejo e bens de consumo
August 20, 2025/9 min de leitura
De Reserva a Bon Voyage: Como a IA está redefinindo a experiência de Viagem & Hospitalidade

Varejo e bens de consumo
August 20, 2025/6 min de leitura