Construído para armazenamento de dados aberto e inteligente
Escolha o local e o formato de armazenamento, com total controle e portabilidade dos seus dados.
EQUIPES DE MELHOR DESEMPENHO USAM A INTELIGÊNCIA DE DADOS
Armazenamento Lakehouse flexível e rápido
Elimine as dores de cabeça com a gestão de dados com formatos de tabela abertos, governança centralizada e otimizações automáticas de dados.Formatos compatíveis
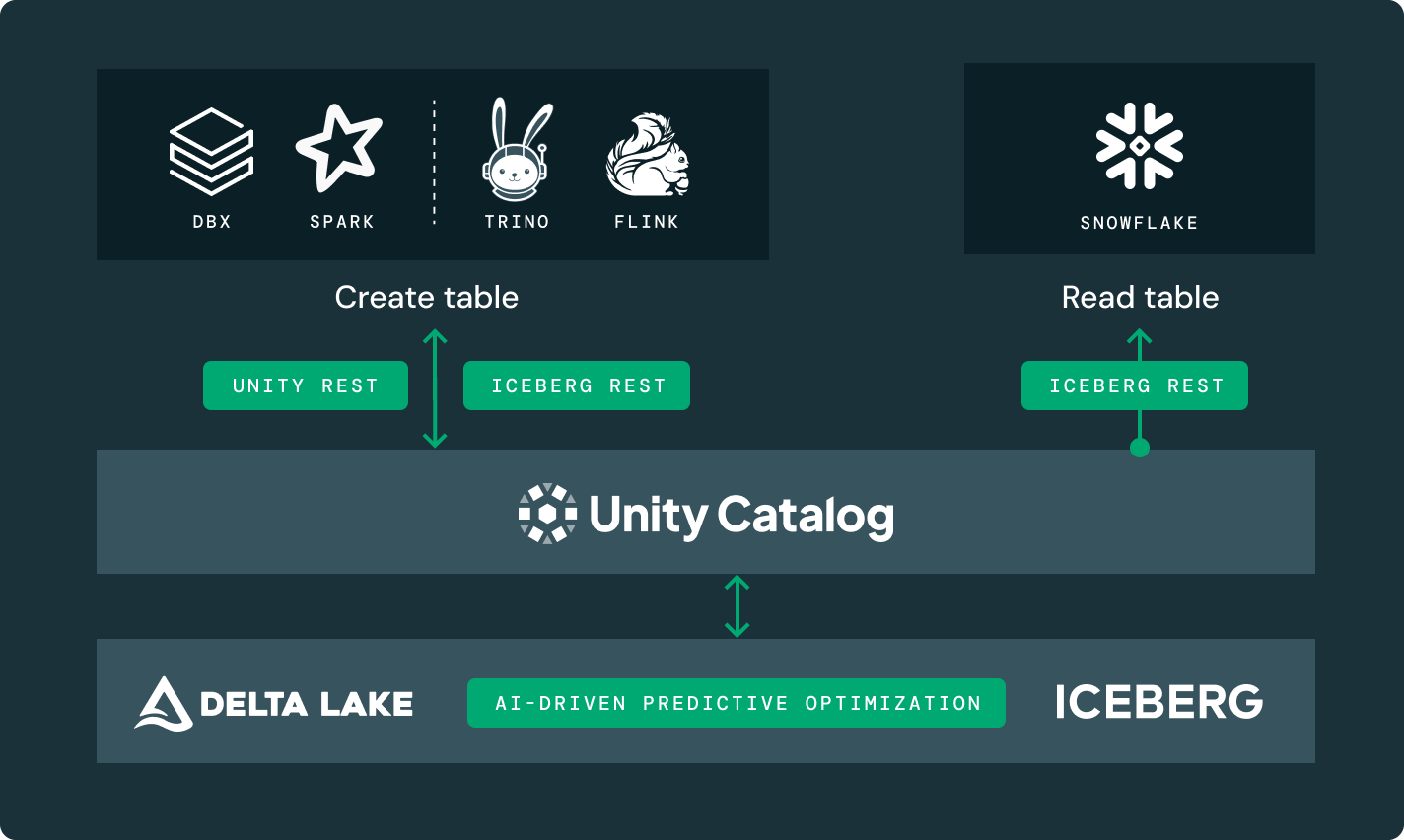
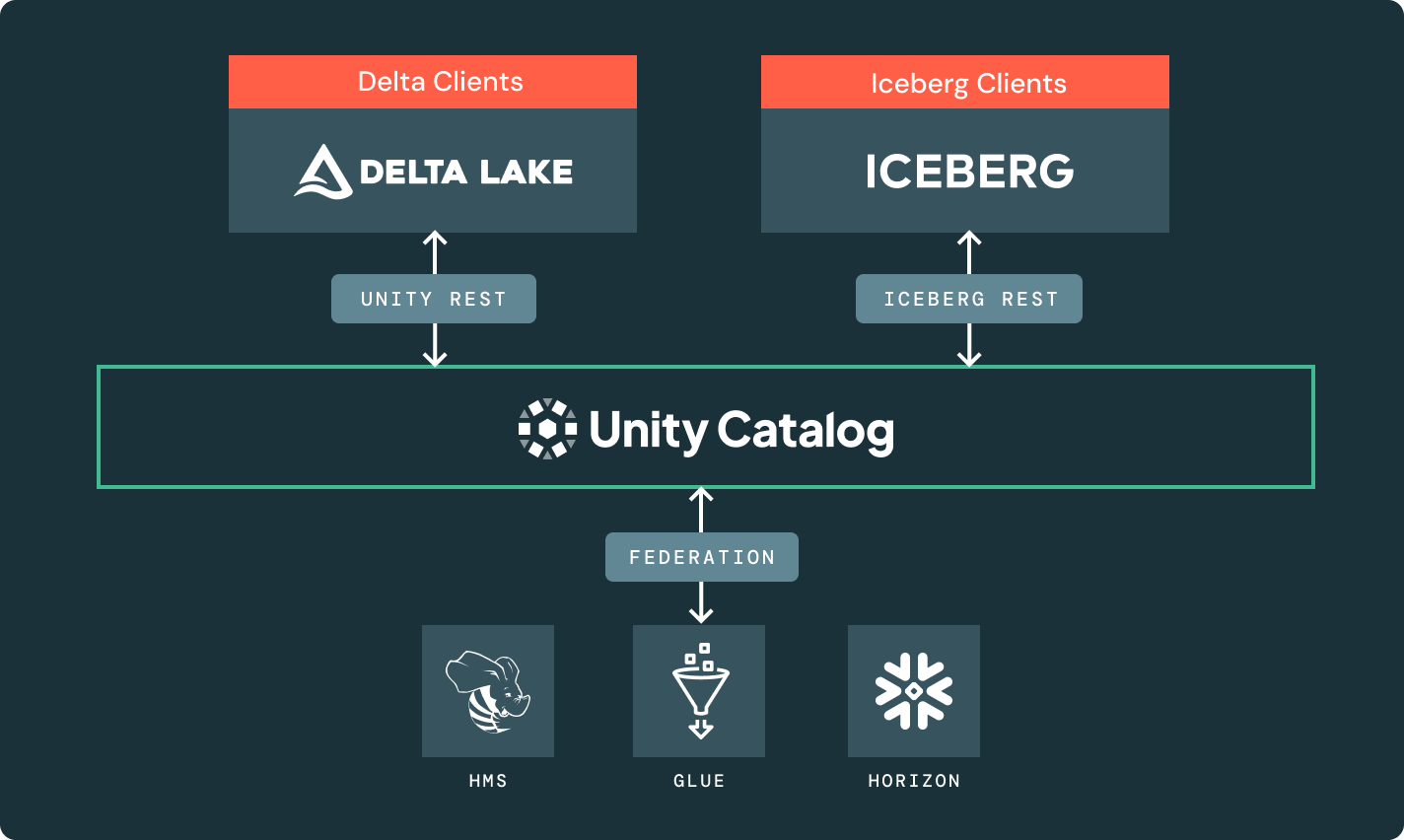
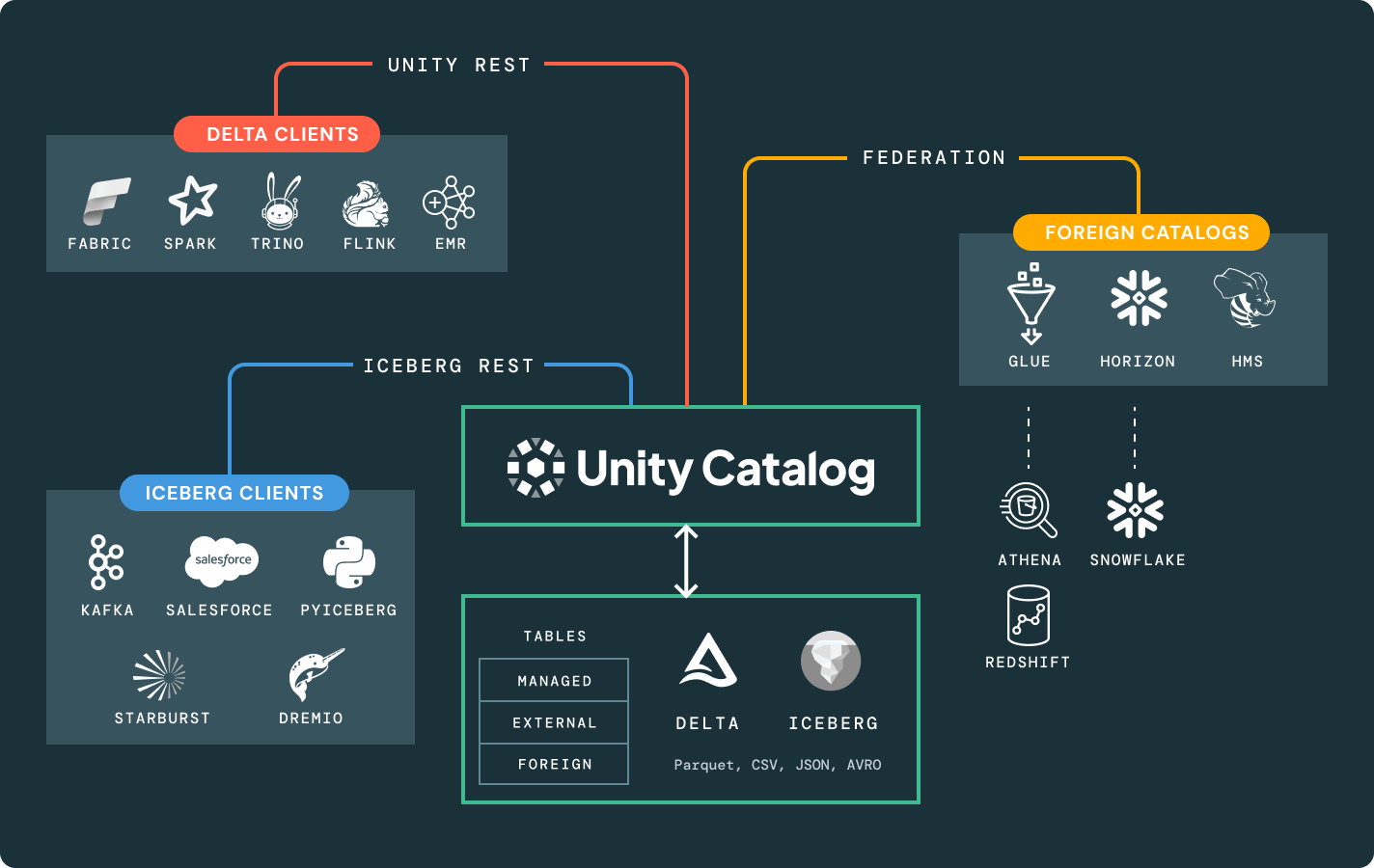
Uma única cópia dos dados de origem no Delta Lake ou Apache Iceberg™ que pode ser acessada por qualquer motor.
Governança unificada
Um único catálogo para descoberta e governança de dados, abrangendo seus dados e ativos de IA.
Desempenho impulsionado por IA
Modelos alimentados por IA otimizam e mantêm dados de forma autônoma para velocidade e baixo custo.
Seus dados, do seu jeito
Escolha o local de armazenamento e o formato aberto que funciona para você. Mantenha seus dados portáteis, sem bloqueio de fornecedor.Desempenho de leitura e escrita de primeira classe para tabelas Delta Lake e Apache Iceberg™, pronto para uso, com otimizações de armazenamento não disponíveis em qualquer outro lakehouse.
Mais recursos
Para todas as suas cargas de trabalho de análise e IA
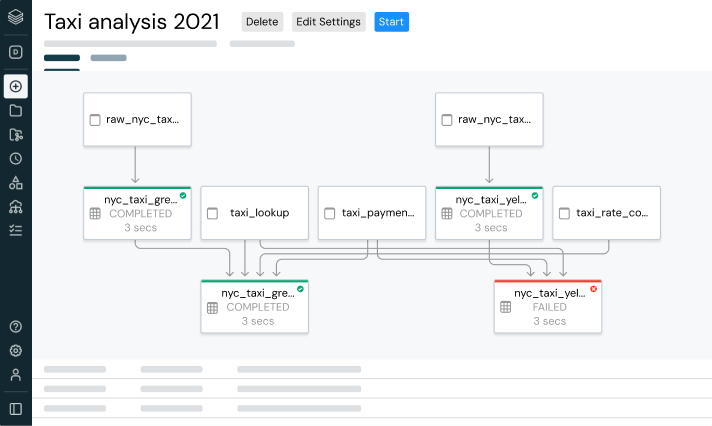
Construa e gerencie pipelines de dados confiáveis
Sua frase principal opcional aparece aqui, exibida um pouco maior.
As tabelas gerenciadas atuam como tabelas de lote e como fonte e destino de streaming. A ingestão de dados de streaming, o preenchimento histórico em batch e as queries interativas funcionam sem nenhum esforço extra, integrando-se diretamente ao Spark Structured Streaming.
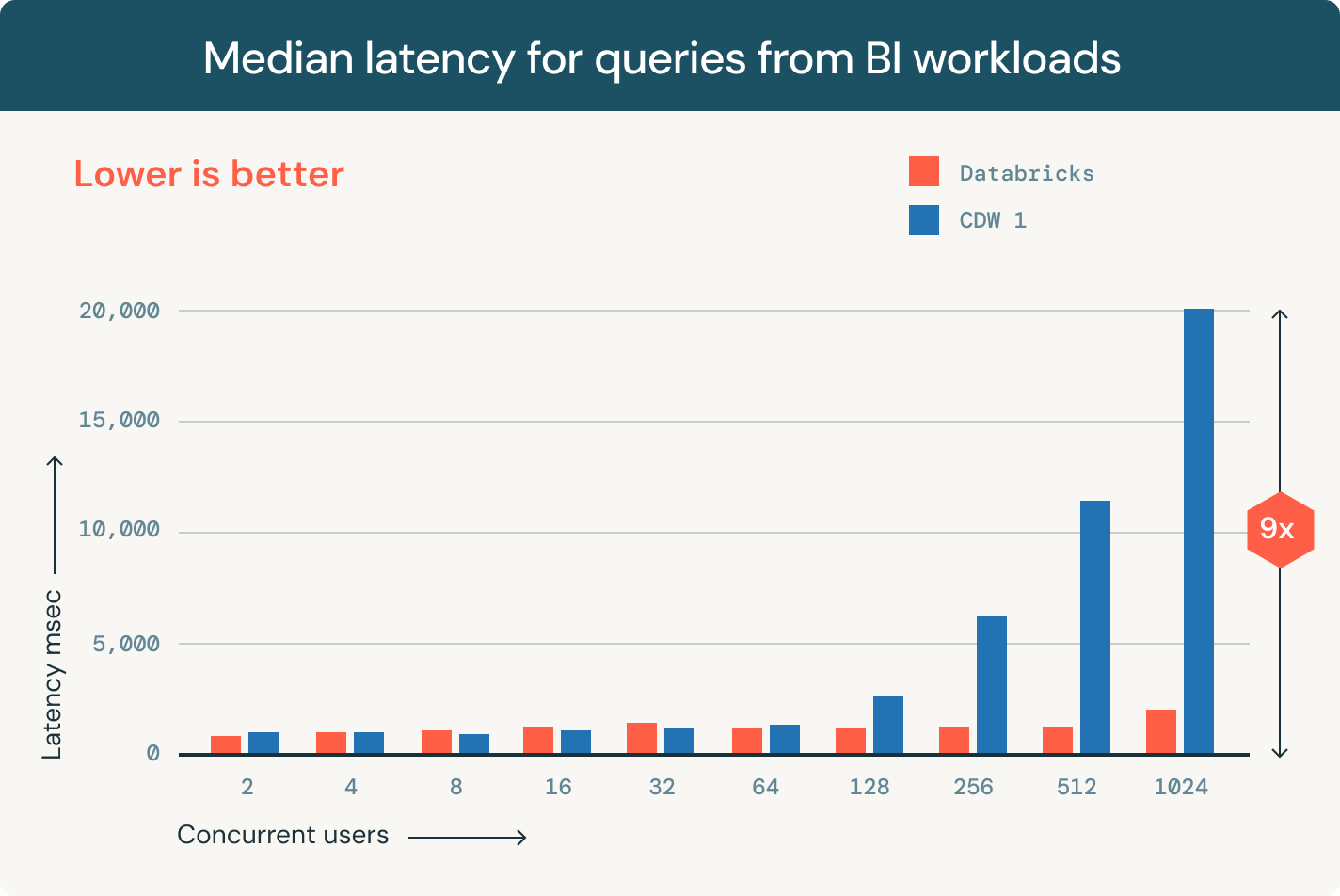
Explore as demonstrações do Delta Lake
Delta Lake
Lendo Tabelas do Catálogo Unity no Snowflake
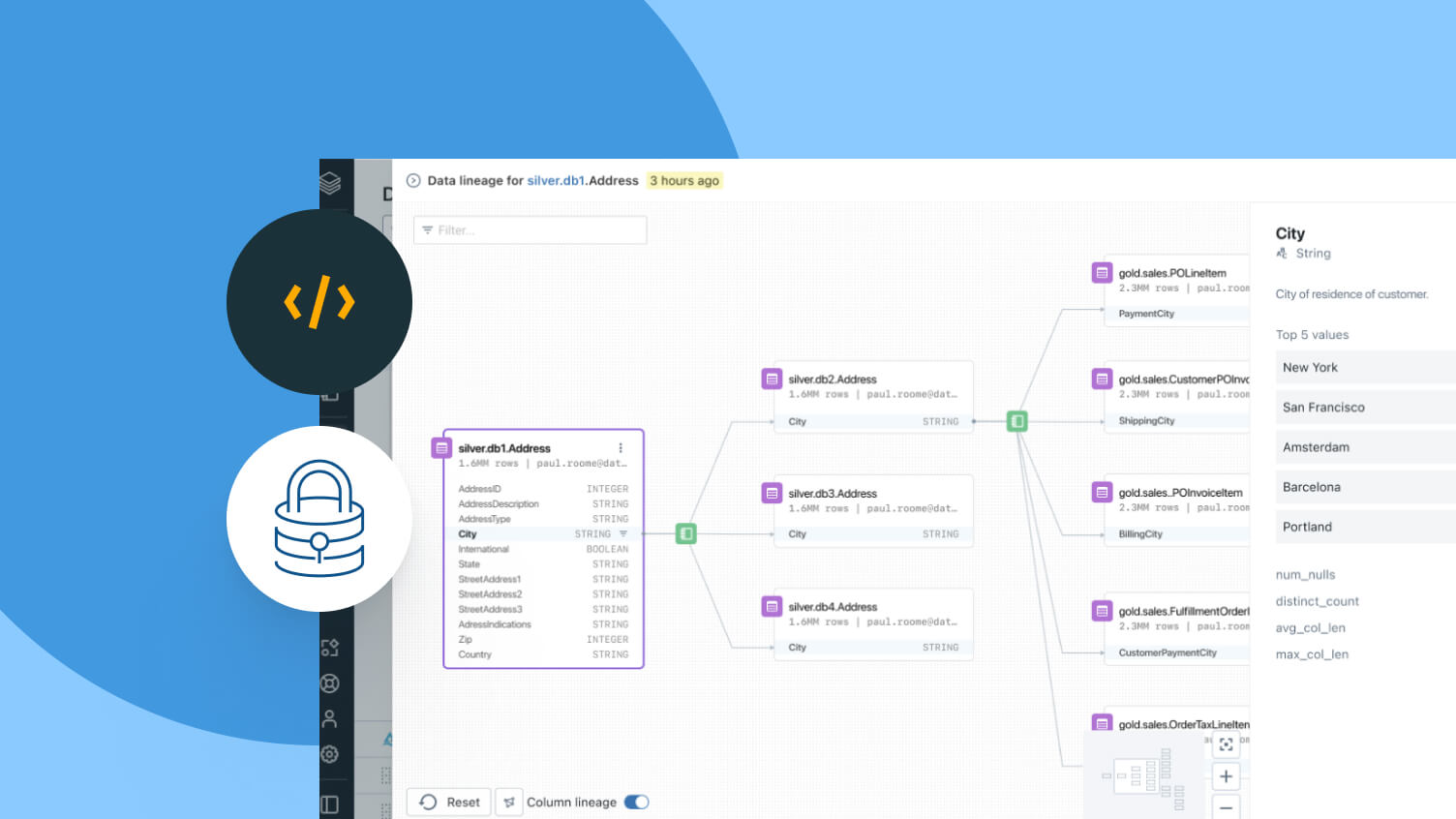
Delta Lake 3.0: UniForm e Clustering Líquido
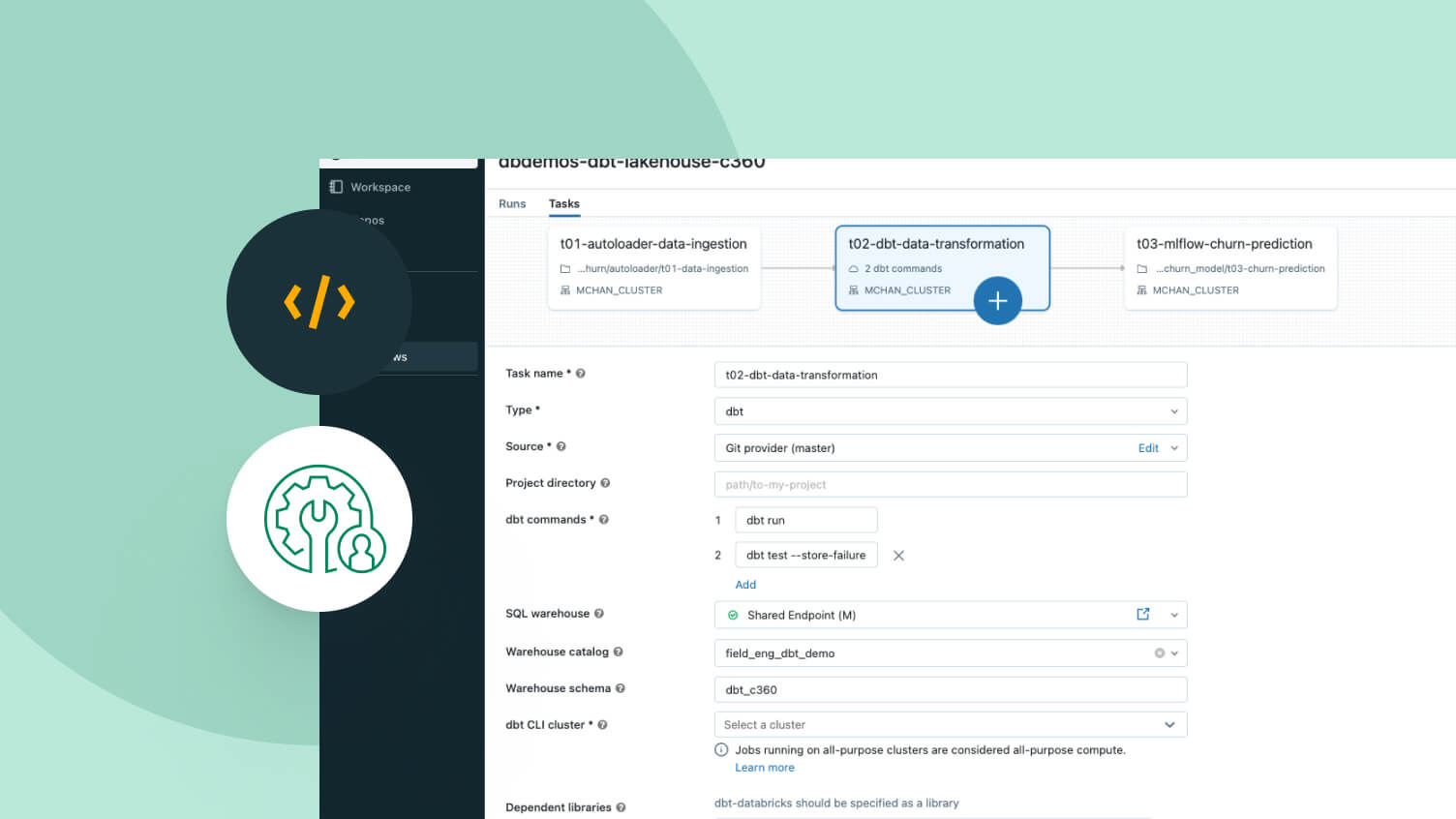
Pipeline CDC com Delta
Descubra, governe e compartilhe seus dados e ativos de IA
Saiba mais sobre como a Databricks Data Intelligence Platform capacita suas equipes de dados em todas as suas cargas de trabalho de dados e IA.Unity Catalog
A única solução de governança unificada e aberta do setor para dados e IA, integrada à Databricks Data Intelligence Platform.
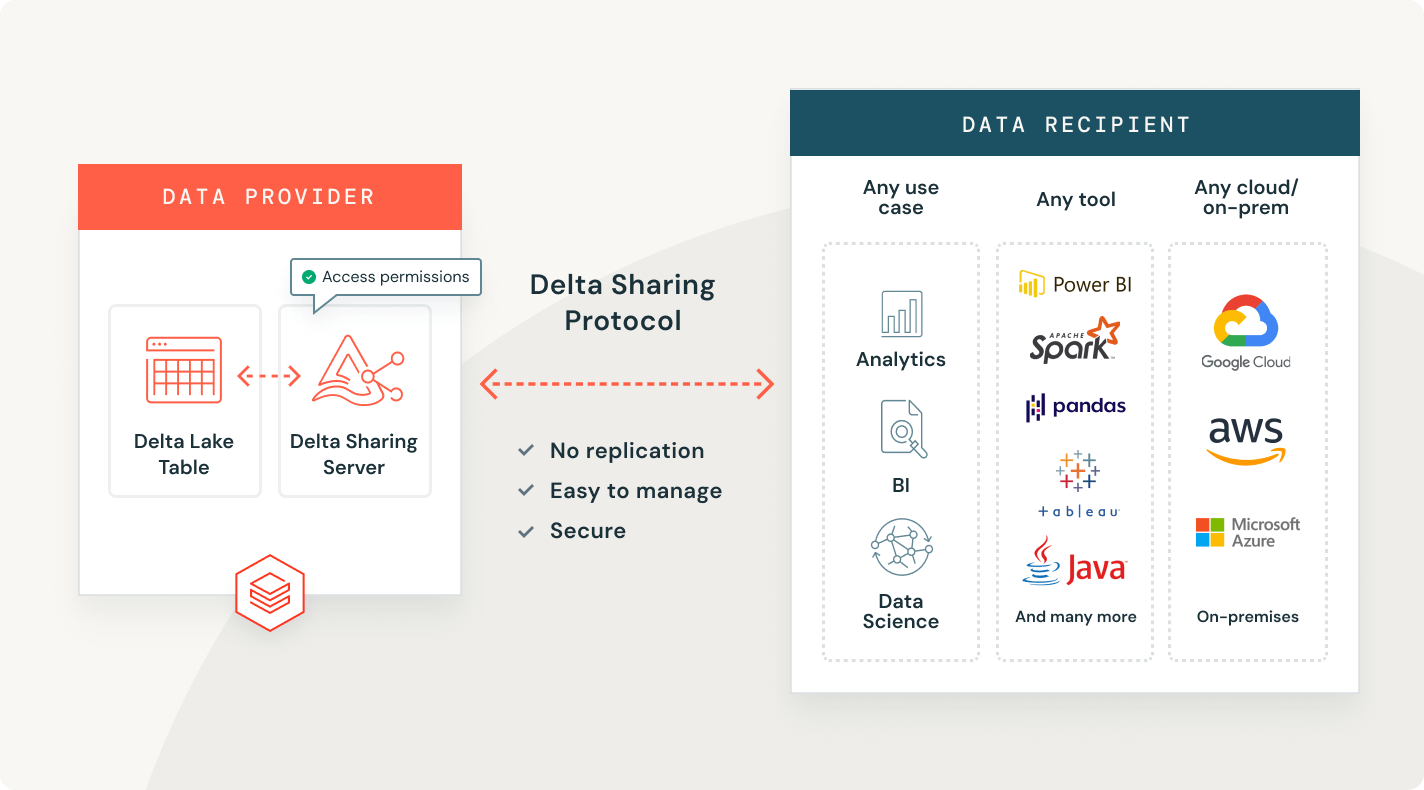
Delta Sharing
A primeira abordagem de código aberto para compartilhamento de dados entre dados, análises e IA. Compartilhe dados ao vivo de forma segura entre plataformas, nuvens e regiões.
Plataforma de inteligência de dados
Aproveite a grande variedade de ferramentas disponíveis na Databricks Data Intelligence Platform para integrar dados e AI em toda a sua organização.
Saiba mais




FAQ de armazenamento Lakehouse
Pronto para se tornar uma empresa de dados + AI?
Dê os primeiros passos em sua transformação