Apache Kylin
O que é o Apache Kylin?
Apache Kylin é um mecanismo de processamento analítico online (OLAP) distribuído e de código aberto para análises interativas de big data. O Apache Kylin foi projetado para fornecer uma interface SQL e análise multidimensional (OLAP) no Hadoop/Spark. Além disso, ele se integra facilmente com ferramentas de BI por meio de driver ODBC, driver JDBC e API REST. Foi criado pelo eBay em 2014, tornou-se um Projeto de Nível Superior da Apache Software Foundation apenas um ano depois, em 2015, e ganhou o prêmio de Melhor Ferramenta de Big Data de Código Aberto em 2015 e 2016. Atualmente, está sendo utilizado por milhares de empresas em todo o mundo como seu aplicativo crítico de analítica para big data. Enquanto outros motores OLAP enfrentam dificuldades com o volume de dados, o Kylin possibilita respostas à query em milissegundos. Ele proporciona latência de consulta em nível de sub-segundo em conjuntos de dados que escalam até petabytes. Atinge sua incrível velocidade pré-computando as várias combinações dimensionais e os agregados de medidas através de Hive queries e preenchendo o HBase com os resultados. 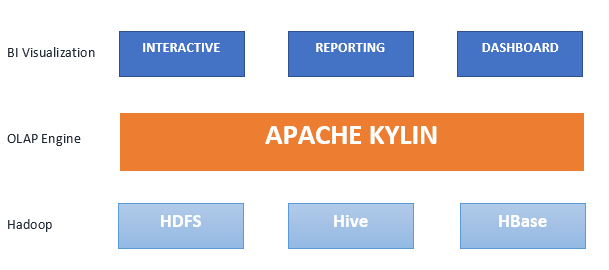
Como o Apache Kylin funciona?
O mecanismo de query Kylin, acessível na interface amigável do Kylin, por meio de uma API ou via JDBC, utilizará o processador de consultas Apache Calcite e os recursos do HBase para buscas rápidas. O Kylin depende do ecossistema Hadoop:
- Hive — Fonte de entrada, esquema estrela pré-join durante a construção do cubo
- MapReduce – Métricas agregadas durante a construção do cubo
- HDFS – Armazenamento de arquivos intermediários durante a construção do cubo
- HBase - Armazenamento e query de cubos de dados
- Calcite – Análise de SQL, geração de código, otimização. Como o Apache Kylin pode ajudar a sua organização?
- Mecanismo OLAP muito rápido em grande escala - O Kylin foi projetado para reduzir a latência de query no Hadoop para mais de 10 bilhões de linhas de dados em segundos
- Interface ANSI SQL no Hadoop - O Kylin oferece ANSI SQL no Hadoop e suporta a maioria das funções de consulta ANSI SQL. Pode ser facilmente utilizado tanto por analistas quanto por engenheiros, pois não é necessário nenhum conhecimento de programação.
- Integração perfeita com ferramentas de BI - Atualmente, a Kylin oferece capacidade de integração com ferramentas de BI como Tableau, JDBC/ODBC/API REST
- Capacidade de consulta interativa - Os usuários podem interagir com os dados do Hadoop por meio do Kylin com latência inferior a um segundo
- Consulta de cubo MOLAP em bilhões de linhas - Os usuários têm a capacidade de definir um modelo de dados e pré-construí-lo no Kylin, mesmo que ele tenha mais de 10 bilhões de dados brutos.
Driver ODBC de código aberto - O driver ODBC da Kylin foi desenvolvido do zero e funciona muito bem com o Tableau.