Spark na Databricks
A melhor plataforma para executar suas cargas de trabalho Spark, dos criadores originais do Apache Spark™
Simplicidade, excelência operacional e benefícios de preço/desempenho da categoria fazem da Plataforma Databricks Lakehouse o melhor lugar para executar suas cargas de trabalho do Apache Spark™
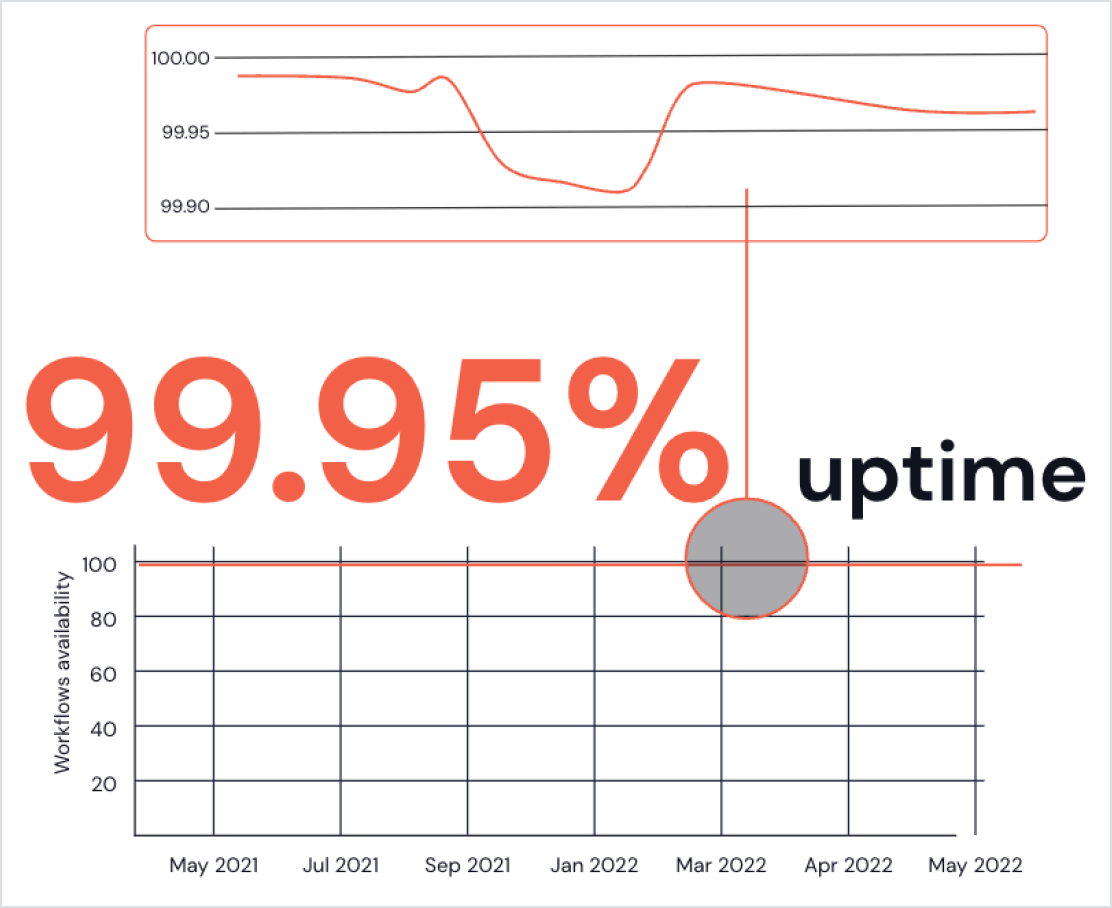
A melhor excelência operacional da categoria
Ajudamos milhares de clientes a lançar milhões de VMs todos os dias para executar suas aplicações Spark. E apoiamos as mais recentes ferramentas e orientações de desenvolvedores, para você desenvolver e implantar suas aplicações Spark com confiança e facilidade.
- Execute seus aplicativos Spark individualmente ou implemente-os com facilidade no Databricks Workflows
- Execute notebooks Spark com outros tipos de tarefa para pipelines de dados declarativos em recursos de compute totalmente gerenciados
- O monitoramento do fluxo de trabalho permite acompanhar facilmente o desempenho de suas aplicações Spark ao longo do tempo e problemas de diagnóstico com apenas alguns cliques
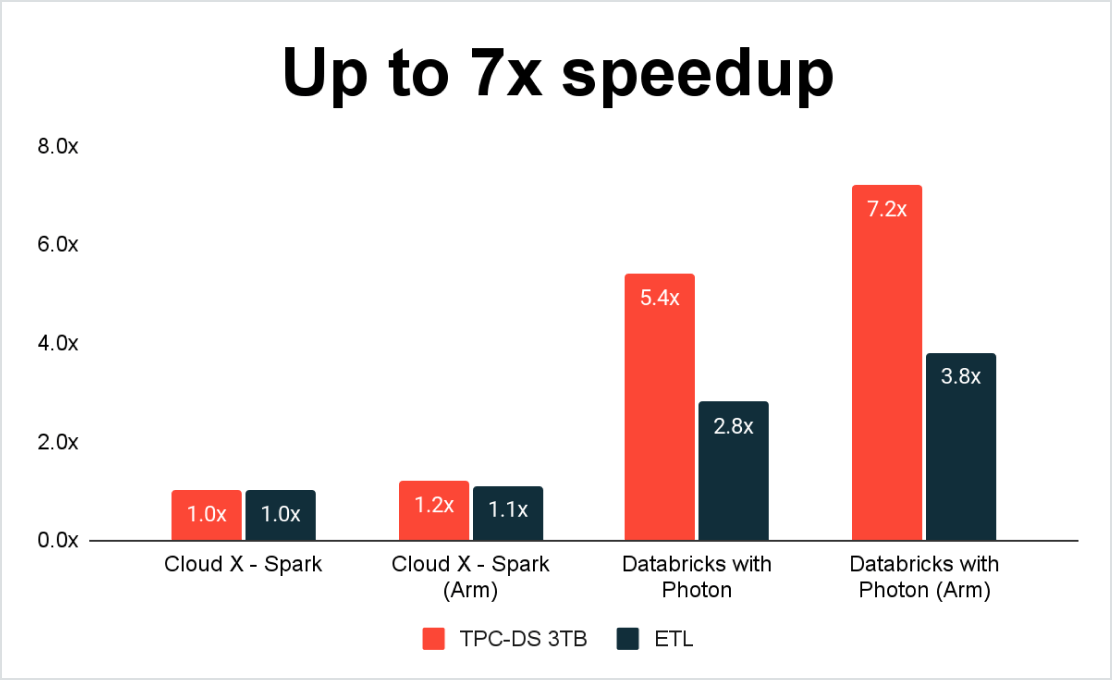
Melhor preço/desempenho para cargas de trabalho Spark
Ao executar suas cargas de trabalho Spark na Plataforma Databricks Lakehouse, você se beneficia do Photon – um mecanismo de execução rápido e vetorizado em C++ para cargas de trabalho Spark e SQL que são executadas atrás das interfaces de programação existentes do Spark. O Photon oferece desempenho de query recorde a baixo custo, aproveitando as arquiteturas de hardware mais recentes e modernas, como o AWS Graviton.
Além do desempenho extremamente rápido, o Spark na Databricks alcança um TCO geral mais baixo por meio de recursos como o dimensionamento automático dinâmico, para você pagar apenas pelo que usar. A Databricks também oferece GPU e instâncias Spot.

Análise completas e governança unificada com a Plataforma Databricks Lakehouse
Enquanto outras plataformas exigem a integração de várias ferramentas e o gerenciamento de diferentes modelos de governança, a Databricks unifica data warehouse, data lake e fluxo de dados em uma simples plataforma de lakehouse para lidar com todos os seus processos de data engineering, análises e casos de uso de IA de ponta a ponta. Ele é construído sobre uma base de dados abertos e confiáveis que lidam de forma eficiente com todos os tipos de dados, unifica batch e streaming e aplica um modelo comum de segurança e governança em todas as suas plataformas de dados e nuvem.

Inovação contínua
O prêmio SIGMOD Systems de 2022 reconheceu o Spark como um sistema de processamento de dados unificado, inovador, amplamente usado e de código aberto que inclui cargas de trabalho relacionais, de streaming e de machine learning.
E a inovação continua. Recentemente, introduzimos o Spark Connect e o Project Lightspeed.
O Spark Connect desvincula o cliente e o servidor para melhor estabilidade e permite aplicativos Spark em todos os lugares.
Projeto Lightspeed, a próxima geração do Spark Structured Streaming, oferece baixa latência previsível e funcionalidade aprimorada para eventos de processamento.
Ready to get started?