Mosaic AI Agent Framework
Build production-quality retrieval augmented generation (RAG) apps


Retrieval augmented generation (RAG) is a generative AI application pattern that finds data/documents relevant to a question or task and provides them as context for large language models (LLMs) to give more accurate responses.
Mosaic AI Agent Framework is a suite of tooling designed to help developers build and deploy high-quality generative AI applications using RAG for output that is consistently measured and evaluated to be accurate, safe and governed. Mosaic AI Agent Framework makes it easy for developers to evaluate the quality of their RAG application, iterate quickly with the ability to test their hypothesis, redeploy their application easily, and have the appropriate governance and guardrails to ensure quality continuously.
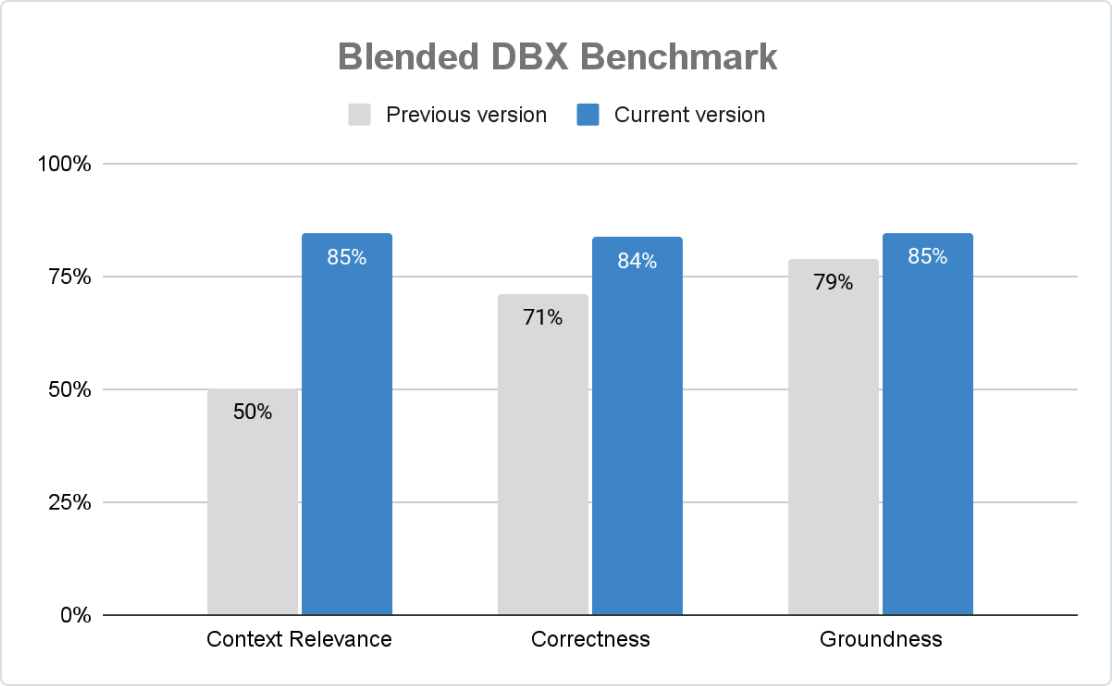
Highest production quality
Agent Framework ensures accurate, safe and governed GenAI applications at scale. With Mosaic AI Agent Evaluation, organizations can customize scoring with rule-based checks, LLM judges, and human feedback, while built-in AI-assisted evaluation and an intuitive UI drive continuous improvement.
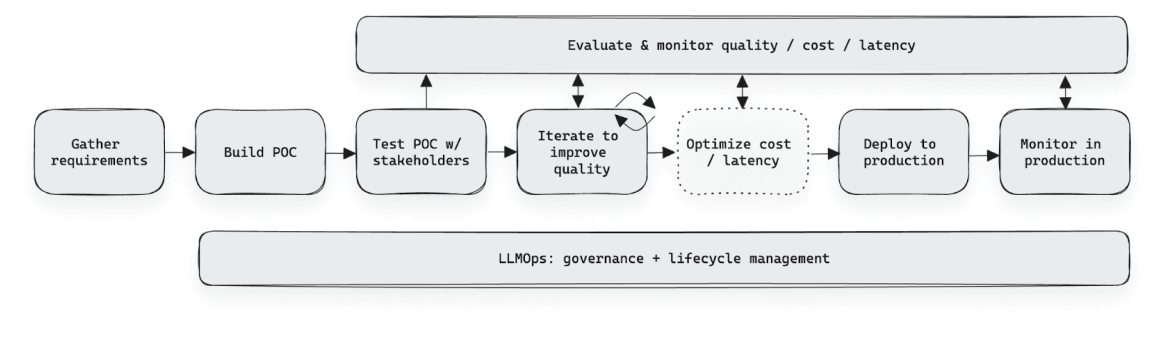
Rapid development iteration
Agent Framework accelerates GenAI development by streamlining feedback collection and evaluation. The Agent Evaluation Review App enables domain experts to assess, label, and define criteria—no spreadsheets or custom tools needed. Structured feedback helps teams refine performance, enhance accuracy, and redeploy seamlessly without code changes, all while ensuring governance and security.
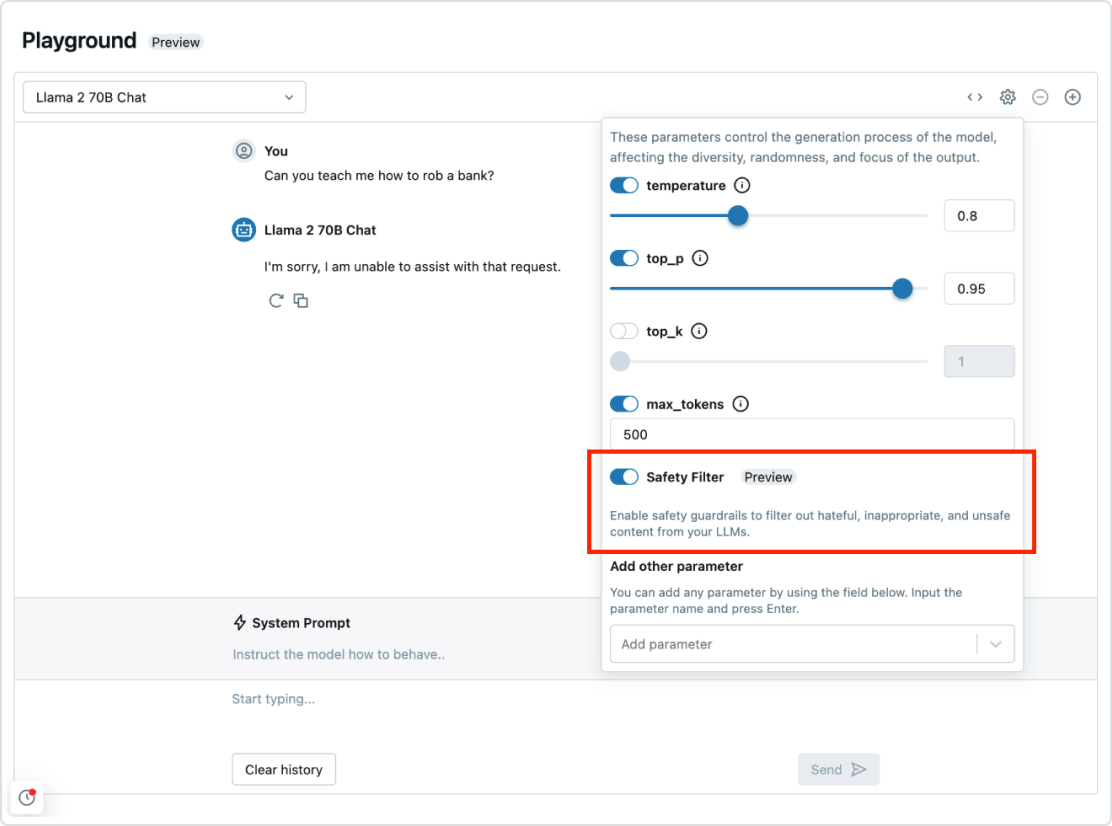
Governance and guardrails
Mosaic AI Agent Framework is seamlessly integrated with the rest of the Databricks Data Intelligence Platform. This means you have everything you need to deploy an end-to-end RAG system, from security and governance to data integration, vector databases, quality evaluation and one-click optimized deployment. With governance and guardrails in place, you can also prevent toxic responses and ensure your application follows your organization’s policies.
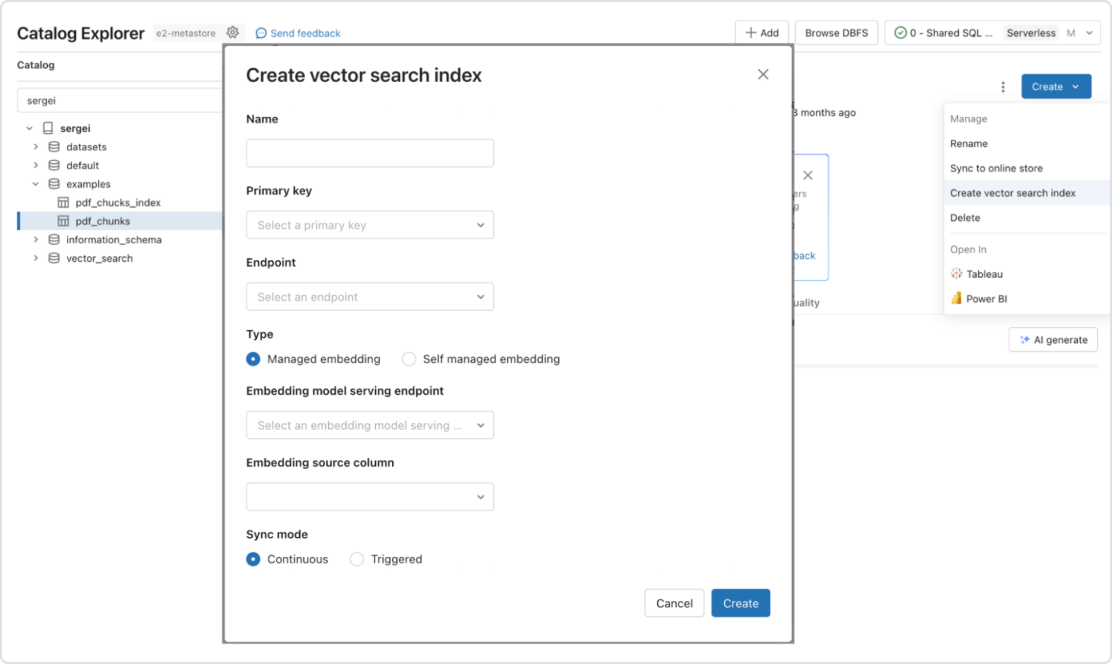
Automated real-time pipelines for any type of data
Mosaic AI natively supports serving and indexing your data for online retrieval. For unstructured data (text, images and video), Vector Search automatically indexes and serves data, making it accessible for RAG applications without needing to create separate data pipelines. Under the hood, Vector Search manages failures, handles retries and optimizes batch sizes to provide you with the best performance, throughput and cost. For structured data, Feature and Function Serving provides millisecond-scale queries of contextual data, such as user or account data, that enterprises often want to inject into prompts in order to customize them based on user information.
