Anunciando o Agrupamento Líquido Automático
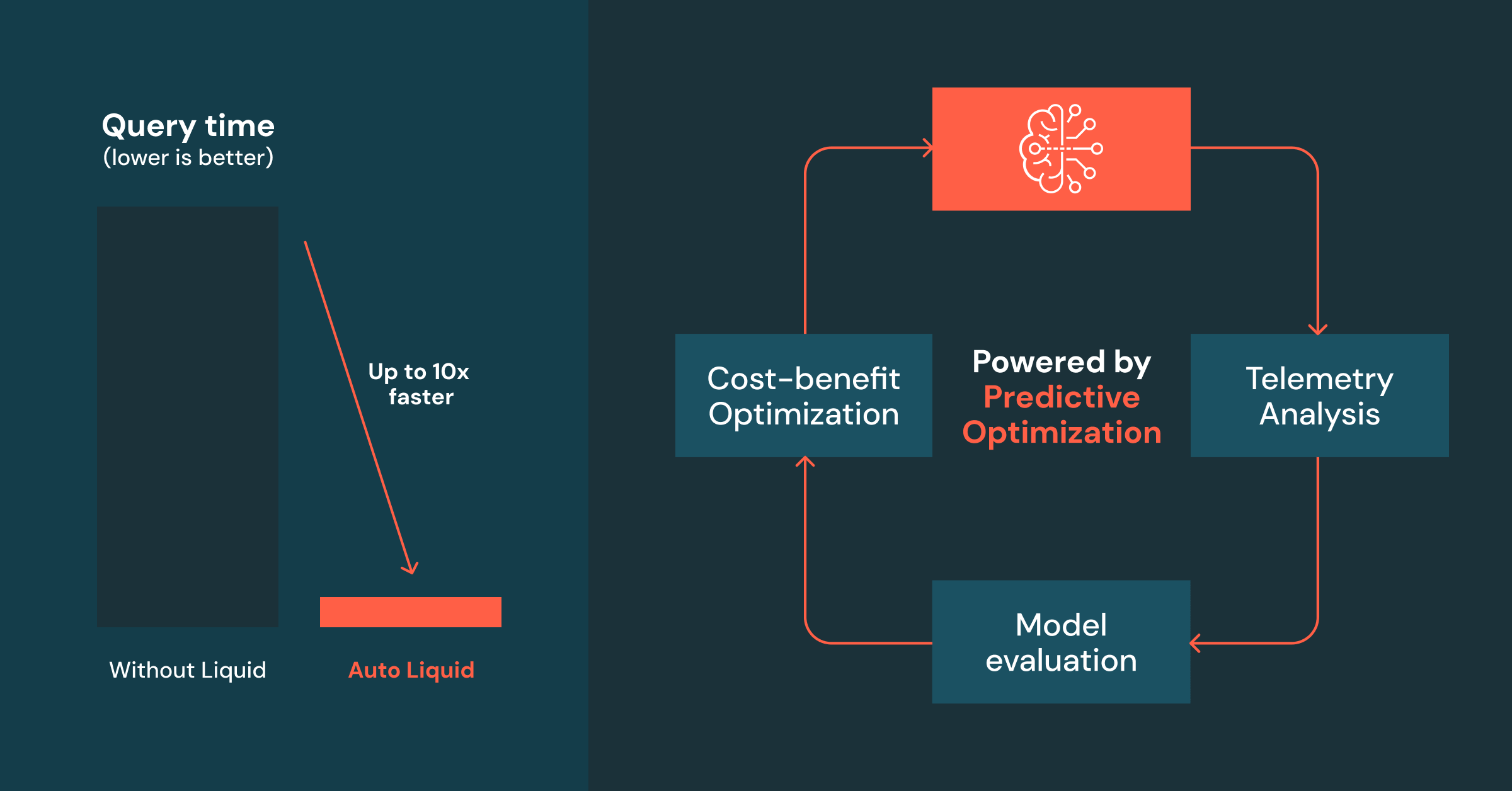
Layout de dados otimizado para consultas até 10x mais rápidas
Summary
- O Liquid Clustering Automático, alimentado pela Otimização Preditiva, automatiza a seleção de chaves de agrupamento para melhorar continuamente o desempenho da consulta e reduzir os custos.
- Processos de seleção robustos e monitoramento contínuo mantêm as tabelas otimizadas.
- O TCO é maximizado avaliando automaticamente se os ganhos de desempenho superam os custos.
Estamos animados em anunciar a Prévia Pública do Agrupamento Líquido Automático, alimentado por Otimização Preditiva. Este recurso aplica e atualiza automaticamente as colunas de Agrupamento Líquido nas tabelas gerenciadas pelo Catálogo Unity, melhorando o desempenho das consultas e reduzindo os custos.
O Agrupamento Líquido Automático simplifica a gestão de dados eliminando a necessidade de ajuste manual. Anteriormente, as equipes de dados tinham que projetar manualmente o layout específico de dados para cada uma de suas tabelas. Agora, a Otimização Preditiva utiliza o poder do Catálogo Unity para monitorar e analisar seus dados e padrões de consulta.
Para habilitar o Agrupamento Líquido Automático, configure suas tabelas UC gerenciadas não particionadas ou Líquidas definindo o parâmetro CLUSTER BY AUTO.
Uma vez ativada, a Otimização Preditiva analisa como suas tabelas são consultadas e seleciona inteligentemente as chaves de agrupamento mais eficazes com base em sua carga de trabalho. Ele então agrupa a tabela automaticamente, garantindo que os dados estejam organizados para um desempenho de consulta otimizado. Qualquer motor que leia da tabela Delta se beneficia dessas melhorias, levando a consultas significativamente mais rápidas. Além disso, à medida que os padrões de consulta mudam, a Otimização Preditiva ajusta dinamicamente o esquema de agrupamento, eliminando completamente a necessidade de ajuste manual ou decisões de layout de dados ao configurar suas tabelas Delta.
Durante a Prévia Privada, dezenas de clientes testaram o Agrupamento Líquido Automático e obtiveram resultados sólidos. Muitos apreciaram sua simplicidade e ganhos de desempenho, com alguns já o utilizando para suas tabelas de ouro e planejando expandi-lo para todas as tabelas Delta.
Clientes em pré-visualização como a Healthrise relataram melhoria significativa no desempenho das consultas com o Agrupamento Líquido Automático:
“Implantamos o Agrupamento Líquido Automático em todas as nossas tabelas de ouro. Desde então, nossas consultas passaram a ser até 10 vezes mais rápidas. Todas as nossas cargas de trabalho se tornaram muito mais eficientes sem nenhum trabalho manual necessário para projetar o layout dos dados ou realizar manutenção.” — Li Zou, Engenheiro Principal de Dados, Brian Allee, Diretor, Serviços de Dados | Tecnologia & Análise, Healthrise
Escolher o melhor layout de dados é um problema difícil
Aplicar o melhor layout de dados às suas tabelas melhora significativamente o desempenho das consultas e a eficiência de custos. Tradicionalmente, com a partição, os clientes acharam difícil projetar a estratégia de partição correta para evitar desequilíbrios de dados e conflitos de concorrência. Para melhorar ainda mais o desempenho, os clientes podem usar ZORDER em cima da partição, mas o ZORDERing é caro e ainda mais complicado de gerenciar.
Agrupamento Líquido simplifica significativamente as decisões relacionadas ao layout de dados e oferece a flexibilidade para redefinir chaves de agrupamento sem reescritas de dados. Os clientes só precisam escolher chaves de agrupamento baseadas puramente em padrões de acesso à consulta, sem ter que se preocupar com cardinalidade, ordem de chave, tamanho do arquivo, possível desequilíbrio de dados, concorrência e mudanças futuras no padrão de acesso. Trabalhamos com milhares de clientes que se beneficiaram de um melhor desempenho de consulta com o Liquid Clustering, e agora temos mais de 3000 clientes ativos mensalmente escrevendo mais de 200 PB de dados em tabelas agrupadas por Liquid por mês.
No entanto, mesmo com os avanços no Agrupamento Líquido, você ainda precisa escolher as colunas para agrupar com base em como consulta sua tabela. As equipes de dados precisam descobrir:
- Quais tabelas se beneficiarão do Agrupamento Líquido?
- Quais são as melhores colunas de agrupamento para esta tabela?
- E se os padrões da minha consulta mudarem à medida que as necessidades do negócio evoluem?
Além disso, dentro de uma organização, os engenheiros de dados frequentemente têm que trabalhar com vários consumidores a jusante para entender como as tabelas estão sendo consultadas, ao mesmo tempo que acompanham as mudanças nos padrões de acesso e nos esquemas em evolução. Este desafio se torna exponencialmente mais complexo à medida que o volume de seus dados aumenta com mais necessidades de análise.
Como o Agrupamento Automático de Líquidos evolui o layout dos seus Dados
Com o Agrupamento Líquido Automático, a Databricks cuida de todas as decisões relacionadas ao layout dos dados para você - desde a criação da tabela, ao agrupamento de seus dados e evolução do layout dos seus dados - permitindo que você se concentre em extrair insights de seus dados.
Vamos ver o Agrupamento Líquido Automático em ação com uma tabela de exemplo.
Considere uma tabela example_tbl, que é frequentemente consultada por data e ID do cliente. Ela contém dados de 5-6 de fevereiro e IDs de clientes de A a F. Sem qualquer configuração de layout de dados, os dados são armazenados na ordem de inserção, resultando no seguinte layout:
Suponha que o cliente execute SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B'. O mecanismo de consulta utiliza estatísticas de salto de dados Delta (valores mín/máx, contagens nulas e registros totais por arquivo) para identificar os arquivos relevantes para a varredura. A poda de leituras de arquivos desnecessárias é crucial, pois reduz o número de arquivos verificados durante a execução da consulta, melhorando diretamente o desempenho da consulta e reduzindo os custos de computação. Quanto menos arquivos uma consulta precisa ler, mais rápida e eficiente ela se torna.
Neste caso, o motor identifica 5 arquivos para 5 de fevereiro, já que metade dos arquivos tem um valor mínimo/máximo para a coluna data que corresponde a essa data. No entanto, como as estatísticas de omissão de dados fornecem apenas valores mínimos/máximos, esses 5 arquivos têm todos um mínimo/máximo customer_id que sugere que o cliente B está em algum lugar no meio. Como resultado, a consulta deve analisar todos os 5 arquivos para extrair entradas para o cliente B , resultando em uma taxa de poda de arquivo de 50% (lendo 5 de 10 arquivos).
Como você vê, o problema central é que os dados do cliente Bnão estão co-localizados em um único arquivo. Isso significa que extrair todas as entradas para o cliente B também requer a leitura de uma quantidade significativa de entradas para outros clientes.
Existe uma maneira de melhorar a poda de arquivos e o desempenho das consultas aqui? O Liquid Clustering Automático pode melhorar ambos. Veja como:
Por Trás das Cenas do Agrupamento Líquido Automático: Como Funciona
Uma vez ativado, o Liquid Clustering Automático executa continuamente as seguintes três etapas:
- Coletando telemetria para determinar se a tabela se beneficiará da introdução ou evolução das Chaves de Agrupamento Liquid.
- Modelando a carga de trabalho para entender e identificar colunas elegíveis.
- Aplicando a seleção de coluna e evoluindo os esquemas de agrupamento com base na análise de custo-benefício.

Etapa 1: Análise de Telemetria
A Otimização Preditiva coleta e analisa estatísticas de varredura de consulta, como predicados de consulta e filtros JOIN, para determinar se uma tabela se beneficiaria do Liquid Clustering.
Com nosso exemplo, a Otimização Preditiva detecta que as colunas ‘date’ e ‘customer_id’ são frequentemente consultadas.
Passo 2: Modelagem de Carga de Trabalho
A Otimização Preditiva avalia a carga de trabalho da consulta e identifica as melhores chaves de agrupamento para maximizar a omissão de dados.
Ele aprende com os padrões de consulta passados e estima os ganhos de desempenho potenciais de diferentes esquemas de agrupamento. Ao simular consultas passadas, ele prevê quão efetivamente cada opção iria reduzir a quantidade de dados escaneados.
Em nosso exemplo, usando varreduras registradas em ‘data’ e ‘customer_id’ e assumindo consultas consistentes, a Otimização Preditiva calcula que:
- Agrupar por
‘data’lê 5 arquivos com taxas de poda de 50%. - Agrupando por
‘customer_id’, lê ~2 arquivos (uma estimativa) com uma taxa de poda de 80%.- Agrupando por
‘data’e‘customer_id’(veja o layout de dados abaixo) lê apenas 1 arquivo com uma taxa de poda de 90%.
- Agrupando por
Passo 3: Otimização de Custo-benefício
A Plataforma Databricks garante que quaisquer alterações nas chaves de agrupamento proporcionem um claro benefício de desempenho, pois o agrupamento pode introduzir sobrecarga adicional. Uma vez que novos candidatos a chave de agrupamento são identificados, a Otimização Preditiva avalia se os ganhos de desempenho superam os custos. Se os benefícios forem significativos, ele atualiza as chaves de agrupamento nas tabelas gerenciadas pelo Catálogo Unity.
Em nosso exemplo, agrupar por 'data' e 'customer_id' resulta em uma taxa de poda de dados de 90%. Como essas colunas são frequentemente consultadas, os custos de computação reduzidos e o desempenho melhorado das consultas justificam o overhead do agrupamento.
Clientes em pré-visualização destacaram a eficiência de custo da Otimização Preditiva, particularmente seu baixo custo operacional em comparação com a criação manual de layouts de dados. Empresas como a CFC Underwriting relataram um menor custo total de propriedade e ganhos significativos de eficiência.
“Nós realmente amamos o Agrupamento Líquido Automático da Databricks porque nos dá a tranquilidade de que temos o layout de dados mais otimizado de fábrica. Ele também nos poupou muito tempo ao eliminar a necessidade de ter um engenheiro para manter o layout de dados. Graças a essa capacidade, notamos que nossos custos de computação diminuíram mesmo enquanto aumentamos nosso volume de dados.” — Nikos Balanis, Chefe da Plataforma de Dados, CFC
A capacidade em resumo: A Otimização Preditiva escolhe as chaves de agrupamento líquido em seu nome, de modo que a economia de custos prevista com a omissão de dados supere o custo previsto do agrupamento.
Comece hoje
Se você ainda não ativou a Otimização Preditiva, pode fazê-lo selecionando Ativado ao lado de Otimização Preditiva no console da conta em Configurações > Habilitação de recursos.
Ainda não conhece a Databricks? Desde 11 de novembro de 2024, a Databricks habilitou a Otimização Preditiva por padrão em todas as novas contas da Databricks, executando otimizações para todas as suas tabelas gerenciadas pelo Catálogo Unity.
Comece hoje definindo CLUSTER BY AUTO em suas tabelas gerenciadas pelo Catálogo Unity. Databricks Runtime 15.4+ é necessário para CRIAR novas tabelas AUTO ou ALTERAR tabelas Liquid / não particionadas existentes. Em um futuro próximo, o Liquid Clustering Automático será ativado por padrão para as novas tabelas gerenciadas pelo Catálogo Unity. Fique ligado para mais detalhes.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Produto
June 12, 2024/11 min de leitura
