Construindo Pipelines de Geração de Dados Sintéticos Escaláveis para Percepção de IA com Databricks e NVIDIA Omniverse
Summary
- A integração da Plataforma de Inteligência de Dados NVIDIA Omniverse e Databricks combina a criação de dados sintéticos com as capacidades de IA empresarial em uma arquitetura simples de implantar e fácil de manter.
- Com o NVIDIA Omniverse Replicator, os usuários do Databricks podem aproveitar simulações de alta fidelidade e precisas em física para parametrizar dados gerados sinteticamente para o treinamento de modelos de visão.
Treinar modelos de IA para aplicações do mundo real requer grandes quantidades de dados rotulados, o que pode ser caro, demorado e difícil de obter em larga escala. A geração de dados sintéticos em ambientes simulados oferece uma poderosa alternativa, permitindo que os modelos de IA aprendam com conjuntos de dados virtuais precisos, controlados e escaláveis antes da implantação.
Aproveitando o Omniverse Replicator, uma extensão central do Isaac Sim, uma aplicação de simulação robótica de referência, com a Plataforma de Inteligência de Dados do Databricks, fornece um fluxo de trabalho de ponta a ponta para o desenvolvimento de modelos de IA específicos do domínio em indústrias como manufatura, logística, diagnósticos de saúde e robótica. Ao combinar a geração de dados sintéticos, fluxos de trabalho de IA automatizados e infraestrutura em nuvem escalável, as organizações podem acelerar o desenvolvimento de IA, reduzindo os desafios de aquisição de dados e melhorando a precisão do modelo.
Este blog explora as bases técnicas desta integração, aplicações no mundo real e demonstra como a colaboração entre Databricks e NVIDIA está impulsionando aplicações de visão de máquina. Ao fundir a Plataforma de Inteligência de Dados do Databricks com a computação de alto desempenho incomparável da NVIDIA, as empresas agora podem construir, treinar e implantar modelos de visão em velocidades anteriormente consideradas impossíveis. Este blog explora as bases técnicas desta integração e suas aplicações no mundo real.
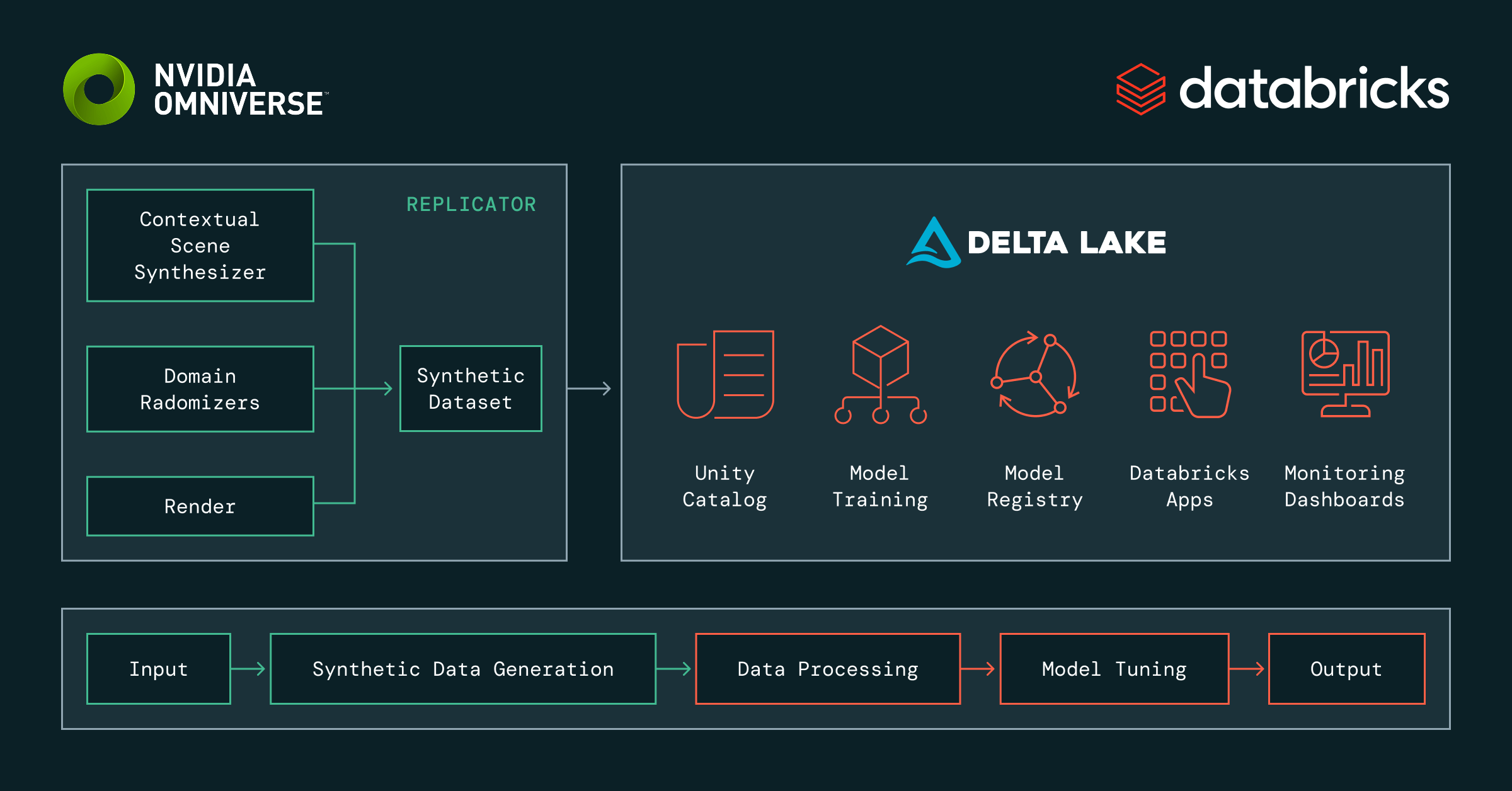
Padrões de Arquitetura
As bases técnicas da integração começam com uma arquitetura de referência que define interfaces, modelos de dados e protocolos de comunicação. Abaixo está um fluxo de trabalho generalizado que demonstra a integração de aplicações desenvolvidas com NVIDIA Omniverse e a Plataforma de Inteligência de Dados Databricks para fornecer um pipeline de treinamento de modelo de IA de ponta a ponta.
Os passos dentro do fluxo de trabalho são os seguintes:
- Forneça dados de entrada iniciais e parâmetros para definir a geração de dados sintéticos
- Exemplo: Artefatos 3D de um objeto e descrições de cena de iluminação específica com parâmetros de randomização e variabilidade para mostrar a variação esperada.
- Gere dados sintéticos com Omniverse Replicator para Isaac Sim.
- Exemplo: Gerar imagens de diferentes variações de um objeto CAD específico capturado em diferentes ângulos.
- Processe os dados em um formato Lakehouse, como Delta Lake, para preparar para o Treinamento de Modelo de IA Mosaic.
- Exemplo: Configure os Pipelines Lakeflow do Databricks para transformar e harmonizar o conjunto de dados e associar metadados para contexto adicional.
- Treine/afine modelos para casos de uso específicos do domínio no Databricks
- Exemplo: Rastreamento de experimentos em várias execuções de treinamento de modelo para o modelo de visão de máquina You Only Look Once (YOLO). Armazene modelos no Catálogo Unity da Databricks para governança de modelo ao longo do ciclo de vida do MLOps.
- Sirva os modelos específicos do domínio para inferência em pipelines, aplicações e fluxos de trabalho.
- Exemplo: Registre modelos no Catálogo Unity do Databricks e sirva em pontos finais de Serviço de Modelo do Databricks fáceis de implantar.
Dentro desta arquitetura, o Delta Lake é usado como a camada de integração entre NVIDIA Omniverse e Databricks. Fazemos a ponte entre as duas plataformas aproveitando um protótipo, escritor personalizado, que permite que uma aplicação desenvolvida com Omniverse escreva dados sintéticos diretamente no Lakehouse. Usando essa abordagem, em vez de escrever os dados em disco na forma de arquivos PNG e NumPy, as aplicações alimentadas por Omniverse podem escrever as imagens sintéticas geradas e os metadados correspondentes no formato Delta Lake. Os arquivos são enviados diretamente para o armazenamento em nuvem e são registrados no Catálogo Unity, onde são processados usando o Databricks para que estejam disponíveis para o treinamento do modelo downstream.
Um Novo Padrão para MLOps de Visão de Máquina
A integração entre NVIDIA Omniverse e Databricks estabelece um novo paradigma para o desenvolvimento de visão de máquina, abrangendo a geração de dados sintéticos e a IA de grau industrial fácil de usar. Dentro de ambientes de fabricação, os modelos de detecção de defeitos geralmente encontram três desafios principais: identificar novos defeitos, adaptar-se a novos produtos e atuar em diversos ambientes do mundo real.
Para enfrentar esses desafios, a plataforma NVIDIA Omniverse permite aos clientes construir pipelines de geração sintética personalizados. NVIDIA Omniverse permite que os desenvolvedores criem ângulos de câmera totalmente novos, condições de iluminação e cenários físicos em suas aplicações, aumentando significativamente a robustez e adaptabilidade do modelo além dos métodos tradicionais, como girar ou clarear imagens.
Ao automatizar a geração de imagens, o processo de geração de dados sintéticos se torna um parâmetro ajustável dentro do MLflow Gerenciado do Databricks. Esses ajustes podem ser feitos juntamente com hiperparâmetros tradicionais como taxa de aprendizado e tamanho do lote. À medida que você identifica quais variações impactam a precisão do modelo, você pode refinar sua abordagem de treinamento para se concentrar nas combinações mais eficazes de dados sintéticos e hiperparâmetros, minimizando o tempo gasto em configurações menos produtivas.
Desbloqueando Novos Casos de Uso
Ao ter dados sintéticos como um parâmetro ajustável, novos casos de uso são desbloqueados para fabricantes sem interromper as operações reais:
- Detecção de Defeitos no Controle de Qualidade de Manufatura - Os modelos de visão de máquina prontos para uso só conseguem reconhecer objetos com base nos dados do mundo real em que foram treinados. Com este fluxo de trabalho, os fabricantes agora podem gerar sem problemas imagens sintéticas que compreendem vários defeitos, como corrosão, textura, fratura capilar, ou variações de características físicas de cor/tamanho usando os modelos CAD 3D de seus produtos, permitindo que as empresas ajustem os modelos e os sirvam no Databricks para detectar defeitos antes do envio dos produtos.
- Design de Produto Generativo - Antes que os produtos passem do conceito à produção, as equipes de design criam primeiramente renderizações 3D detalhadas do que a realidade parecerá em ferramentas de software CAD. Usando esses mesmos designs ao lado do Omniverse Replicator, agora podemos gerar os dados sintéticos necessários para permitir que os modelos de design generativo sejam ajustados no Databricks, possibilitando a exploração do espaço de design muito antes do início da fabricação física. Esta abordagem integrada ajudará os fabricantes a gerar soluções de design viáveis e otimizadas (representadas como modelos 2D/3D) a partir de um conjunto dado de requisitos e prever seu desempenho mais rápido do que os estudos de simulação tradicionais. Graças às capacidades de DevOps e agendamento do Databricks, tais processos podem ser acionados e executados juntos como um pipeline de ponta a ponta (por exemplo, quando uma nova versão da representação CAD está disponível).
- Propriocepção de Robótica e Automação - Os desenvolvedores podem integrar o Replicador Omniverse em seu fluxo de trabalho para gerar conjuntos de dados sintéticos que abrangem inúmeras configurações de ambiente, ângulos de câmera e cenários de iluminação. Os fabricantes de robótica podem usar o Databricks para armazenar várias imagens de pontos de vista de cenas OpenUSD e executar experimentos de ajuste de modelo paralelos e distribuídos para desenvolver rapidamente uma melhor compreensão da IA de movimentos específicos do braço robótico em ambientes de fabricação específicos.
Essas abordagens permitem que os fabricantes treinem uma variedade mais ampla de modelos de visão de máquina para resolver problemas de negócios de forma proativa. Defeitos raros com dados que anteriormente eram muito escassos para treinar agora podem ser aumentados com numerosos exemplos realistas, permitindo que as empresas detectem defeitos antes que eles escapem enquanto preparam as empresas para a nova era da Inteligência de Dados.
Resolvendo as Lacunas de Dados de uma Empresa de Saúde
Siemens Healthineers, um cliente de saúde conjunto da Databricks e NVIDIA inspirou esta arquitetura de integração após enfrentar desafios. O fluxo de trabalho fragmentado - com um engenheiro gerando dados sintéticos através de uma aplicação desenvolvida com NVIDIA Omniverse no local e outro movendo esses dados para a nuvem para treinamento e implantação de ML no Databricks - criou atrasos.
Ao implementar o Catálogo Unity do Databricks para centralizar todos os dados, funções e modelos sob um único framework de governança e integrar diretamente as capacidades de geração de dados sintéticos da plataforma Omniverse, a organização reduziu drasticamente os ciclos de iteração do modelo "de semanas para dias", melhorou a integração e rastreabilidade de dados e acelerou o tempo de entrada no mercado.
Se você estiver participando da NVIDIA GTC 2025, visite-nos em nosso estande Databricks #1733 ou solicite uma reunião com a Databricks na GTC.
Para mais informações sobre NVIDIA Omniverse e a Plataforma de Inteligência de Dados Databrick, consulte os recursos adicionais abaixo:
- Omniverse Replicator é criado como uma extensão do Omniverse Kit e convenientemente distribuído através do Omniverse Code.
- Se você nunca usou a Plataforma de Inteligência Databricks na prática, inscreva-se para uma conta de teste gratuita. Você também pode encontrar uma lista completa de ofertas da Academia Databricks, treinamentos e certificações.
Site da NVIDIA Omniverse
Site da Plataforma de Inteligência de Dados Databricks
Anúncio de Parceria Databricks <> NVDA
Documentação de ML Ops da Databricks
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Energia
October 13, 2025/7 min de leitura
