Curando Identidades de Clientes de Alta Qualidade com Databricks e Amperity

Summary
- A Resolução de Identidade (IDR) é essencial para insights do cliente - Ela ajuda a unificar interações fragmentadas do cliente (online, na loja, e-mail, anúncios) em uma única identidade, permitindo previsões precisas para churn, personalização e detecção de fraude.
- A integração Databricks + Amperity simplifica o IDR - Usando o Delta Sharing, automação de IA e mais de 45 algoritmos de correspondência, o motor de Resolução de Identidade da Amperity mescla registros de clientes em um gráfico de identidade unificado, acessível no Databricks.
- Impacto comercial do IDR - Dados unificados do cliente melhoram o marketing personalizado, a variedade de produtos, a colocação na loja, a detecção de fraude e até mesmo insights de RH, levando a uma melhor tomada de decisão e engajamento do cliente.
Quando pensamos em casos de uso como recomendações de produtos, previsões de churn, atribuição de publicidade e detecção de fraude, um denominador comum é que todos eles exigem que identifiquemos consistentemente nossos clientes em várias interações. Falhar em reconhecer que a mesma pessoa está navegando online, comprando na loja, abrindo um e-mail de marketing e clicando em um anúncio, nos deixa com uma visão incompleta do cliente, limitando nossa capacidade de reconhecer suas necessidades, preferências e prever seu comportamento futuro.
Apesar de sua importância, identificar com precisão o cliente em todas essas interações é incrivelmente difícil. As pessoas frequentemente interagem conosco sem fornecer detalhes explícitos de identificação e, quando o fazem, esses detalhes nem sempre são consistentes. Por exemplo, se um cliente faz uma compra usando um cartão de crédito no nome de Jennifer, se inscreve no programa de fidelidade como Jenny com um e-mail pessoal, e clica em um anúncio online vinculado ao seu e-mail de trabalho, essas interações podem parecer como três clientes separados, mesmo que todos pertençam à mesma pessoa (Figura 1).
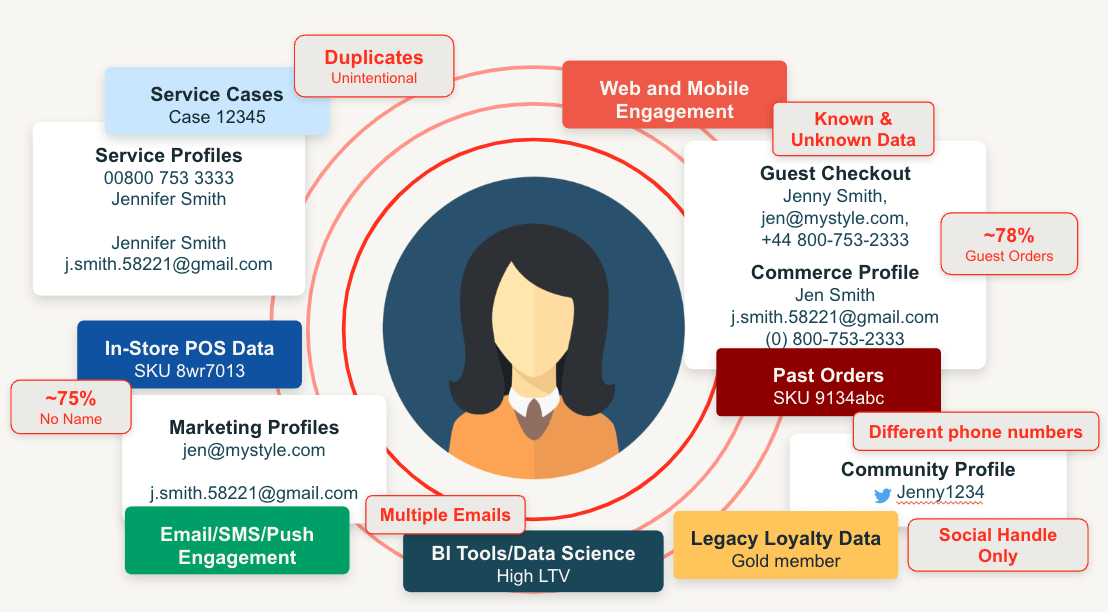
Embora resolver isso para um único cliente seja desafiador, a verdadeira complexidade reside em abordá-lo para centenas de milhares, ou até milhões, de clientes únicos com os quais os varejistas se envolvem continuamente. Além disso, os detalhes do cliente não são estáticos - à medida que novos comportamentos, identificadores e relações familiares surgem, nossa compreensão de quem é o cliente deve continuar a evoluir também.
Resolução de identidade (IDR) é o termo que usamos para descrever as técnicas usadas para juntar todos esses detalhes para chegar a uma visão unificada de cada cliente. A IDR eficaz é crucial, pois possibilita e afeta todos os nossos processos centrados nos clientes, como o marketing personalizado, por exemplo.
Entendendo o Processo de Resolução de Identidade
Em muitos cenários, a identidade do cliente é estabelecida através de dados que chamamos de informações pessoalmente identificáveis (PII). Primeiros nomes, sobrenomes, endereços postais, endereços de e-mail, números de telefone, números de conta, etc. são todos pedaços comuns de PII coletados através de nossas interações com clientes.
Usando bits sobrepostos de PII, podemos tentar combinar e mesclar alguns registros diferentes para um indivíduo, no entanto, são permitidos diferentes graus de incerteza dependendo do tipo de PII. Por exemplo, podemos usar técnicas de normalização para endereços de e-mail ou números de telefone digitados incorretamente, e técnicas de correspondência aproximada para variações de nomes (por exemplo, Jennifer vs Jenny vs Jen) (Figura 2).

No entanto, muitas vezes existem situações em que não temos PII sobrepostos. Por exemplo, um cliente pode ter fornecido seu nome e endereço postal em um registro, seu nome e endereço de e-mail em outro, e um número de telefone e o mesmo endereço de e-mail em um terceiro registro. Por associação, podemos deduzir que todas essas são a mesma pessoa, dependendo da nossa tolerância para incerteza (Figura 3).
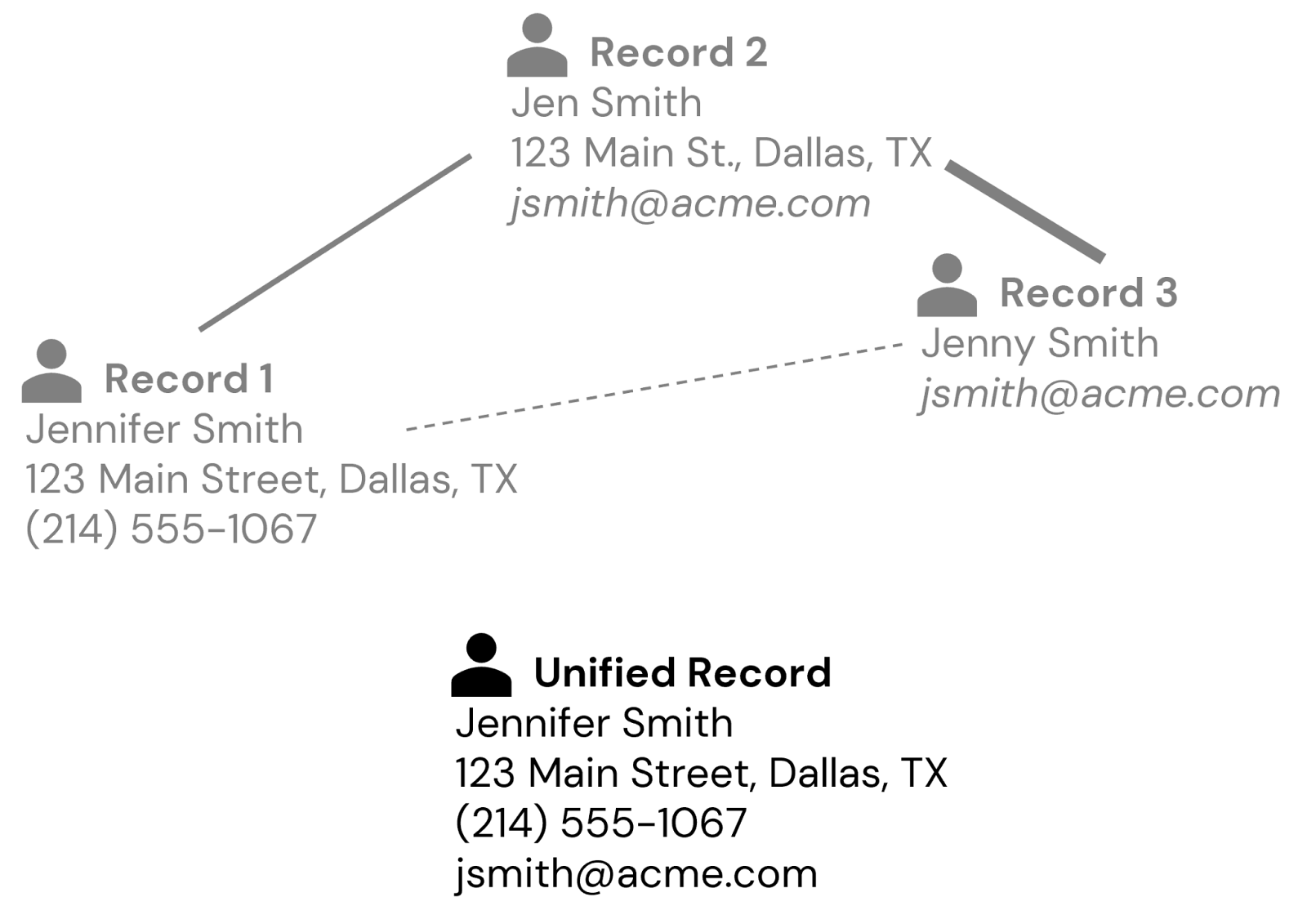
O cerne do processo de IDR reside em vincular registros combinando regras de correspondência exata e técnicas de correspondência difusa, adaptadas a diferentes elementos de dados, para estabelecer uma identidade de cliente unificada. O resultado é uma compreensão probabilística de quem são seus clientes que evolui à medida que novos detalhes são coletados e incorporados ao gráfico de identidade.
Construindo o Gráfico de Identidade
O desafio de construir e manter um gráfico de identidade do cliente é facilitado pela integração do Databricks com o motor de Resolução de Identidade da Amperity. Amplamente reconhecida como a principal solução de IDR de primeira parte do mundo, a Amperity utiliza mais de 45 algoritmos para combinar e mesclar registros de clientes. A integração pronta para uso permite que os clientes do Databricks compartilhem seus dados com a Amperity e obtenham insights detalhados sobre como uma coleção de registros de clientes se resolve em identidades unificadas. (Figura 4).
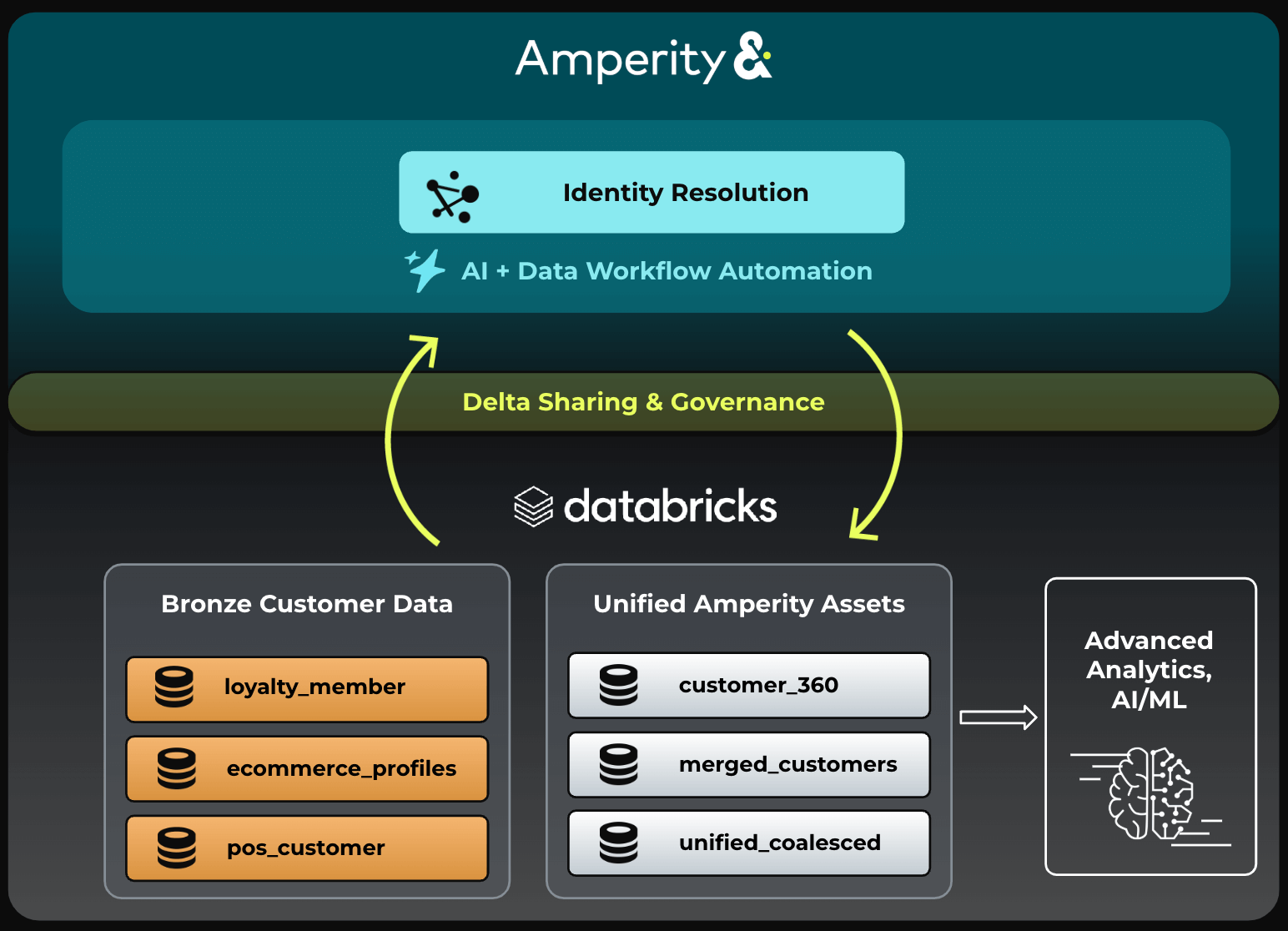
O processo de configuração desta integração e execução do IDR na Amperity é muito simples:
- Configure uma conexão Delta Sharing com Databricks via a Ponte Amperity
- Use a automação de IA para marcar vários elementos PII nos dados compartilhados
- Execute o algoritmo Stitch da Amperity para montar o gráfico IDR
- Mapeie a saída resultante para um catálogo Databricks
- Atualize o gráfico conforme necessário
Um guia detalhado para essas etapas pode ser encontrado no Guia Rápido de Início da Resolução de Identidade da Amperity, e um vídeo explicativo do processo pode ser visto aqui:
Empregando o Gráfico de Identidade
O resultado final da integração é um conjunto de tabelas relacionadas que incluem elementos unificados do cliente e sugestões para informações de identidade preferidas para cada cliente (Figura 5).
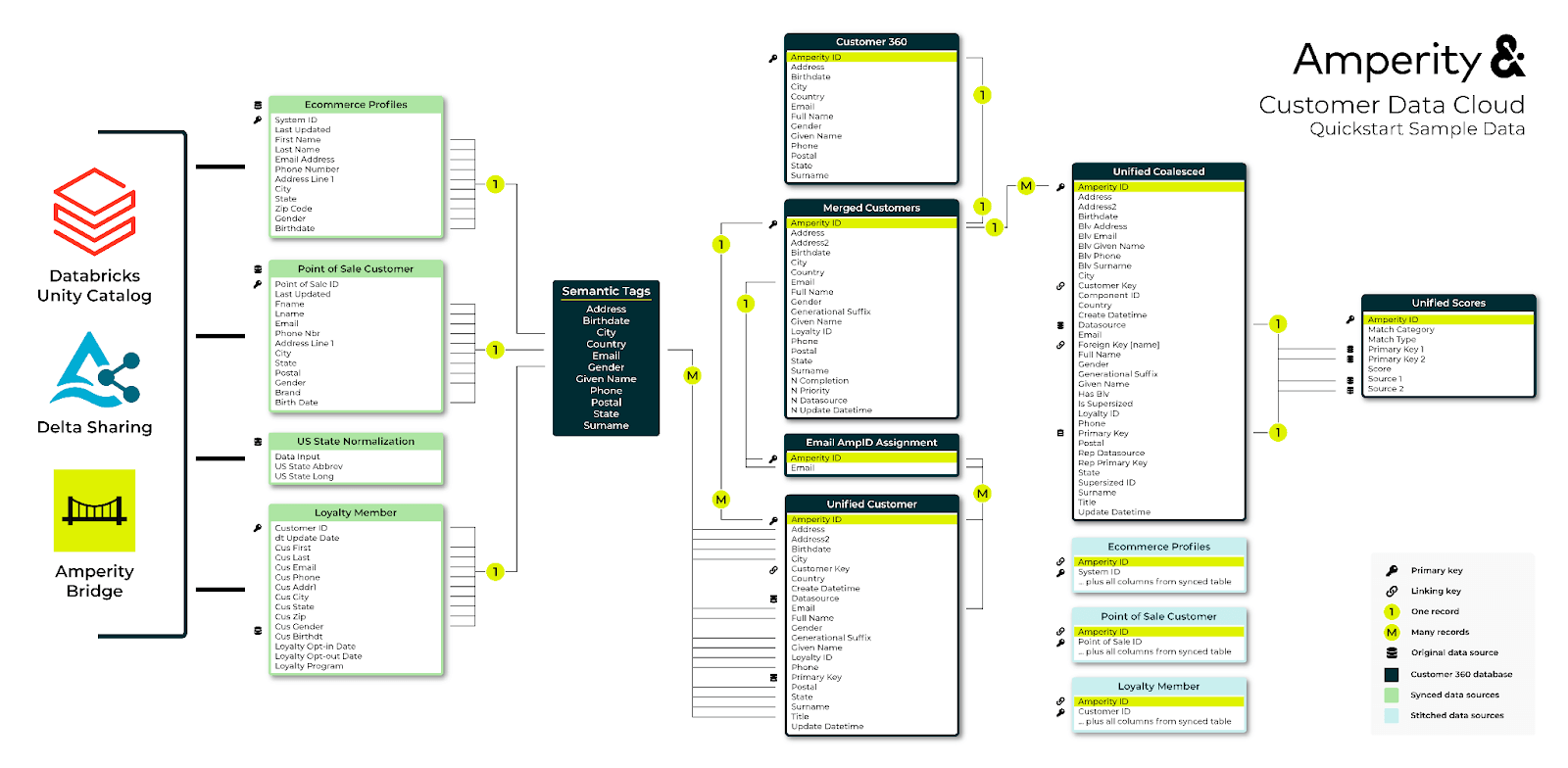
Engenheiros de dados, cientistas de dados, desenvolvedores de aplicativos podem aproveitar os dados resultantes no Databricks para construir uma ampla gama de soluções para atender às necessidades e casos de uso comuns da empresa:
- Insights do Cliente: Sendo capaz de vincular registros de dados do cliente, tanto internos quanto externos, as organizações podem desenvolver insights mais profundos e precisos sobre comportamentos e preferências do cliente.
- Marketing Personalizado & Experiências: Usando essas percepções e sendo capaz de identificar melhor os clientes à medida que eles interagem com várias plataformas, as organizações podem entregar mensagens e ofertas mais direcionadas, criando uma experiência mais personalizada.
- Sortimento de Produtos: Com uma imagem mais precisa de quem está comprando o quê, as organizações podem melhor perfilar a demografia de seus clientes em locais específicos e construir sortimentos de produtos mais propensos a ressoar com a população atendida.
- Localização da Loja: Esses mesmos insights demográficos podem ajudar as organizações a avaliar o potencial de novos locais de loja, identificando áreas onde clientes como aqueles que eles engajaram com sucesso em outras regiões residem.
- Detecção de Fraude: Ao desenvolver uma imagem mais clara de como os indivíduos se identificam, as organizações podem identificar melhor os maus atores que tentam aproveitar ofertas promocionais, contornar listas de partes bloqueadas ou usar credenciais que não lhes pertencem.
- Cenários de RH & Insights de Funcionários: E assim como com os clientes, as organizações podem desenvolver uma visão mais abrangente dos funcionários existentes ou potenciais para gerenciar melhor as práticas de recrutamento, contratação e retenção.
Começando a Unificar as Identidades dos Clientes
Se sua organização está lutando com a resolução de identidade do cliente, você pode começar com a Resolução de Identidade da Amperity fazendo inscrição para um teste gratuito de 30 dias. Antes de fazer isso, é recomendável garantir que você tenha acesso aos ativos de dados do cliente e a capacidade de configurar o compartilhamento Delta no seu ambiente Databricks. Também recomendamos que você siga as etapas no guia de início rápido usando os dados de amostra que a Amperity fornece para se familiarizar com o processo geral. Por último, você sempre pode entrar em contato com seus representantes da Databricks e da Amperity para obter mais detalhes sobre a solução e como ela pode ser aproveitada para suas necessidades específicas.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Varejo e bens de consumo
August 20, 2025/9 min de leitura
De Reserva a Bon Voyage: Como a IA está redefinindo a experiência de Viagem & Hospitalidade

Varejo e bens de consumo
August 20, 2025/6 min de leitura