
Resumo: Os LLMs revolucionaram o desenvolvimento de software ao aumentar a produtividade dos programadores. No entanto, apesar dos LLMs prontos para uso serem treinados em uma quantidade significativa de código, eles não são perfeitos. Um desafio chave para nossos clientes corporativos é a necessidade de realizar inteligência de dados, ou seja, adaptar e raciocinar usando os próprios dados de sua organização. Isso inclui ser capaz de usar conceitos de codificação específicos da organização, conhecimento e preferências. Ao mesmo tempo, queremos manter a latência e o custo baixos. Neste blog, demonstramos como o ajuste fino de um pequeno LLM de código aberto em dados de interação possibilita precisão de última geração, baixo custo e latência mínima.
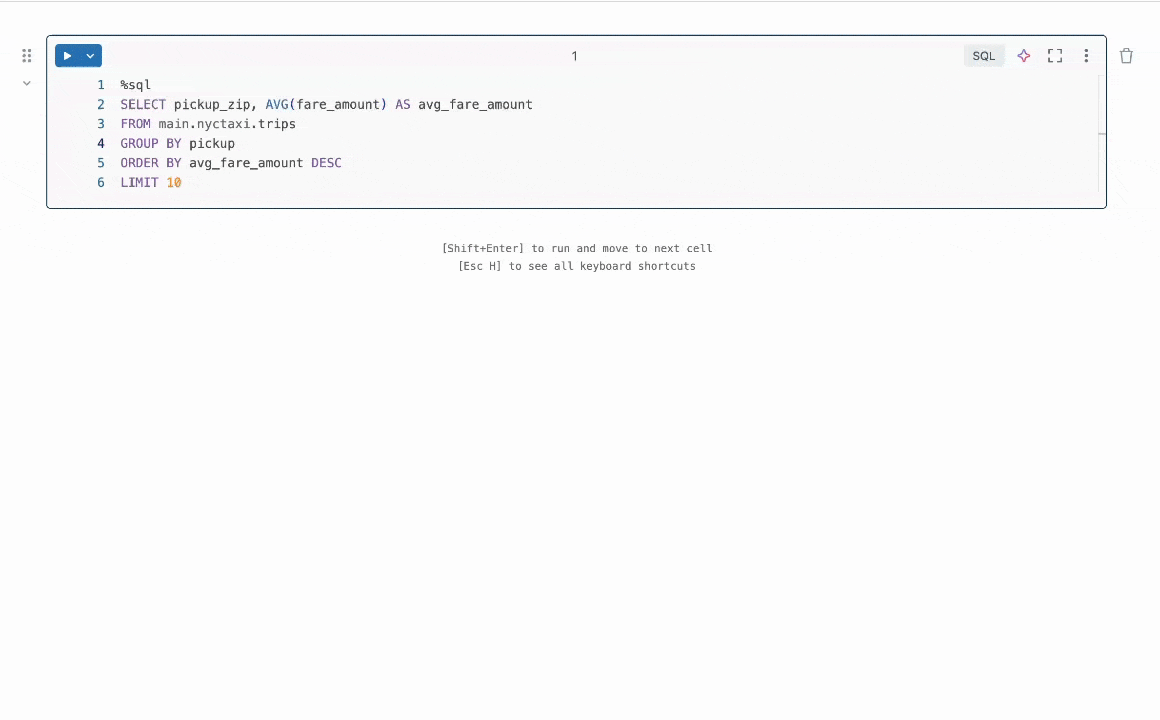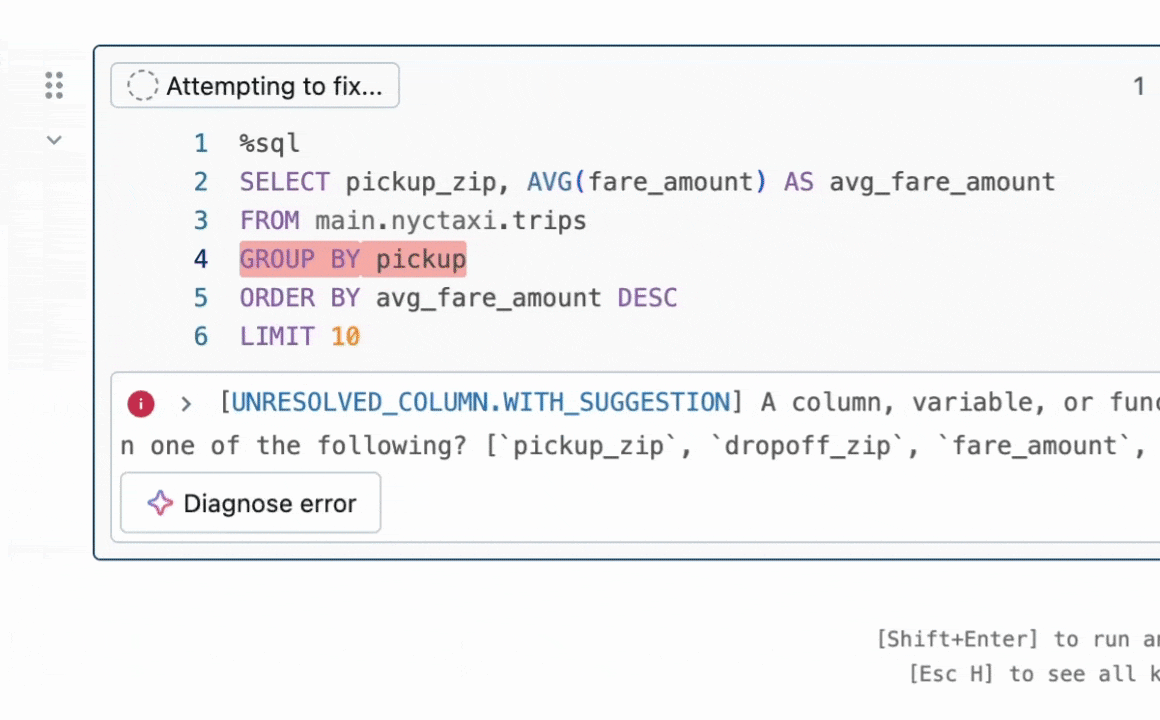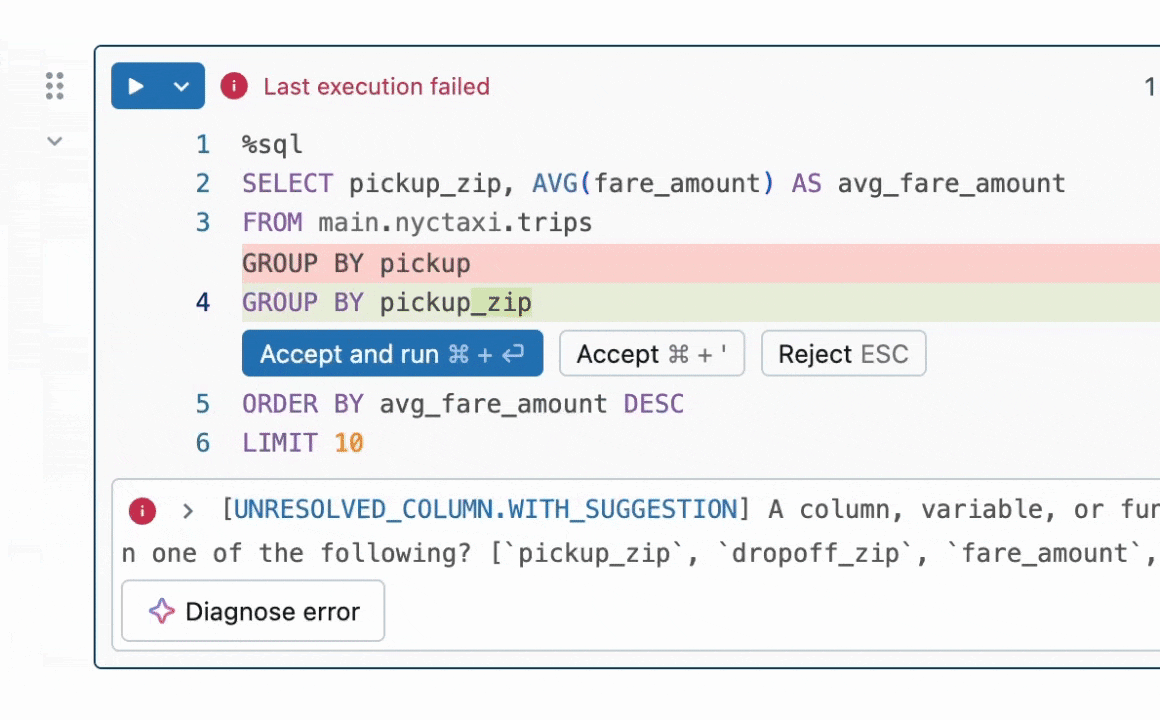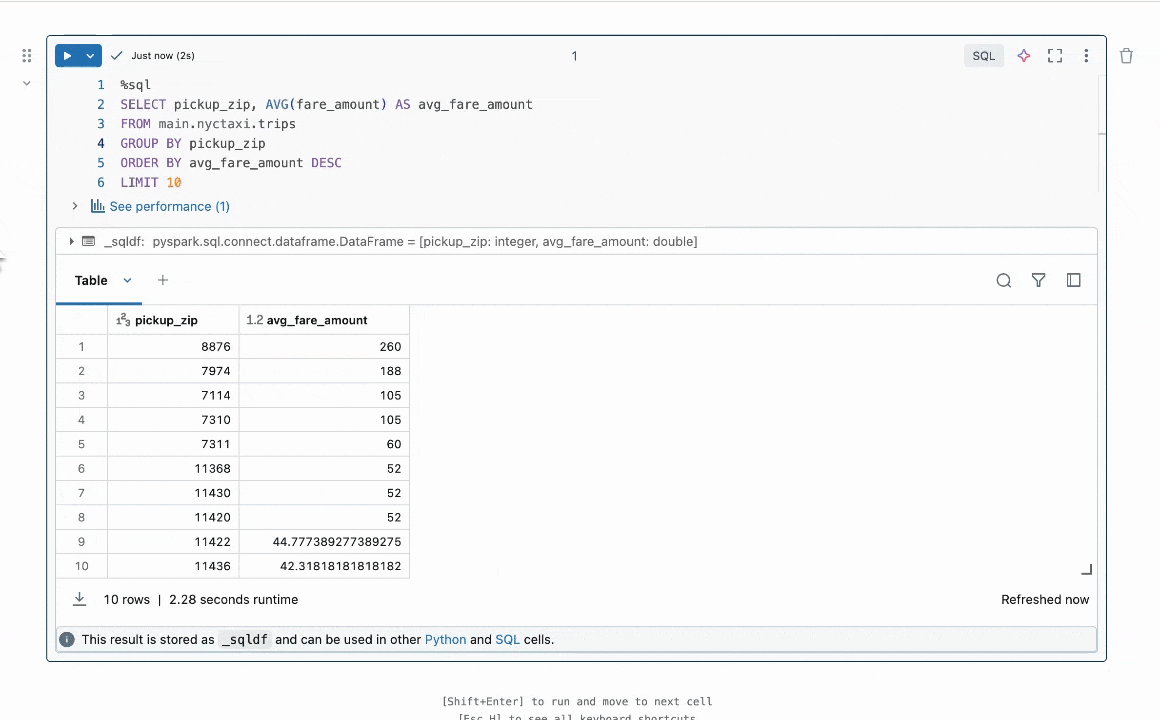
Figura 1: Quick Fix ajuda os usuários a resolver erros sugerindo correções de código em linha.
Resumo do Resultado: Nos concentramos na tarefa de reparo de programas, que requer a correção de bugs no código. Este problema tem sido amplamente estudado na literatura sem LLMs [1, 2] e mais recentemente com LLMs [3, 4]. Na indústria, agentes LLM práticos como o Databricks Quick Fix estão disponíveis. A Figura 1 mostra o agente Quick Fix em ação em um ambiente Databricks Notebook. Neste projeto, nós refinamos o modelo Llama 3.1 8b Instruct em código interno escrito por funcionários da Databricks para análise de telemetria. O modelo Llama refinado é avaliado contra outros LLMs por meio de um teste A/B ao vivo em usuários internos. Apresentamos resultados na Figura 2 mostrando que o Llama afinado alcança uma melhoria de 1.4x na taxa de aceitação em relação ao GPT-4o, enquanto alcança uma redução de 2x na latência de inferência.
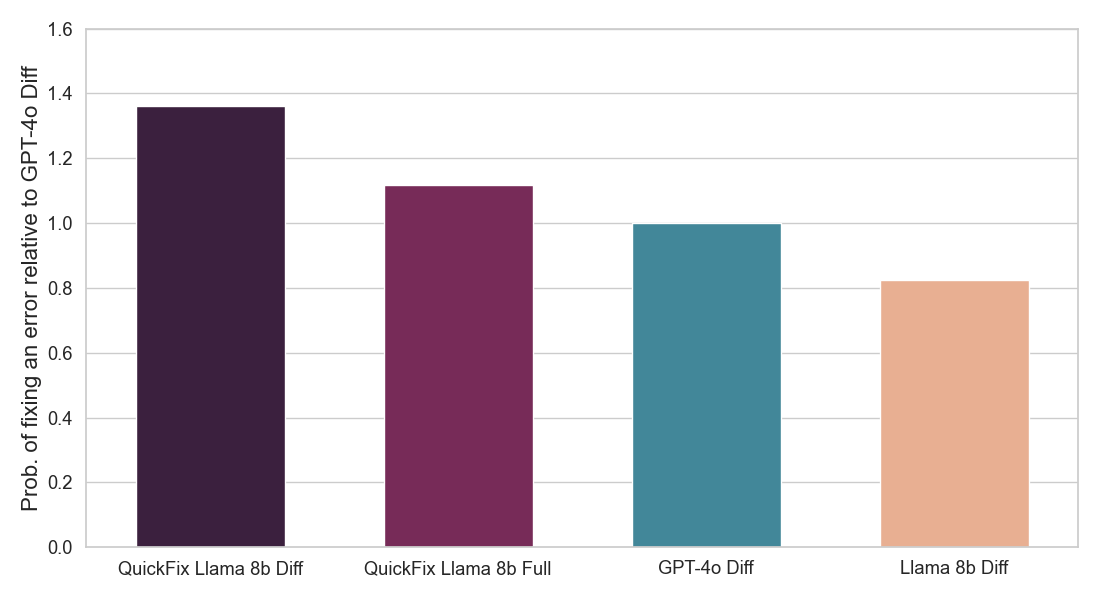
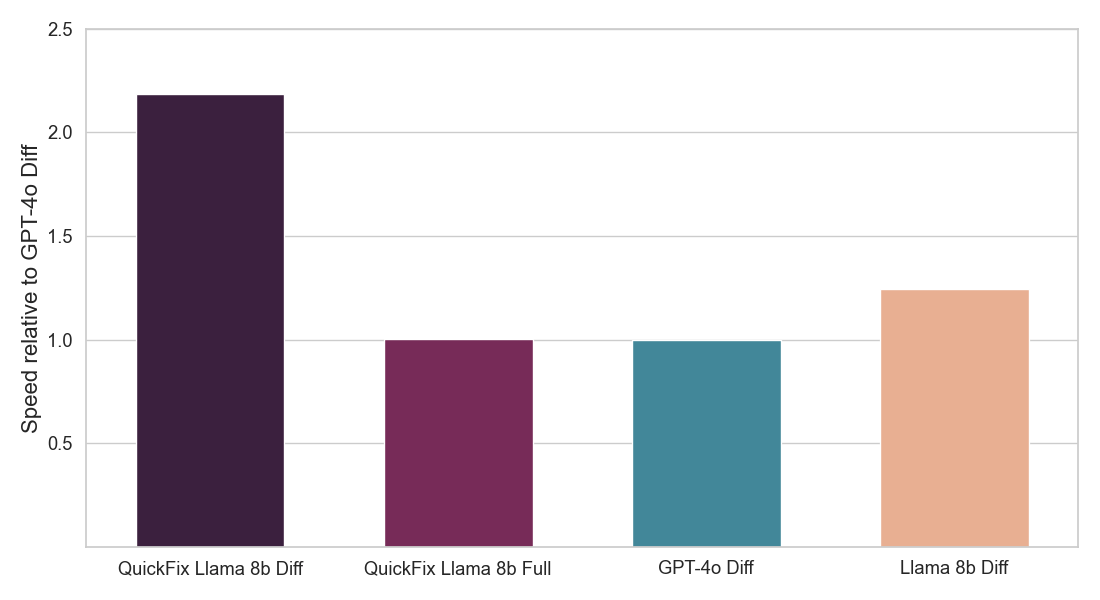
Figura 2: Mostra a fração de correções LLM propostas que foram aceitas pelos usuários (acima) e a velocidade de inferência de cada agente Quick Fix LLM (abaixo). Ambos os números são normalizados em relação ao agente GPT-4o (veja detalhes abaixo). Nosso modelo (QuickFix Llama 8b Diff) alcança a maior precisão e a menor latência. Modelos com o sufixo diff geram edições no código com bugs, enquanto aqueles com o sufixo full geram o código completo.
Por que isso importa? Muitas organizações, incluindo muitos clientes existentes da Databricks, possuem dados de uso de codificação que contêm conhecimento, conceitos e preferências internos. Com base em nossos resultados, essas organizações podem ajustar pequenos LLMs de código aberto que alcançam melhor qualidade de código e velocidade de inferência. Esses modelos podem então ser hospedados pela organização ou por um terceiro confiável para ganhos de custo, confiabilidade e conformidade.
Enfatizamos que o treinamento em dados de interação é particularmente eficaz por três motivos. Em primeiro lugar, é gerado naturalmente - portanto, não requer esforço de anotação. Em segundo lugar, contém exemplos que são encontrados na prática e, portanto, é particularmente útil para o ajuste fino, mesmo em quantidades moderadas. Finalmente, como os dados de interação são constantemente gerados por interações com o agente LLM, podemos usar repetidamente os novos dados de interação gerados para ajustar ainda mais nosso LLM, levando ao Aprendizado Nunca Acaba (NEL).
O que vem a seguir? Acreditamos que essas lições também são verdadeiras para outras aplicações empresariais. As organizações podem ajustar LLMs como Llama para reparo de programas ou outras tarefas usando o serviço de ajuste fino do Databricks e servir o modelo com apenas um clique. Você pode começar aqui. Também estamos explorando a possibilidade de oferecer aos clientes a capacidade de personalizar o Quick Fix usando seus próprios dados.
Detalhes do Nosso Estudo
Um Workspace da Databricks fornece vários agentes LLM para aumentar a produtividade. Estes incluem um agente LLM para autocomplete de código, um assistente de IA que pode se envolver em conversas para ajudar os usuários, e o agente Quick Fix para reparo de programas. Neste post, focamos no agente Quick Fix (Figura 1).
A reparação de programas é um problema desafiador na prática. Os erros podem variar desde erros sintáticos até nomes de colunas errados e questões semânticas sutis. Além disso, existem aspectos de personalização ou restrições que nem sempre são bem gerenciados por LLMs prontos para uso. Por exemplo, usuários da Databricks geralmente escrevem ANSI padrão ou Spark SQL, não scripts PL/SQL, mas um formato diferente pode ser preferido por outras organizações. Da mesma forma, ao corrigir o código, não queremos alterar o estilo de codificação, mesmo que a correção proposta esteja correta. Pode-se usar um modelo proprietário como GPT-4, o1 ou Claude 3.5 junto com a engenharia de prompt para tentar remediar essas limitações. No entanto, a engenharia de prompt pode não ser tão eficaz quanto o ajuste fino. Além disso, esses modelos são caros, e a latência é um fator crucial, já que queremos sugerir correções antes que o usuário possa corrigir o código por conta própria. Abordagens de engenharia de prompt, como aprendizado em contexto [5] ou auto-reflexão [6], podem aumentar ainda mais a latência. Por fim, alguns clientes podem hesitar em usar modelos proprietários hospedados em outros lugares.
Pequenos modelos de código aberto como Llama 8b, Gemma 4b, R1 Distill Llama 8b e Qwen 7b oferecem uma alternativa com diferentes compensações. Esses modelos podem ser baratos, rápidos e ser treinados e hospedados pela organização ou por um terceiro de confiança para melhor conformidade. No entanto, eles tendem a ter um desempenho substancialmente pior do que alguns dos modelos proprietários listados acima. Como podemos ver na Figura 1, o modelo Llama 3.1 8b é o de pior desempenho entre os modelos testados. Isso levanta a questão:
Podemos adaptar modelos de código aberto pequenos e ainda superar os modelos proprietários prontos em precisão, custo e velocidade?
Embora a engenharia de prompts ofereça alguns ganhos (veja os resultados abaixo), ela tende a ser menos eficaz do que o ajuste fino do LLM, especialmente para modelos menores. No entanto, para realizar um ajuste fino eficaz, precisamos de dados de domínio apropriados. Onde conseguimos isso?
Ajustando o Llama 8b usando seus Dados de Interação
Para tarefas de reparo de programas, pode-se usar dados de interação que são gerados organicamente pelos usuários para realizar o ajuste fino. Isso funciona da seguinte maneira (Figura 3):
 Figura 3: Usamos logs de implantação para o ajuste fino de LLMs que podem ser usados para um ajuste fino sem fim de LLMs.
Figura 3: Usamos logs de implantação para o ajuste fino de LLMs que podem ser usados para um ajuste fino sem fim de LLMs.
- Registramos o código com erro y, na primeira vez que o usuário executa a célula de código que leva a um erro. Também registramos qualquer contexto adicional x como a mensagem de erro, células de código circundantes e metadados (por exemplo, lista de tabelas e APIs disponíveis).
- Em seguida, registramos o código y' na próxima vez que o usuário executar com sucesso o código na célula originalmente com erro. Esta resposta poderia ser potencialmente gerada pelo agente Quick Fix Llama, pelo próprio usuário, ou por ambos.
- Armazenamos (x, y, y') em um conjunto de dados para ajuste fino.
Filtramos dois casos extremos: onde o suposto código corrigido y' é o mesmo que o código atual y, indicando correção de bug devido a razões externas (por exemplo, corrigindo um problema de permissão alterando a configuração em outro lugar), e onde y' é substancialmente diferente de y, indicando uma possível reescrita em vez de uma correção direcionada. Podemos usar esses dados para realizar o ajuste fino, aprendendo a gerar y' dado o contexto x e o código com bug y.
Usamos os próprios dados internos de interação do Databricks, processados conforme descrito acima, para ajustar um modelo Llama 3.1 8b Instruct. Treinamos dois tipos de modelo - um que gera todo o código corrigido (modelos completos) e um que gera apenas a diferença de código necessária para corrigir o código com bug (modelos de diferença). Este último tende a ser mais rápido, pois precisa produzir menos tokens, mas resolve uma tarefa mais difícil. Utilizamos o serviço de ajuste fino da Databricks e fizemos uma varredura em diferentes taxas de aprendizado e iterações de treinamento. Os resultados do nosso teste A/B na Figura 2 mostram que nosso modelo Llama ajustado é significativamente melhor em corrigir bugs do que os LLMs prontos para uso e também é muito mais rápido.
Selecionamos os melhores hiperparâmetros usando uma avaliação offline onde medimos a precisão de correspondência exata em um subconjunto retido de nossos dados de interação. A precisão de correspondência exata é uma pontuação de 0-1 que mede se nosso LLM pode gerar o código corrigido y' dado o código com bug y e o contexto x. Embora essa seja uma métrica mais ruidosa do que os testes A/B, ela pode fornecer um sinal útil para a seleção de hiperparâmetros. Mostramos os resultados da avaliação offline na Figura 4. Enquanto os modelos Llama originais apresentam desempenho substancialmente pior do que os modelos GPT-4o, nosso modelo Llama ajustado apresenta o melhor desempenho geral. Além disso, enquanto a engenharia de prompt via aprendizado em contexto (ICL) oferece um ganho substancial, ainda não é tão eficaz quanto realizar o ajuste fino.
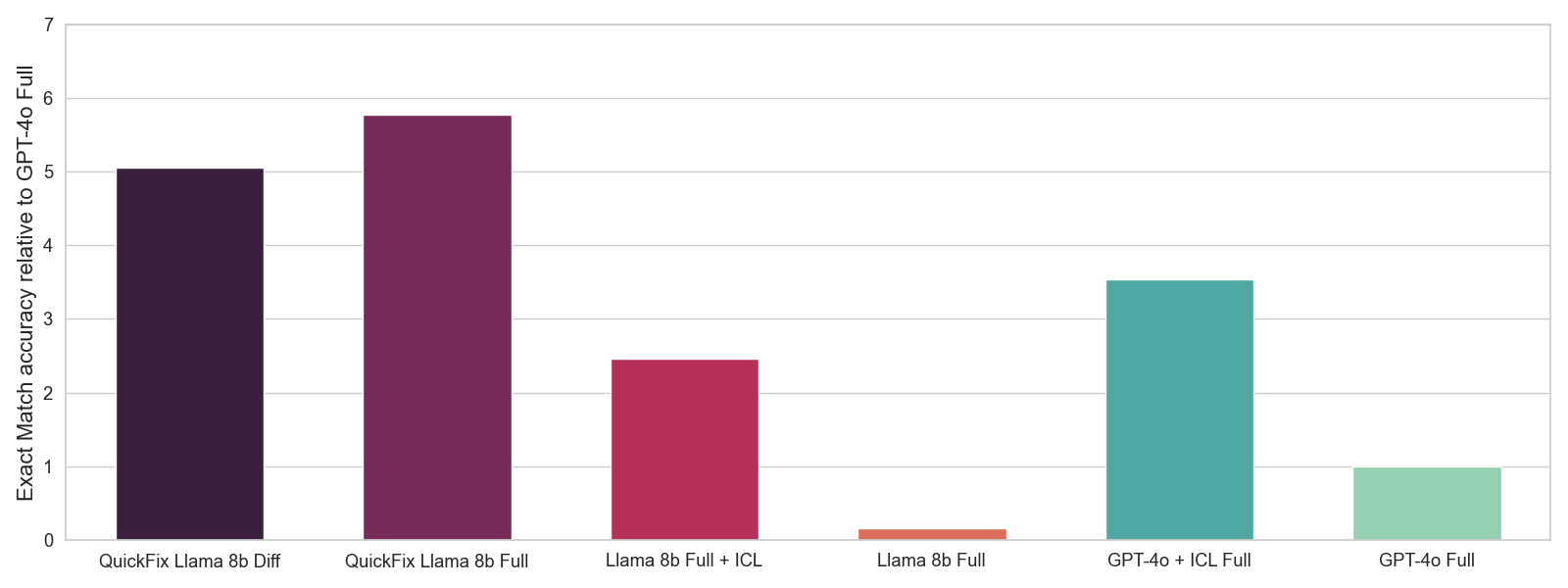 Figura 4: Avaliação offline com diferentes LLMs. Usamos 5 exemplos para ICL. Reportamos a média de precisão de correspondência exata 0-1 com base em se a correção gerada corresponde à correção correta. Normalizamos as precisões em relação à precisão do GPT-4o.
Figura 4: Avaliação offline com diferentes LLMs. Usamos 5 exemplos para ICL. Reportamos a média de precisão de correspondência exata 0-1 com base em se a correção gerada corresponde à correção correta. Normalizamos as precisões em relação à precisão do GPT-4o.
Finalmente, o que nosso modelo Quick Fix Llama aprende? Damos dois exemplos abaixo para ilustrar o benefício.
 Exemplo 1: Previsão com GPT-4o e modelo QuickFix Llama. Nomes reais de tabelas e constantes foram redigidos.
Exemplo 1: Previsão com GPT-4o e modelo QuickFix Llama. Nomes reais de tabelas e constantes foram redigidos.
No primeiro exemplo, o agente GPT-4o transformou incorretamente o código SQL com erro em PySpark SQL, enquanto o modelo QuickFix Llama ajustado manteve o estilo de código original. As edições do GPT-4o podem resultar em usuários gastando tempo revertendo diffs desnecessários, diminuindo assim o benefício de um agente de correção de bugs.
 Exemplo 2: Previsão com GPT-4o e modelo QuickFix Llama. Não mostramos o contexto por brevidade, mas o contexto neste caso contém uma coluna _partition_date para a tabela table2. Nomes reais de tabelas e constantes foram redigidos.
Exemplo 2: Previsão com GPT-4o e modelo QuickFix Llama. Não mostramos o contexto por brevidade, mas o contexto neste caso contém uma coluna _partition_date para a tabela table2. Nomes reais de tabelas e constantes foram redigidos.
No segundo exemplo, descobrimos que o agente GPT-4o substituiu incorretamente a coluna de data por _event_time ao superindexar a dica dada na mensagem de erro. No entanto, a edição correta é usar a coluna chamada _partition_date do contexto, que é o que tanto o usuário quanto o QuickFix Llama fazem. As edições do GPT-4o parecem superficialmente corretas, usando uma variável de tempo sugerida pelo motor SQL. No entanto, a sugestão na verdade demonstra uma falta de conhecimento específico do domínio que pode ser corrigida por ajuste fino.
Conclusão
As organizações têm necessidades específicas de codificação que são melhor atendidas por um agente LLM personalizado. Descobrimos que o ajuste fino dos LLMs pode melhorar significativamente a qualidade das sugestões de codificação, superando as abordagens de engenharia de prompt. Em particular, nossos modelos pequenos Llama 8B ajustados foram mais rápidos, mais baratos e mais precisos do que modelos proprietários significativamente maiores. Finalmente, exemplos de treinamento podem ser gerados usando dados de interação que estão disponíveis sem nenhum custo extra de anotação. Acreditamos que essas descobertas se generalizam além da tarefa de reparo de programas também.
Com o Treinamento de Modelos Mosaic AI, os clientes podem ajustar facilmente modelos como o Llama. Você pode aprender mais sobre como afinar e implantar LLMs de código aberto na Databricks aqui. Interessado em um modelo Quick Fix personalizado para a sua organização? Entre em contato com a sua equipe de conta Databricks para saber mais.
Agradecimentos: Agradecemos a Michael Piatek, Matt Samuels, Shant Hovsepian, Charles Gong, Ted Tomlinson, Phil Eichmann, Sean Owen, Andy Zhang, Beishao Cao, David Lin, Yi Liu, Sudarshan Seshadri por conselhos valiosos, ajuda e anotações.
Referências
- Reparo automático de programas, Goues, et al., 2019. Em Comunicações da ACM 62.12 (2019): 56-65.
- Semfix: Reparação de programas via análise semântica, Nguyen et al. 2013. Na 35ª Conferência Internacional de Engenharia de Software (ICSE). IEEE, 2013.
- Inferfix: Reparo de programas de ponta a ponta com LLMs, Jin et al., 2023. Nos Anais da 31ª Conferência Conjunta Europeia de Engenharia de Software da ACM e Simpósio sobre os Fundamentos da Engenharia de Software.
- RepairAgent: Um Agente Autônomo, Baseado em LLM, para Reparo de Programas, Bouzenia et al., 2024. Em arXiv https://arxiv.org/abs/2403.17134.
- Modelos de linguagem são aprendizes de poucos exemplos, Brown et al. 2020. Nos Avanços em Sistemas de Processamento de Informação Neural (NeurIPS).
- Corrigindo automaticamente grandes modelos de linguagem: Pesquisando o panorama de diversas estratégias de autocorreção, Pan et al., 2024. Em Transações da Associação para Linguística Computacional (TACL).
*Os autores estão listados em ordem alfabética
(This blog post has been translated using AI-powered tools) Original Post