Publicar em Múltiplos Catálogos e Esquemas a partir de um Único Pipeline DLT
Simplifique a sintaxe, otimize custos e reduza a complexidade operacional

Summary
- Suporte a Múltiplos Esquemas & Catálogos: Publique em vários esquemas e catálogos a partir de um único pipeline DLT.
- Sintaxe Simplificada & Redução de Custos: Elimine a palavra-chave LIVE e reduza a sobrecarga de infraestrutura.
- Melhor Observabilidade: Publique logs de eventos no Catálogo Unity e gerencie dados em diferentes localizações com SQL e Python.
DLT oferece uma plataforma robusta para construir pipelines de processamento de dados confiáveis, sustentáveis e testáveis dentro do Databricks. Ao aproveitar seu framework declarativo e provisionar automaticamente o cálculo serverless ideal, o DLT simplifica as complexidades de streaming, transformação de dados e gerenciamento, proporcionando escalabilidade e eficiência para fluxos de trabalho de dados modernos.
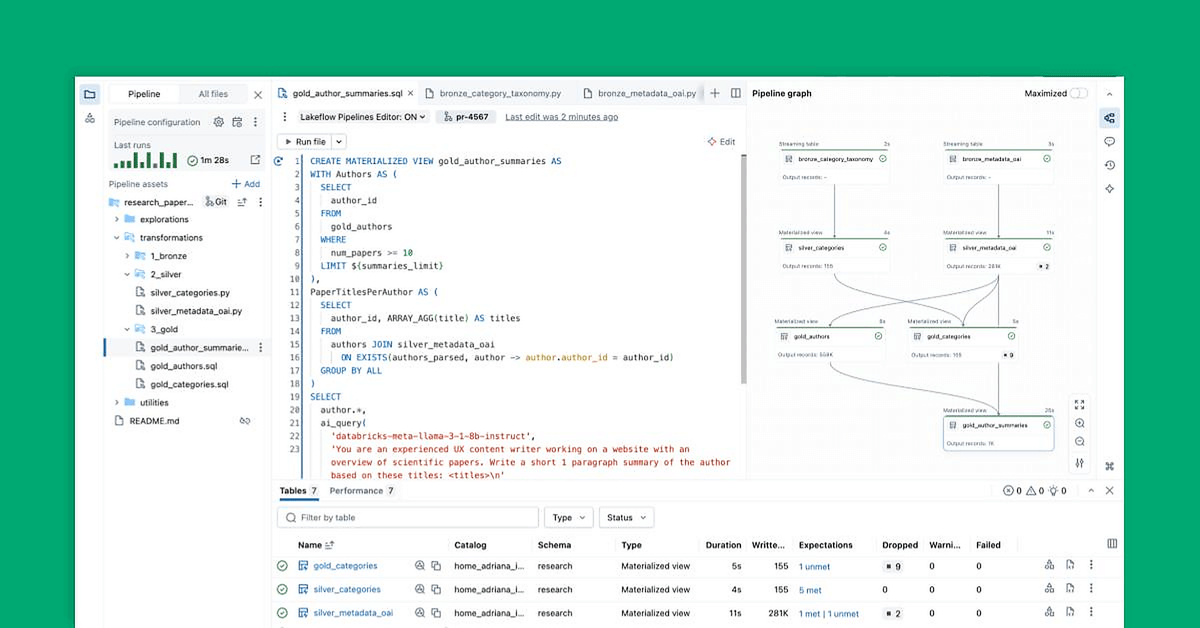
Estamos animados para anunciar uma melhoria muito aguardada: a capacidade de publicar tabelas em vários esquemas e catálogos dentro de um único pipeline DLT. Essa capacidade reduz a complexidade operacional, diminui os custos e simplifica a gestão de dados, permitindo que você consolide sua arquitetura de medalhão (Bronze, Prata, Ouro) em um único pipeline, mantendo as melhores práticas organizacionais e de governança.
Com essa melhoria, você pode:
- Simplificar a sintaxe do pipeline – Não há necessidade da sintaxe
LIVEpara denotar dependências entre tabelas. Nomes de tabelas totalmente e parcialmente qualificados são suportados, juntamente com os comandosUSE SCHEMAeUSE CATALOG, assim como no SQL padrão. - Reduza a complexidade operacional – Processe e publique todas as tabelas dentro de um pipeline DLT unificado, eliminando a necessidade de pipelines separados por esquema ou catálogo.
- Reduza custos – Minimize a sobrecarga de infraestrutura consolidando várias cargas de trabalho em um único pipeline.
- Melhore a observabilidade - Publique seu log de eventos como uma tabela padrão no metastore do Catálogo Unity para monitoramento e governança aprimorados.
“A capacidade de publicar em vários catálogos e esquemas a partir de um pipeline DLT - e não mais exigir a palavra LIVE - nos ajudou a padronizar as melhores práticas de pipeline, otimizar nossos esforços de desenvolvimento e facilitar a fácil transição de equipes de cargas de trabalho não-DLT para DLT como parte de nossa adoção em larga escala da ferramenta.” — Ron DeFreitas, Engenheiro de Dados Principal, HealthVerity

Como começar
Criando um Pipeline
Todos os pipelines criados a partir da UI agora suportam vários catálogos e esquemas por padrão. Você pode definir um catálogo e esquema padrão no nível do pipeline através da UI, da API, ou Databricks Asset Bundles (DABs).
A partir da UI:
- Crie um novo pipeline como de costume.
- Defina o catálogo e esquema padrão nas configurações do pipeline.
A partir da API:
Se você está criando um pipeline programaticamente, você pode habilitar essa capacidade especificando o campo schema nas PipelineSettings. Isso substitui o campo target existente, garantindo que os conjuntos de dados possam ser publicados em vários catálogos e esquemas.
Para criar um pipeline com essa capacidade via API, você pode seguir este exemplo de código (Nota: a autenticação Token de Acesso Pessoal deve estar habilitada para o espaço de trabalho):
Ao definir o campo schema, o pipeline suportará automaticamente a publicação de tabelas em vários catálogos e esquemas sem a necessidade da palavra-chave LIVE.
A partir do DAB
- Certifique-se de que seu Databricks CLI tem a versão v0.230.0 ou superior. Se não, atualize o CLI seguindo a documentação.
- Configure o ambiente do Databricks Asset Bundle (DAB) seguindo a documentação. Seguindo esses passos, você deve ter um diretório DAB gerado a partir do Databricks CLI que contém todos os arquivos de configuração e código-fonte.
- Encontre o arquivo YAML que define o pipeline DLT em:
<your dab folder>/<resource>/<pipeline_name>_pipeline.yml - Defina o campo
schemano YAML do pipeline e remova o campotargetse ele existir. - Execute “
databricks bundle validate“ para validar que a configuração DAB é válida. - Execute “
databricks bundle deploy -t“ para implantar seu primeiro pipeline <environment>DPM!
“O recurso funciona exatamente como esperamos que funcione! Eu consegui dividir os diferentes conjuntos de dados dentro do DLT em nossos esquemas de estágio, núcleo e UDM (basicamente uma configuração de bronze, prata, ouro) dentro de um único pipeline.” — Florian Duhme, Desenvolvedor de Software de Dados Especialista, Arvato

Publicando Tabelas em Vários Catálogos e Esquemas
Uma vez que seu pipeline esteja configurado, você pode definir tabelas usando nomes totalmente ou parcialmente qualificados tanto em SQL quanto em Python.
Exemplo SQL
Exemplo em Python
Lendo Conjuntos de Dados
Você pode referenciar conjuntos de dados usando nomes totalmente ou parcialmente qualificados, com a palavra-chave LIVE sendo opcional para compatibilidade retroativa.
Exemplo SQL
Exemplo em Python
Mudanças no Comportamento da API
Com essa nova capacidade, os principais métodos da API foram atualizados para suportar vários catálogos e esquemas de forma mais integrada:
dlt.read() e dlt.read_stream()
Anteriormente, esses métodos só podiam referenciar conjuntos de dados definidos dentro do pipeline atual. Agora, eles podem referenciar conjuntos de dados em vários catálogos e esquemas, rastreando automaticamente as dependências conforme necessário. Isso facilita a construção de pipelines que integram dados de diferentes localizações sem configuração manual adicional.
spark.read() e spark.readStream()
No passado, esses métodos exigiam referências explícitas a conjuntos de dados externos, tornando as consultas entre catálogos mais complicadas. Com a nova atualização, as dependências agora são rastreadas automaticamente, e o esquema LIVE não é mais necessário. Isso simplifica o processo de leitura de dados de várias fontes dentro de um único pipeline.
Usando USE CATALOG e USE SCHEMA
A sintaxe SQL do Databricks agora suporta a definição de catálogos e esquemas ativos dinamicamente, tornando mais fácil gerenciar dados em várias localizações.
Exemplo SQL
Exemplo em Python
Gerenciando Logs de Eventos no Catálogo Unity
Este recurso também permite que os proprietários de pipeline publiquem logs de eventos no metastore do Catálogo Unity para melhor observabilidade. Para habilitar isso, especifique o campo event_log nas configurações do pipeline JSON. Por exemplo:
Com isso, você agora pode emitir GRANTS na tabela de log de eventos como qualquer tabela regular:
Você também pode criar uma visualização sobre a tabela de log de eventos:
Além de tudo acima, você também pode transmitir a partir da tabela de log de eventos:
O que vem a seguir?
Olhando para o futuro, essas melhorias se tornarão o padrão para todos os novos pipelines criados, seja através da UI, API, ou Databricks Asset Bundles. Além disso, em breve estará disponível uma ferramenta de migração para ajudar na transição de pipelines existentes para o novo modelo de publicação.
Leia mais na documentação aqui.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?
Anúncios
November 19, 2025/7 min de leitura
A nova maneira de criar pipelines no Databricks: apresentando o IDE para engenharia de dados

Anúncios
December 2, 2025/5 min de leitura