VulnWatch: Priorização de Vulnerabilidades Aprimorada por IA
Explore como a priorização de vulnerabilidades impulsionada por IA melhora a segurança na Databricks, automatizando a detecção de ameaças, reduzindo tarefas manuais e melhorando o foco em riscos críticos.

Summary
- Como a Databricks usa IA para identificar e classificar automaticamente vulnerabilidades em bibliotecas de terceiros.
- O impacto da IA na redução do esforço manual para a equipe de segurança.
- Principais benefícios de priorizar vulnerabilidades com base na gravidade e relevância para a infraestrutura da Databricks.
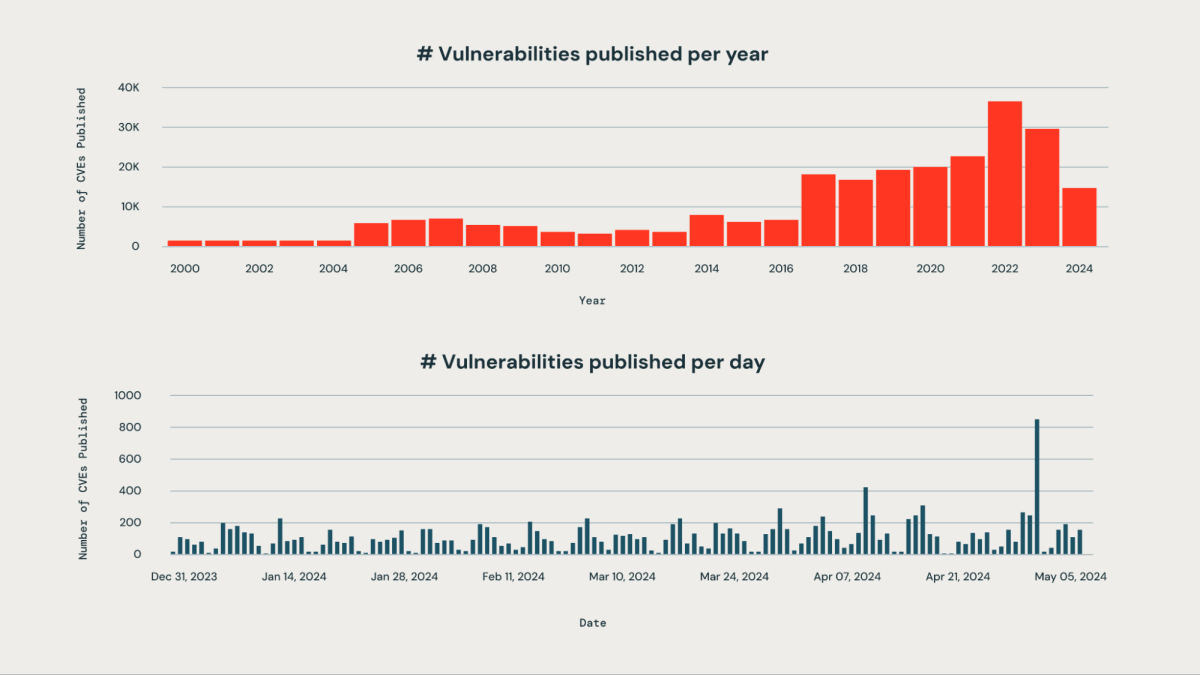
Toda organização é desafiada a priorizar corretamente novas vulnerabilidades que afetam um grande conjunto de bibliotecas de terceiros usadas dentro de sua organização. O grande volume de vulnerabilidades publicadas diariamente torna o monitoramento manual impraticável e intensivo em recursos.
Na Databricks, um dos nossos objetivos empresariais é garantir a segurança da nossa Plataforma de Inteligência de Dados. Nossa equipe de engenharia projetou um sistema baseado em IA que pode detectar, classificar e priorizar proativamente as vulnerabilidades assim que são divulgadas, com base em sua gravidade, impacto potencial e relevância para a infraestrutura do Databricks. Esta abordagem nos permite mitigar efetivamente o risco de vulnerabilidades críticas passarem despercebidas. Nosso sistema atinge uma taxa de precisão de aproximadamente 85% na identificação de vulnerabilidades críticas para o negócio. Ao aproveitar nosso algoritmo de priorização, a equipe de segurança reduziu significativamente sua carga de trabalho manual em mais de 95%. Agora, eles são capazes de focar sua atenção nos 5% das vulnerabilidades que requerem ação imediata, em vez de vasculhar centenas de problemas.
Nos próximos passos, vamos explorar como nossa abordagem orientada por IA ajuda a identificar, categorizar e classificar vulnerabilidades.
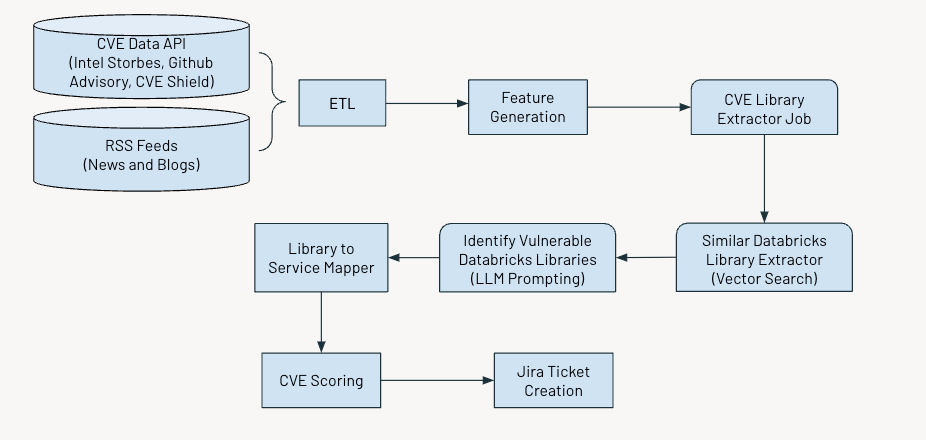
Como Nosso Sistema Sinaliza Continuamente Vulnerabilidades
O sistema opera em um cronograma regular para identificar e sinalizar vulnerabilidades críticas. O processo envolve várias etapas-chave:
- Coleta e processamento de dados
- Gerando características relevantes
- Utilizando IA para extrair informações sobre Vulnerabilidades Comuns e Exposições (CVEs)
- Avaliação e pontuação de vulnerabilidades com base em sua gravidade
- Geração de tickets Jira para ações futuras.
A figura abaixo mostra o fluxo de trabalho geral.
Ingestão de dados
Nós ingerimos dados de Vulnerabilidades e Exposições Comuns (CVE), que identificam vulnerabilidades de segurança cibernética divulgadas publicamente a partir de várias fontes, como:
- Intel Strobes API: Isso fornece informações e detalhes sobre os pacotes de software e suas versões.
- Banco de Dados de Avisos do GitHub: Na maioria dos casos, quando as vulnerabilidades não são registradas como CVE, elas aparecem como avisos do Github.
- Escudo CVE: Isso fornece os dados de vulnerabilidade em tendência a partir dos feeds recentes de mídias sociais
Além disso, coletamos feeds RSS de fontes como securityaffairs e hackernews e outros artigos de notícias e blogs que mencionam vulnerabilidades de cibersegurança.
Geração de Recursos
Em seguida, extrairemos as seguintes características para cada CVE:
- Descrição
- Idade do CVE
- Pontuação CVSS (Common Vulnerability Scoring System)
- Pontuação EPSS (Sistema de Pontuação de Previsão de Exploração)
- Pontuação de impacto
- Disponibilidade de exploração
- Disponibilidade de correção
- Status de tendência em X
- Número de avisos
Embora as pontuações CVSS e EPSS forneçam insights valiosos sobre a gravidade e a explorabilidade das vulnerabilidades, elas podem não se aplicar totalmente para a priorização em certos contextos.
A pontuação CVSS não captura completamente o contexto ou ambiente específico de uma organização, o que significa que uma vulnerabilidade com uma alta pontuação CVSS pode não ser tão crítica se o componente afetado não estiver em uso ou for adequadamente mitigado por outras medidas de segurança.
Da mesma forma, a pontuação EPSS estima a probabilidade de exploração, mas não leva em conta a infraestrutura específica de uma organização ou postura de segurança. Portanto, uma alta pontuação EPSS pode indicar uma vulnerabilidade que provavelmente será explorada em geral. No entanto, ainda pode ser irrelevante se os sistemas afetados não fazem parte da superfície de ataque da organização na internet.
Confiar apenas nos scores CVSS e EPSS pode levar a uma enxurrada de alertas de alta prioridade, tornando o gerenciamento e a priorização deles um desafio.
Pontuação de Vulnerabilidades
Desenvolvemos um conjunto de pontuações baseadas nos recursos acima - pontuação de gravidade, pontuação de componente e pontuação de tópico - para priorizar as CVEs, cujos detalhes são dados abaixo.
Pontuação de Gravidade
Esta pontuação ajuda a quantificar a importância do CVE para a comunidade em geral. Calculamos a pontuação como uma média ponderada das pontuações CVSS, EPSS e Impacto. A entrada de dados do CVE Shield e de outros feeds de notícias nos permite avaliar como a comunidade de segurança e nossas empresas parceiras percebem o impacto de qualquer CVE dada. O alto valor dessa pontuação corresponde a CVEs considerados críticos para a comunidade e nossa organização.
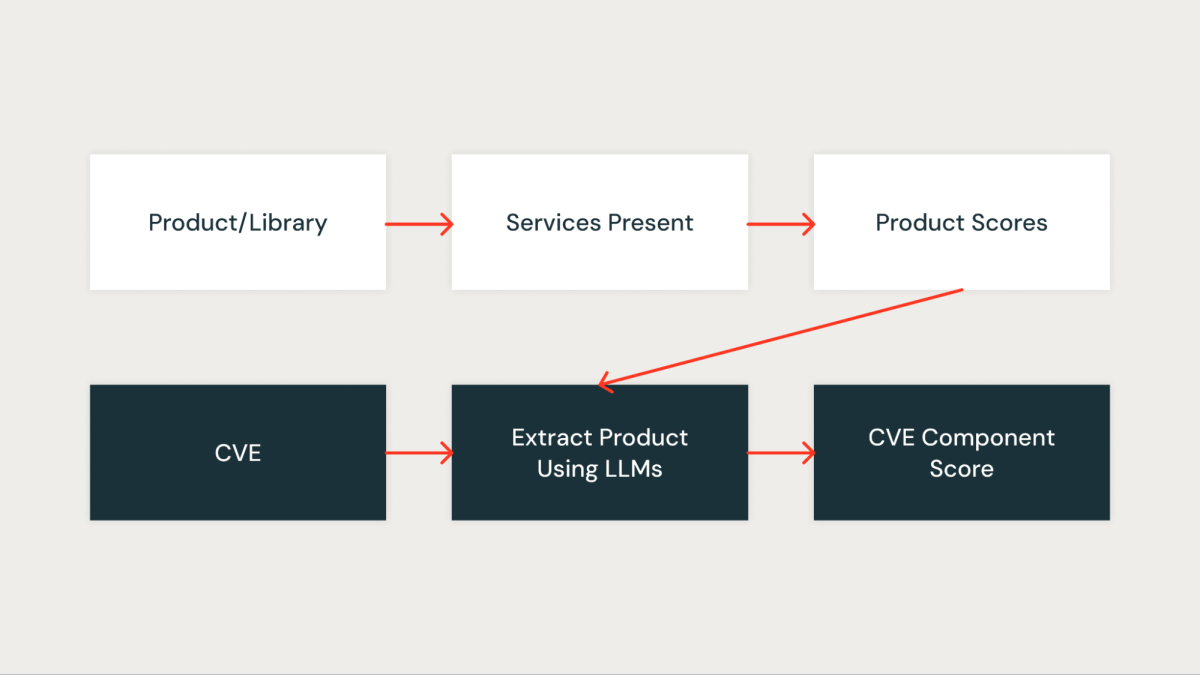
Pontuação de Componente
Esta pontuação mede quantitativamente o quão importante o CVE é para a nossa organização. Cada biblioteca na organização é primeiro atribuída uma pontuação com base nos serviços impactados pela biblioteca. Uma biblioteca que está presente em serviços críticos recebe uma pontuação mais alta, enquanto uma biblioteca que está presente em serviços não críticos recebe uma pontuação mais baixa.
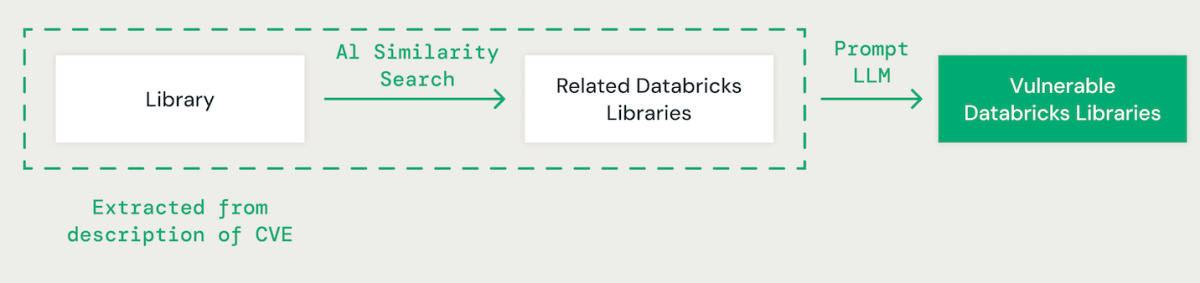
Biblioteca Compatível com IA
Utilizando a técnica de poucos exemplos (few-shot prompting) com um grande modelo de linguagem (LLM), extraímos a biblioteca relevante para cada CVE a partir de sua descrição. Posteriormente, empregamos uma abordagem de similaridade de vetor baseada em IA para combinar a biblioteca identificada com as bibliotecas Databricks existentes. Isso envolve converter cada palavra no nome da biblioteca em um embedding para comparação.
Ao combinar bibliotecas CVE com bibliotecas Databricks, é essencial entender as dependências entre diferentes bibliotecas. Por exemplo, enquanto uma vulnerabilidade no IPython pode não afetar diretamente o CPython, um problema no CPython pode impactar o IPython. Além disso, variações nas convenções de nomenclatura de bibliotecas, como "scikit-learn", "scikitlearn", "sklearn" ou "pysklearn" devem ser consideradas ao identificar e combinar bibliotecas. Além disso, as vulnerabilidades específicas da versão devem ser levadas em conta. Por exemplo, as versões do OpenSSL de 1.0.1 a 1.0.1f podem ser vulneráveis, enquanto patches em versões posteriores, como 1.0.1g a 1.1.1, podem abordar esses riscos de segurança.
Os LLMs aprimoram o processo de correspondência de bibliotecas, aproveitando o raciocínio avançado e a expertise do setor. Ajustamos vários modelos usando um conjunto de dados de verdade básica para melhorar a precisão na identificação de pacotes dependentes vulneráveis.
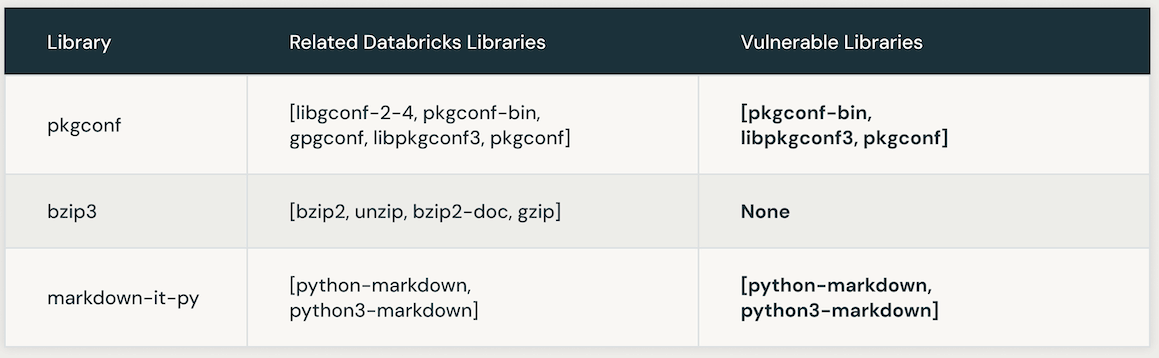
A tabela a seguir apresenta instâncias de bibliotecas Databricks vulneráveis vinculadas a um CVE específico. Inicialmente, a busca de similaridade por IA é usada para identificar bibliotecas intimamente associadas à biblioteca CVE. Posteriormente, um LLM é empregado para determinar a vulnerabilidade dessas bibliotecas semelhantes dentro do Databricks.
Automatizando a Otimização de Instrução LLM para Precisão e Eficiência
Otimizar manualmente instruções em um prompt LLM pode ser trabalhoso e propenso a erros. Uma abordagem mais eficiente envolve o uso de um método iterativo para produzir automaticamente vários conjuntos de instruções e otimizá-los para um desempenho superior em um conjunto de dados de verdade fundamental. Este método minimiza o erro humano e garante um aprimoramento mais eficaz e preciso das instruções ao longo do tempo.
Aplicamos esta técnica de otimização de instrução automatizada para melhorar nossa própria solução baseada em LLM. Inicialmente, fornecemos uma instrução e o formato de saída desejado para o LLM para rotulação do conjunto de dados. Os resultados foram então comparados com um conjunto de dados de verdade básica, que continha dados rotulados por humanos fornecidos pela nossa equipe de segurança do produto.
Posteriormente, utilizamos um segundo LLM conhecido como "Afinador de Instruções". Alimentamos com o prompt inicial e os erros identificados a partir da avaliação da verdade básica. Este LLM gerou iterativamente uma série de prompts melhorados. Após uma revisão das opções, selecionamos o prompt de melhor desempenho para otimizar a precisão.
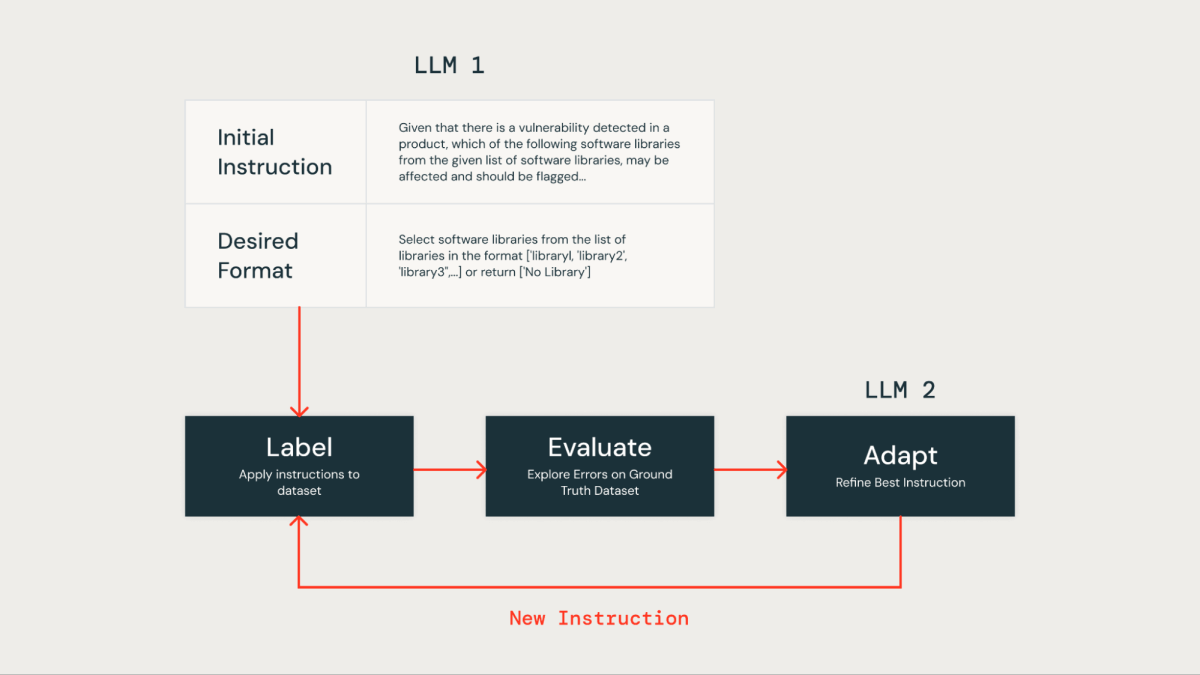
Após aplicar a técnica de otimização de instrução LLM, desenvolvemos o seguinte prompt refinado:
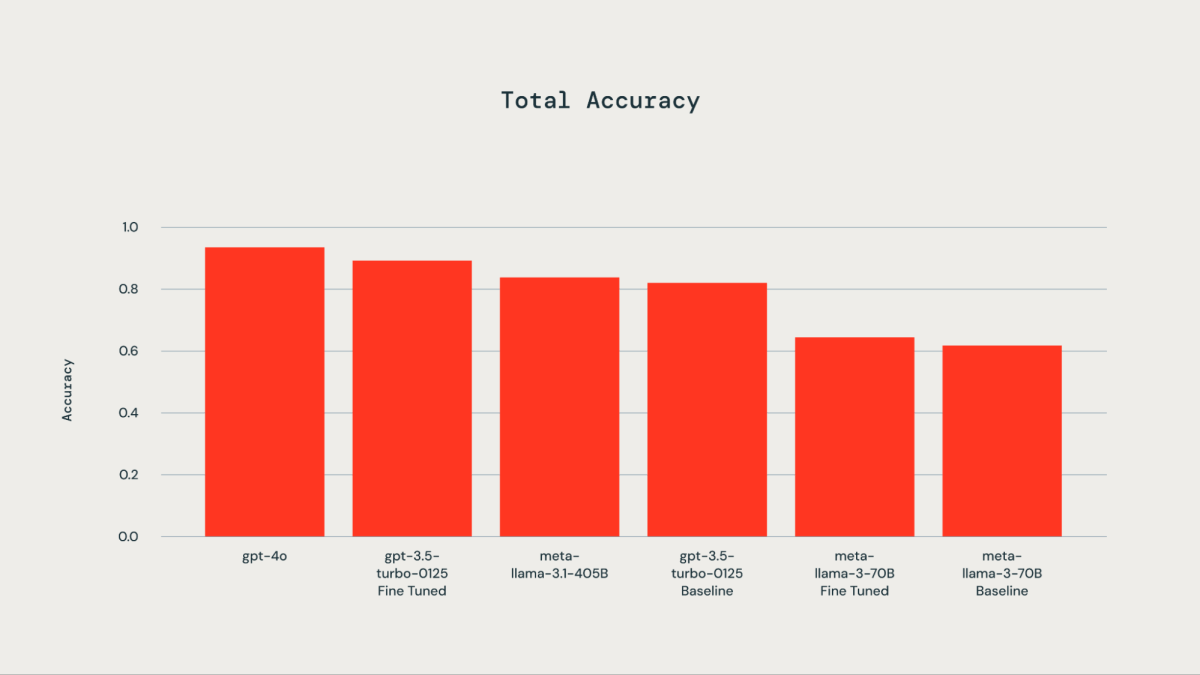
Escolhendo o LLM certo
Um conjunto de dados de ground truth composto por 300 exemplos rotulados manualmente foi utilizado para fins de ajuste fino. Os LLMs testados incluíram gpt-4o, gpt-3.5-Turbo, llama3-70B e llama-3.1-405b-instruct. Como ilustrado pelo gráfico acompanhante, o ajuste fino do conjunto de dados de verdade básica resultou em uma precisão melhorada para o gpt-3.5-turbo-0125 em comparação com o modelo base. O ajuste fino do llama3-70B usando a API de ajuste fino do Databricks levou a apenas uma melhoria marginal sobre o modelo base. A precisão do modelo gpt-3.5-turbo-0125 afinado foi comparável ou ligeiramente inferior à do gpt-4o. Da mesma forma, a precisão do modelo instruído llama-3.1-405b também foi comparável e ligeiramente inferior à do modelo gpt-3.5-turbo-0125 afinado.
Uma vez que as bibliotecas Databricks em um CVE são identificadas, a pontuação correspondente da biblioteca (library_score como descrito acima) é atribuída como a pontuação do componente do CVE.
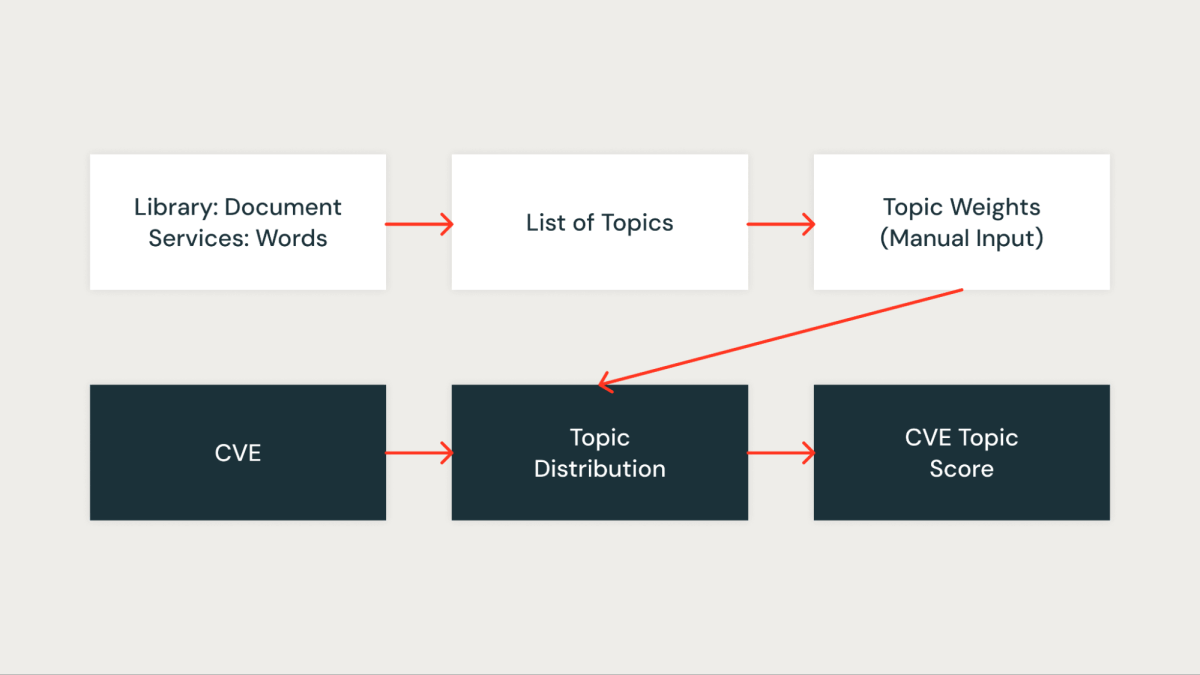
Pontuação do Tópico
Em nossa abordagem, utilizamos a modelagem de tópicos, especificamente a Alocação Latente de Dirichlet (LDA), para agrupar bibliotecas de acordo com os serviços aos quais estão associadas. Cada biblioteca é tratada como um documento, com os serviços em que aparece atuando como as palavras dentro desse documento. Este método nos permite agrupar bibliotecas em tópicos que representam efetivamente contextos de serviço compartilhados.
A figura abaixo mostra um tópico específico onde todos os serviços do Databricks Runtime (DBR) são agrupados e visualizados usando pyLDAvis.
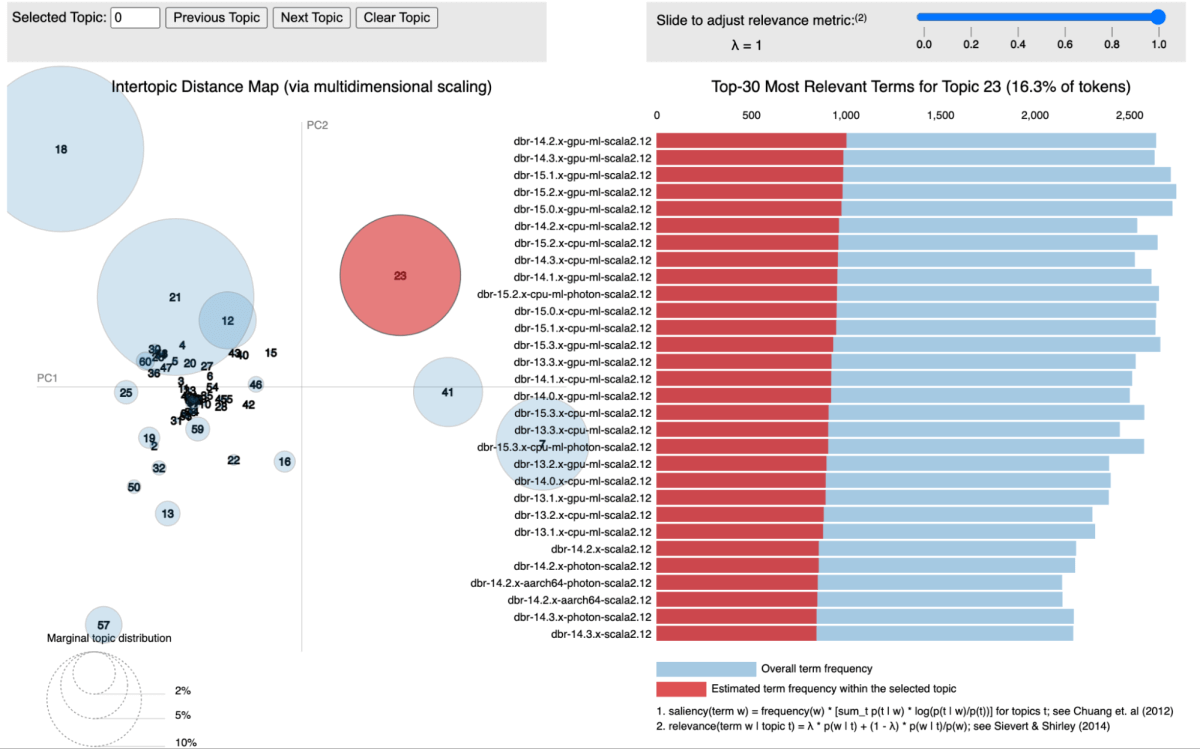
Para cada tópico identificado, atribuímos uma pontuação que reflete sua importância dentro de nossa infraestrutura. Essa pontuação nos permite priorizar as vulnerabilidades com mais precisão, associando cada CVE à pontuação do tópico das bibliotecas relevantes. Por exemplo, suponha que uma biblioteca esteja presente em vários serviços críticos. Nesse caso, a pontuação do tópico para essa biblioteca será maior e, portanto, a CVE que a afeta receberá uma prioridade maior.
Impacto e Resultados
Utilizamos uma variedade de técnicas de agregação para consolidar as pontuações mencionadas acima. Nosso modelo foi testado usando três meses de dados CVE, durante os quais alcançou uma impressionante taxa de verdadeiros positivos de aproximadamente 85% na identificação de CVEs relevantes para o nosso negócio. O modelo conseguiu identificar com sucesso vulnerabilidades críticas no dia em que são publicadas (dia 0) e também destacou vulnerabilidades que justificam uma investigação de segurança.
Para avaliar os falsos negativos produzidos pelo modelo, comparamos as vulnerabilidades sinalizadas por fontes externas ou identificadas manualmente por nossa equipe de segurança que o modelo falhou em detectar. Isso nos permitiu calcular a porcentagem de vulnerabilidades críticas perdidas. Notavelmente, não houve falsos negativos nos dados testados retroativamente. No entanto, reconhecemos a necessidade de monitoramento e avaliação contínuos nesta área.
Nosso sistema efetivamente simplificou nosso fluxo de trabalho, transformando o processo de gerenciamento de vulnerabilidades em uma etapa de triagem de segurança mais eficiente e focada. Isso mitigou significativamente o risco de negligenciar um CVE com impacto direto no cliente e reduziu a carga de trabalho manual em mais de 95%. Esse ganho de eficiência permitiu que nossa equipe de segurança se concentrasse em algumas vulnerabilidades selecionadas, em vez de vasculhar as centenas publicadas diariamente.
Agradecimentos
Este trabalho é uma colaboração entre a equipe de Ciência de Dados e a equipe de Segurança de Produto. Obrigado a Mrityunjay Gautam Aaron Kobayashi Anurag Srivastava e Ricardo Ungureanu da equipe de Segurança do Produto, Anirudh Kondaveeti Benjamin Ebanks Jeremy Stober e Chenda Zhang da equipe de Ciência de Dados de Segurança.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Produto
June 12, 2024/11 min de leitura
Apresentando o AI/BI: analítica inteligente para dados do mundo real

Produto
January 7, 2025/5 min de leitura