O que é Fluxo de Dados?
Movimentação e transformação de dados da origem ao destino por meio de pipelines de streaming, fluxos de trabalho em lote, processamento de eventos em tempo real e ETL orquestrado.
- Os padrões incluem extração-transformação-carregamento (ETL) para processamento em lote, extração-carregamento-transformação (ELT) aproveitando o poder computacional do sistema de destino, arquiteturas de streaming para processamento contínuo e arquiteturas lambda que combinam processamento em lote e em tempo real.
- A orquestração gerencia as dependências das tarefas, agenda a execução, lida com erros, permite o processamento paralelo, fornece painéis de monitoramento e mantém o estado em sistemas distribuídos, coordenando fluxos de trabalho complexos de várias etapas.
- As técnicas de otimização abrangem processamento incremental, evitando recálculo completo, particionamento para paralelismo, armazenamento em cache de resultados intermediários, pushdown de predicados, minimizando a movimentação de dados, e alocação adaptativa de recursos com base nas características da carga de trabalho.
O que é fluxo de dados?
O fluxo de dados descreve o movimento de dados pela arquitetura de um sistema, de um processo ou de componente para outro. Ele descreve como os dados são inseridos, processados, armazenados e gerados em um sistema, aplicativo ou rede de computadores. O fluxo de dados impacta diretamente a eficiência, confiabilidade e segurança de qualquer sistema de TI. Dessa forma, é crucial que o sistema seja configurado corretamente para otimizar seus resultados.
Existem diversos componentes-chave que definem como os dados são movidos e processados dentro de um sistema de fluxo de dados:
- Fonte de dados. O fluxo de dados começa com a ingestão de dados de uma fonte específica, que pode incluir dados estruturados e não estruturados, fontes com script ou entradas de clientes. Essas fontes iniciam o fluxo e ativam o sistema de fluxo de dados.
- Transformação de dados. Uma vez que os dados são ingeridos no sistema, eles podem se transformar em uma estrutura ou formato utilizável para a análise ou ciência de dados. A transformação de dados ocorre de acordo com as regras de transformação de dados, que definem como as informações devem ser manipuladas ou alteradas em todo o sistema. Isso ajuda a garantir que os dados estejam no formato correto para seus processos e resultados analíticos.
- Coletor de dados. Depois que os dados são ingeridos e transformados, o destino final dos dados processados é o coletor de dados. Este é o endpoint em um sistema de dados, onde são utilizados sem serem transferidos ainda mais no fluxo de dados. Isso pode incluir um banco de dados, um lakehouse, relatórios ou arquivos de log onde os dados são gravados para fins de auditoria ou análise.
- Caminhos de fluxos de dados. Diagramas de fluxo de dados definem os caminhos ou canais pelos quais os dados se movem entre fontes, processos e destinos. Esses caminhos podem incluir conexões de rede físicas ou caminhos lógicos, como chamadas de API, e também possuem protocolos e canais para efetuar uma transmissão de dados segura e eficiente.
Exemplos de fluxo de dados
Dependendo de como sua organização estrutura o pipeline de dados, existem algumas maneiras práticas de gerenciar o fluxo de dados. Um processo de extrair, transformar e carregar (ETL) organiza, prepara e centraliza dados de diversas fontes, tornando-os acessíveis e utilizáveis para análise, geração de relatórios e tomada de decisões operacionais. Ao gerenciar o fluxo de dados dos sistemas de origem para um data warehouse ou banco de dados de destino, o ETL possibilita maior integração de dados e consistência, essenciais para gerar um entendimento confiável e apoiar estratégias data-driven.
- Analítica em tempo real. Este fluxo de dados processa um número infinito de registros da fonte original e organiza uma transmissão contínua de entrada de dados. Isso oferece ao usuário uma análise e entendimento instantâneos, que podem ser úteis para aplicações em que respostas rápidas são essenciais, como monitoramento, rastreamento, recomendações e ações automatizadas.
- Pipelines de dados operacionais. Os pipelines de dados operacionais são projetados para processar dados transacionais e operacionais fundamentais para as funções diárias e contínuas de uma organização. Esses pipelines capturam dados de várias fontes, como interações com clientes, transações financeiras, movimentos de estoque e leituras de sensores, e garantem que esses dados sejam processados, atualizados e disponibilizados em todos os sistemas quase em tempo real ou com baixa latência. A finalidade dos pipelines de dados operacionais é manter aplicativos e bancos de dados sincronizados, assegurando que as operações de negócios possam ser executadas sem interrupções e que todos os sistemas demonstrem o estado mais atualizado dos dados.
- Processamento em lote. O processamento em lote de fluxo de dados refere-se ao gerenciamento de grandes volumes de dados em intervalos programados ou após a coleta de dados suficientes para serem processados de uma só vez. Ao contrário do processamento em tempo real, o processamento em lote não requer resultados imediatos; em vez disso, ele foca na eficiência, escalabilidade e precisão do processamento ao agregar dados antes de processá-los. O processamento em lote é frequentemente utilizado para tarefas como a geração a relatórios, análise histórica e transformações de dados em grande escala, onde percepções imediatas não são necessárias.
Ferramentas e tecnologias para o fluxo de dados
Um fluxo de trabalho ETL é um exemplo comum de fluxo de dados. No processamento de ETL, os dados são extraídos dos sistemas de origem e gravados em uma área de preparação, transformados com base nos requisitos (garantindo a qualidade dos dados, eliminando duplicações, identificando dados ausentes) e, em seguida, gravados em um sistema de destino, como um data warehouse ou data lake.
Sistemas ETL robustos em sua empresa podem otimizar sua arquitetura de dados para melhorar a eficiência operacional, de taxas de transferência, latência e custos. Dessa forma, você terá acesso a dados de alta qualidade e em tempo hábil para auxiliar na tomada de decisões.
Com a enorme quantidade e variedade de dados críticos para os negócios sendo gerados, é fundamental entender como funciona o fluxo desses dados para obter uma boa engenharia de dados. Embora muitas empresas precisem escolher entre processamento em lote e transmissão em tempo real para gerenciar seus dados, a Databricks oferece uma única API para dados em lote e transmissão. Ferramentas como o Delta Live Tables ajudam o usuário a otimizar os custos e reduzir a latência ou taxa de transferência ao alternar os modos de processamento. Isso ajuda o usuário a preparar soluções para o futuro, facilitando a migração para a transmissão conforme a dinâmica das necessidades da empresa.
O manual de IA agêntica para empresas

Criação de diagramas de fluxo de dados
Uma das formas pelas quais as organizações demonstram o fluxo de dados em todo o sistema pela criação de um diagrama de fluxo de dados (DFD). O DFD é uma representação gráfica que ilustra como as informações são coletadas, processadas, armazenadas e utilizadas, estabelecendo o fluxo direcional de dados entre as diferentes partes do sistema. O tipo de DFD que você precisa criar depende da complexidade da sua arquitetura de dados, pois ele pode ser tão simples quanto uma visão geral do fluxo de dados, ou um gráfico multinível detalhado que descreve como os dados são gerenciados nos diferentes estágios de seu ciclo de vida.
Os DFDs evoluíram ao longo do tempo, e atualmente o Delta Live Tables utiliza gráficos acíclicos direcionados (DAGs) para representar a sequência de transformações de dados e as dependências entre tabelas ou views dentro de um pipeline. Cada transformação ou tabela é um nó, e as arestas entre os nós definem o fluxo de dados e as dependências. Isso garante que as operações sejam executadas na ordem correta e em um loop fechado direcional.
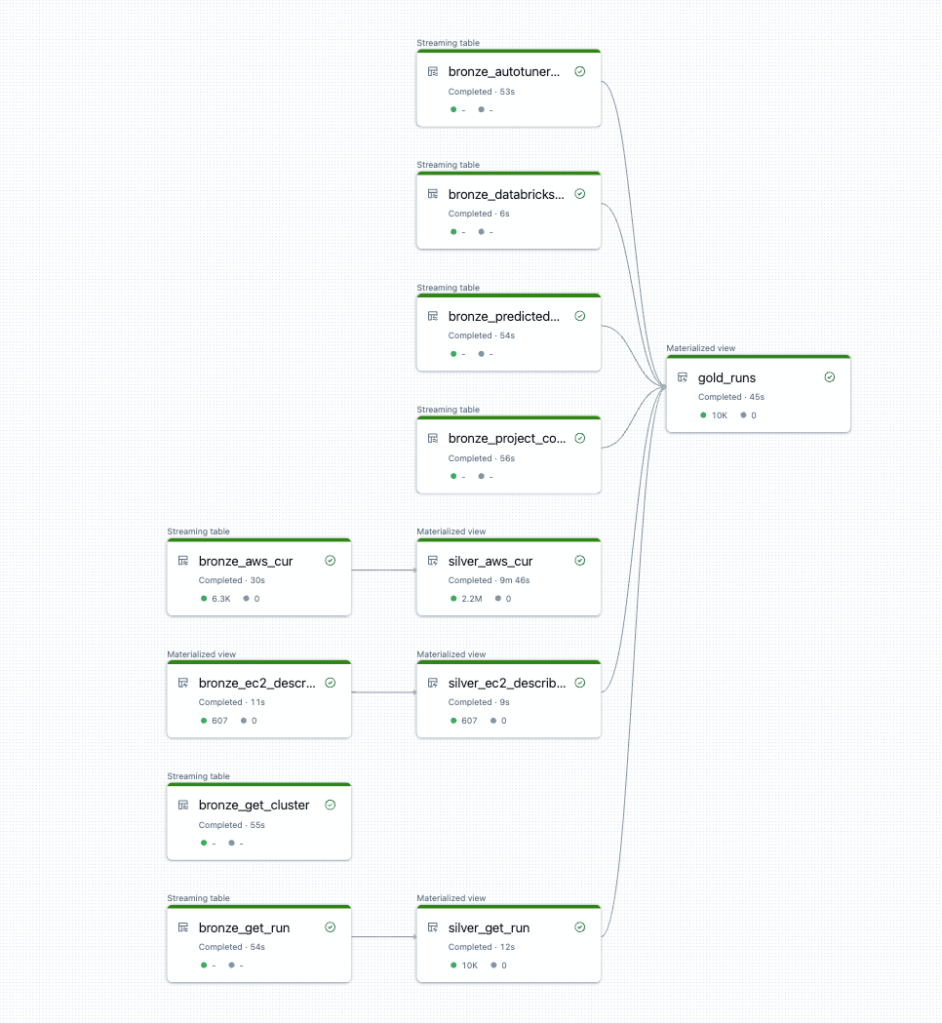
Os DAGs oferecem clareza visual para entender melhor as relações entre tarefas e também podem auxiliar na identificação e gestão de erros ou falhas no sistema de fluxo de dados. O Delta Live Tables assegura que o DAG seja gerenciado de maneira eficiente ao programar e otimizar operações como carregamento de dados, transformações e atualizações para manter a consistência e um bom desempenho.
Práticas recomendadas para o gerenciamento do fluxo de dados
Algumas práticas recomendadas devem ser seguidas para garantir que o fluxo de dados seja otimizado, eficiente e seguro:
- Otimizar o processo de dados. Envolve simplificar o fluxo de dados para eliminar gargalos, reduzir redundâncias e possibilitar o processamento em tempo real. Revisar e aperfeiçoar regularmente os fluxos de trabalho garante que os dados fluam pelo sistema com facilidade e sem complexidades desnecessárias, reduzindo o consumo de recursos e aumentando a escalabilidade.
- Assegurar um fluxo de informações integrado. Para obter um fluxo de informações contínuo, é essencial reduzir os silos de dados e priorizar a interoperabilidade entre os sistemas. Ao implementar pipelines de ETL rigorosos, as organizações podem usar dados consistentes em diversos aplicativos, departamentos e usos. Também significa criar processos confiáveis de backup e recuperação para proteger contra falhas ou interrupções do sistema.
- Considerações de segurança. Lembre-se de que é essencial garantir a segurança dos seus dados durante o fluxo. Todos os dados, principalmente informações sensíveis ou de identificação pessoal, devem ser criptografados durante a transferência ou armazenamento. Limitar o acesso aos dados pode ajudar a reduzir o risco de exposição não autorizada de dados, e a realização frequente de auditorias de segurança e avaliações de vulnerabilidades pode identificar pontos fracos potenciais e permitir medidas proativas para proteger o fluxo de dados de ponta a ponta.
- Monitoramento de desempenho. Utilizar ferramentas de analítica para monitorar métricas como latência, velocidades de transferência de dados e taxas de erro pode identificar áreas onde o fluxo de dados pode apresentar lentidão ou problemas. Configurar alertas e painéis automatizados garante que as equipes sejam imediatamente informadas de quaisquer problemas, permitindo uma resolução rápida e minimizando interrupções. Avaliações frequentes de desempenho também podem fornecer percepções acionáveis, garantindo um processo de gestão robusto, seguro e eficiente.
Vantagens de um fluxo de dados eficiente
Um fluxo de dados eficiente pode impactar significativamente os resultados financeiros da sua organização. Ao otimizar o fluxo contínuo e rápido de dados entre sistemas e departamentos, é possível otimizar os fluxos de trabalho, aumentar a produtividade e reduzir o tempo necessário para processar informações.
Para mais informações sobre como a Databricks pode ajudar sua organização a obter um fluxo de dados ideal, consulte algumas das nossas arquiteturas de referência de lakehouse. Além disso, saiba mais sobre nossa arquitetura medallion, um padrão de design de dados usado para organizar informações de forma lógica em um lakehouse.
Para mais informações sobre como o Delta Live Tables pode preparar sua organização para gerenciar dados em lotes e de transmissão, entre em contato com um representante da Databricks.
Um fluxo de dados eficiente pode ajudar sua organização a tomar decisões bem informadas e atender aos desafios operacionais ou de clientes. Com um acesso imediato aos dados disponíveis, você pode tomar decisões em tempo real utilizando as informações mais atualizadas. E com fluxos de dados eficientes, informações consistentes e confiáveis são garantidas.
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.