Pipelines de dados confiáveis simplificados
Simplifique o ETL em lotes e streaming com confiabilidade automatizada e qualidade de dados inte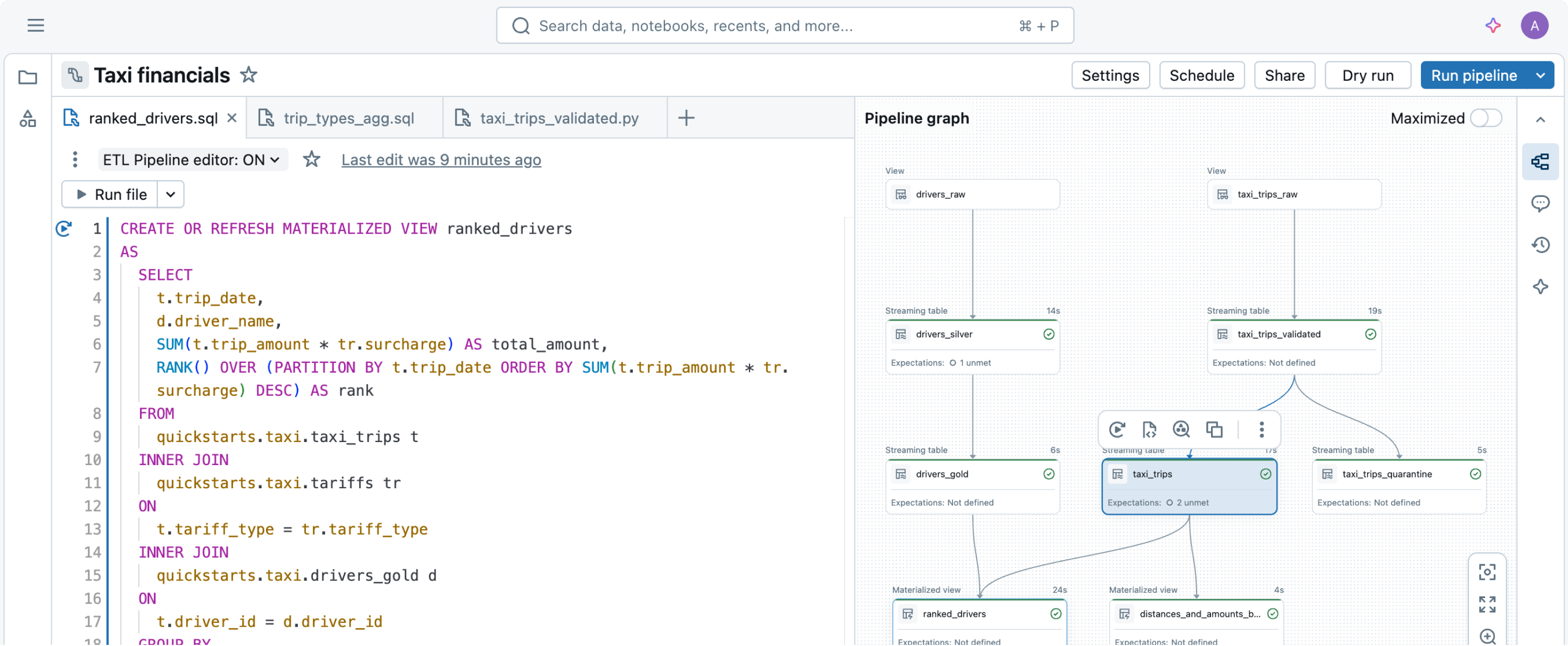
EQUIPES DE ALTO DESEMPENHO OBTÊM SUCESSO COM PIPELINES DE DADOS INTELIGENTES
Melhores práticas de pipeline de dados, codificadas
Basta declarar as transformações de dados de que você precisa e deixar que os Spark Declarative Pipelines cuidem do resto.Ingestão eficiente
A construção de pipelines ETL prontos para produção começa com a ingestão. Os Spark Declarative Pipelines possibilitam uma ingestão eficiente para engenheiros de dados, desenvolvedores de Python, cientistas de dados e analistas de SQL. Carregue dados de qualquer fonte compatível com Apache Spark™ na Databricks, seja em lotes, streaming ou CDC.
Transformação inteligente
Com apenas algumas linhas de código, os Spark Declarative Pipelines determinam a maneira mais eficiente de construir e executar seus pipelines de dados em lotes ou de streaming, otimizando automaticamente para custo ou desempenho enquanto minimiza a complexidade.
Operações automatizadas
Os Spark Declarative Pipelines simplificam o desenvolvimento de ETL codificando as melhores práticas prontas para uso e automatizando a complexidade operacional inerente. Com os Spark Declarative Pipelines, os engenheiros podem se concentrar em fornecer dados de alta qualidade em vez de operar e manter a infraestrutura do pipeline.
Projetado para simplificar o pipeline de dados
Construir e operar pipelines de dados pode ser difícil, mas não precisa ser. Os Spark Declarative Pipelines são projetados para oferecer simplicidade poderosa, permitindo que você realize ETL robusto com apenas algumas linhas de códigoAproveitando a API unificada do Spark para processamento em lotes e streaming, os Spark Declarative Pipelines permitem alternar facilmente entre os modos de processamento.

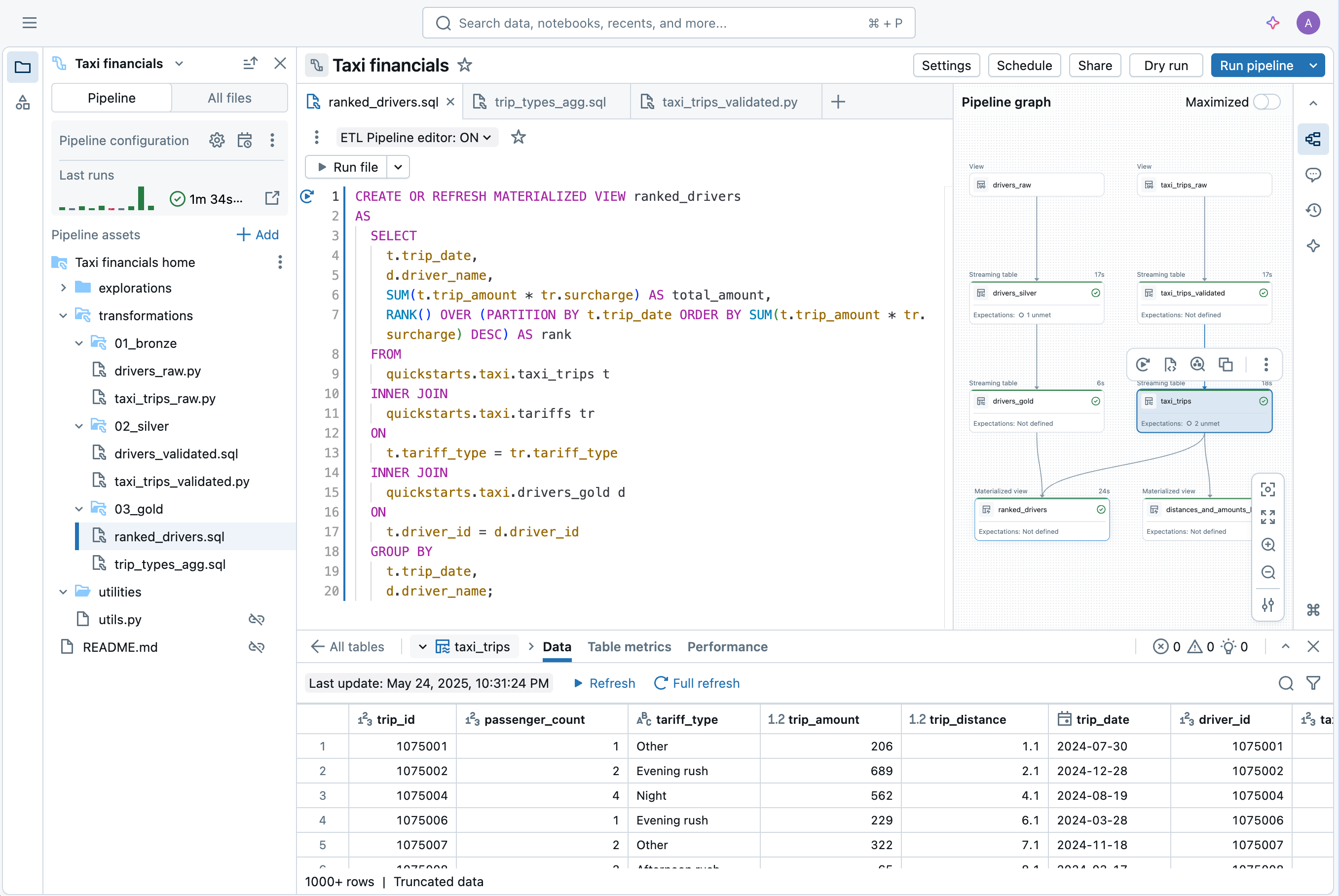
Mais recursos
Simplifique seus pipelines de dados

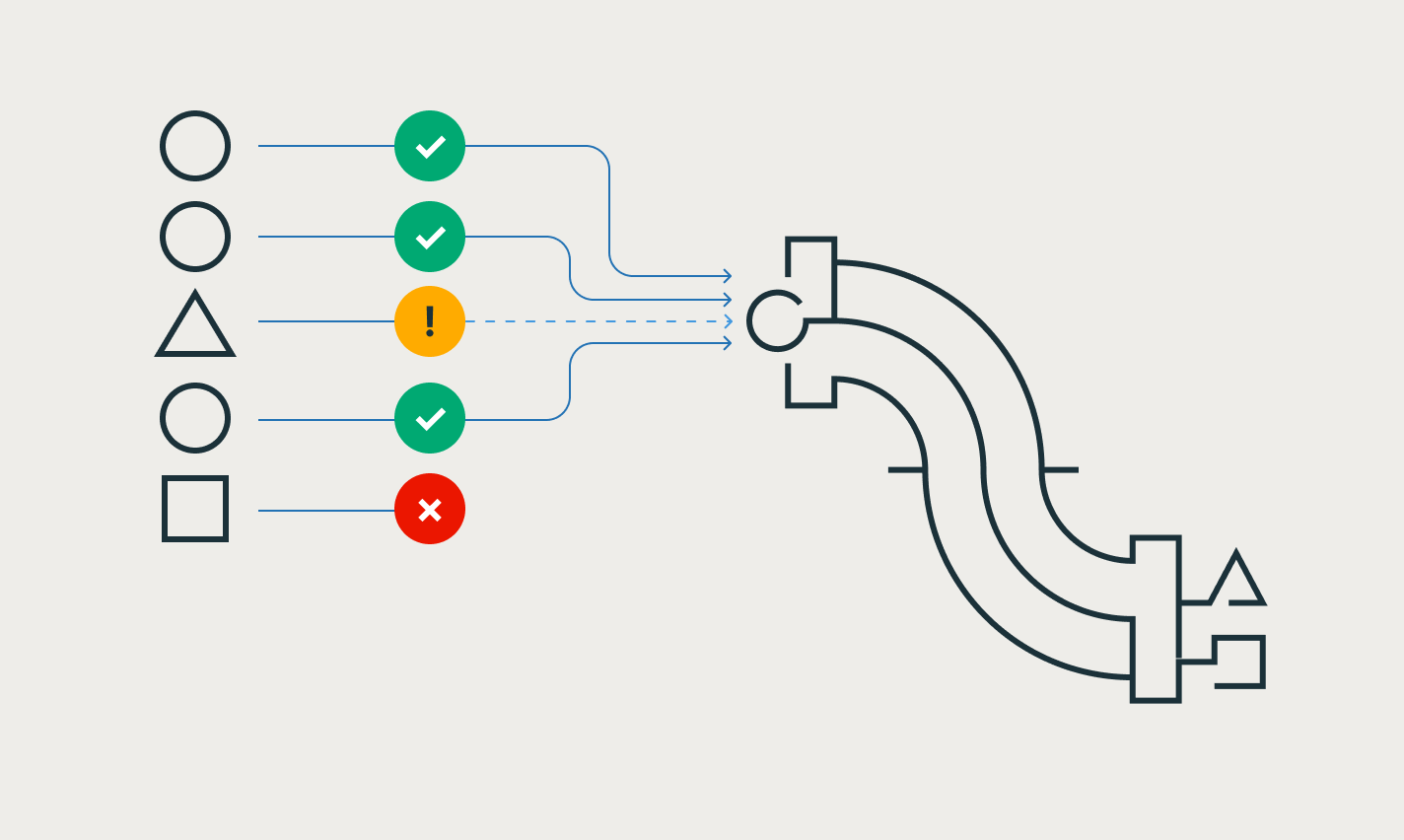
Assegure facilmente a integridade de dados e a consistência.
Simplifique a captura de dados de alterações com as APIs APPLY CHANGES para fluxos de dados de alterações e snapshots de banco de dados. Os Spark Declarative Pipelines gerenciam automaticamente registros fora de sequência para SCD Tipo 1 e 2, simplificando as partes mais complexas do CDC.
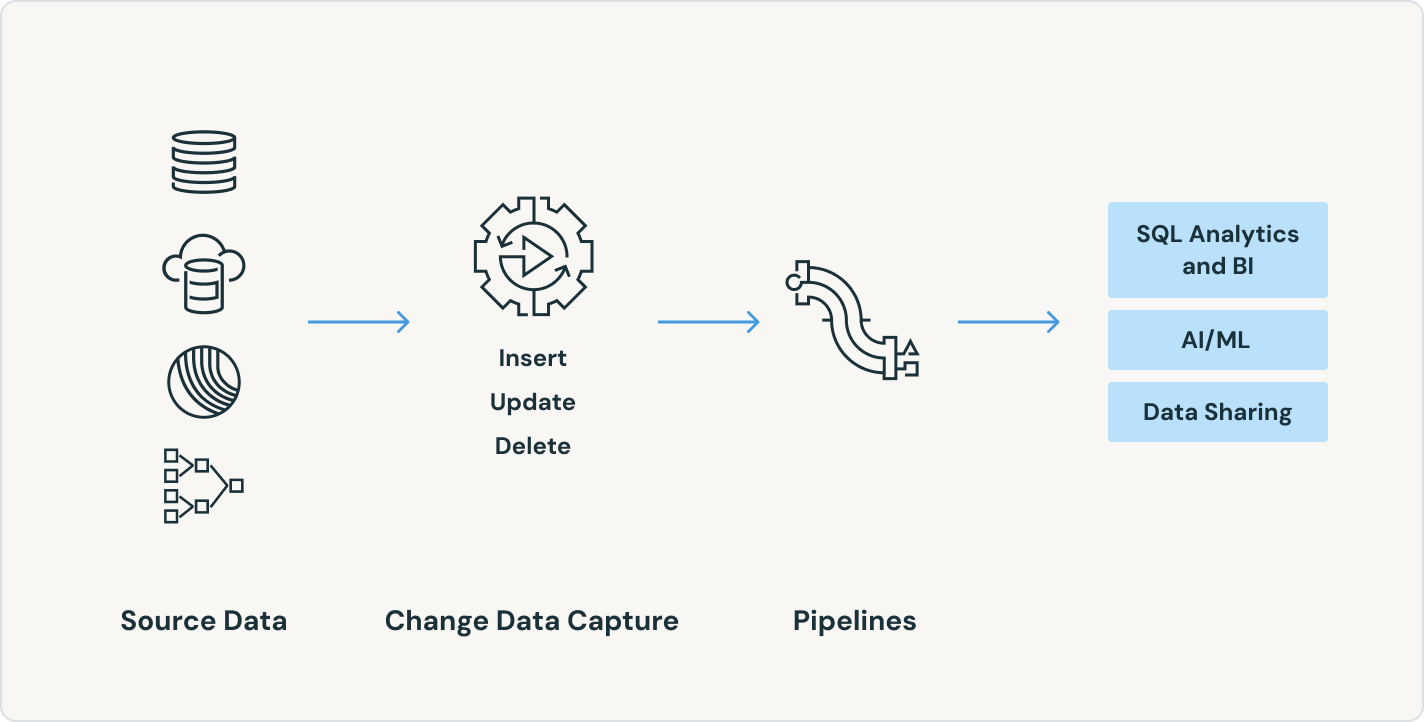
Desbloqueie casos de uso poderosos em tempo real sem a necessidade de ferramentas adicionais
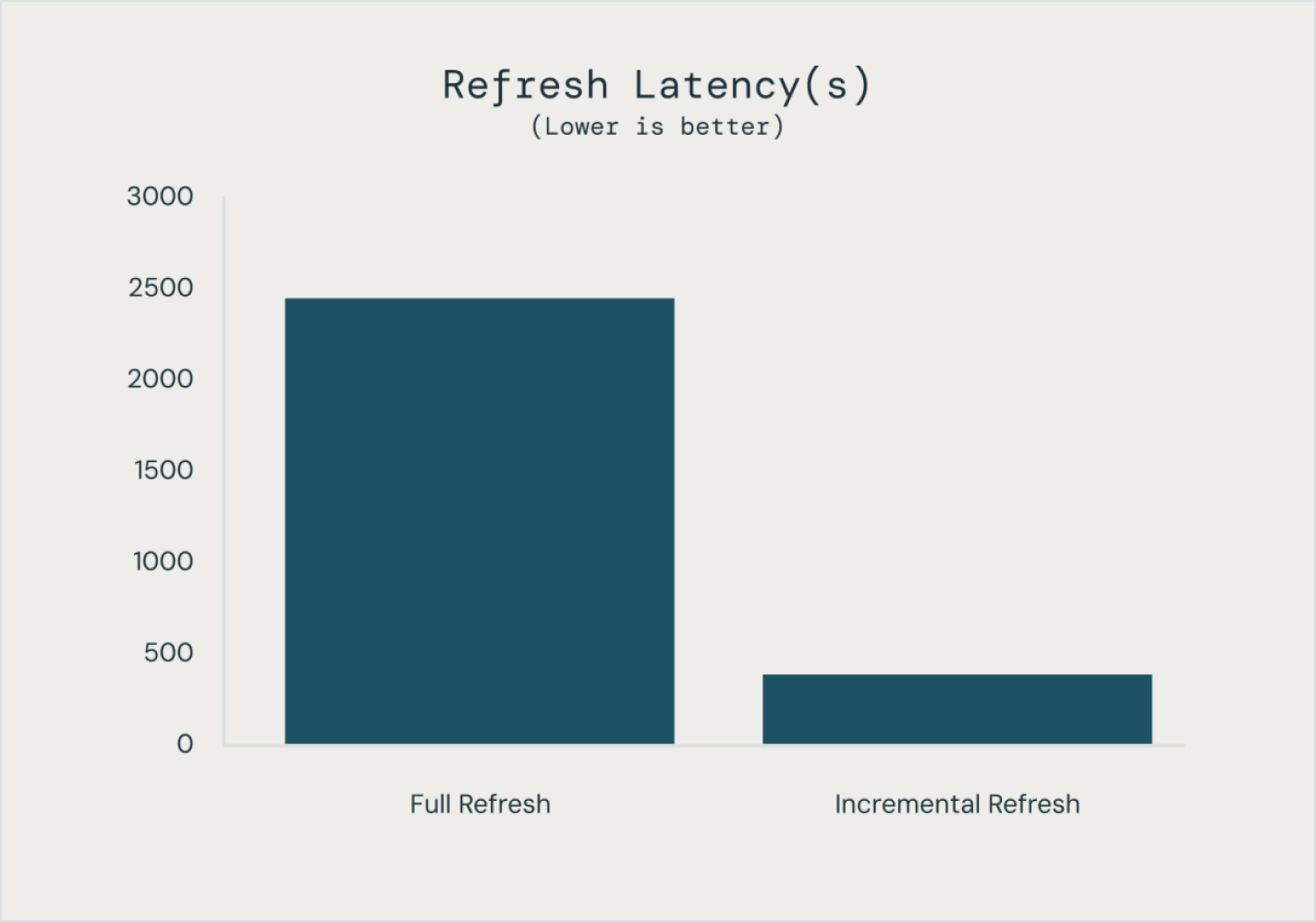
Crie e execute pipelines de dados em lotes e streaming em um só lugar com configurações de atualização controláveis e automatizadas, economizando tempo e reduzindo a complexidade operacional. Operacionalize dados de streaming para melhorar imediatamente a precisão e a capacidade de ação de sua analítica e AI.
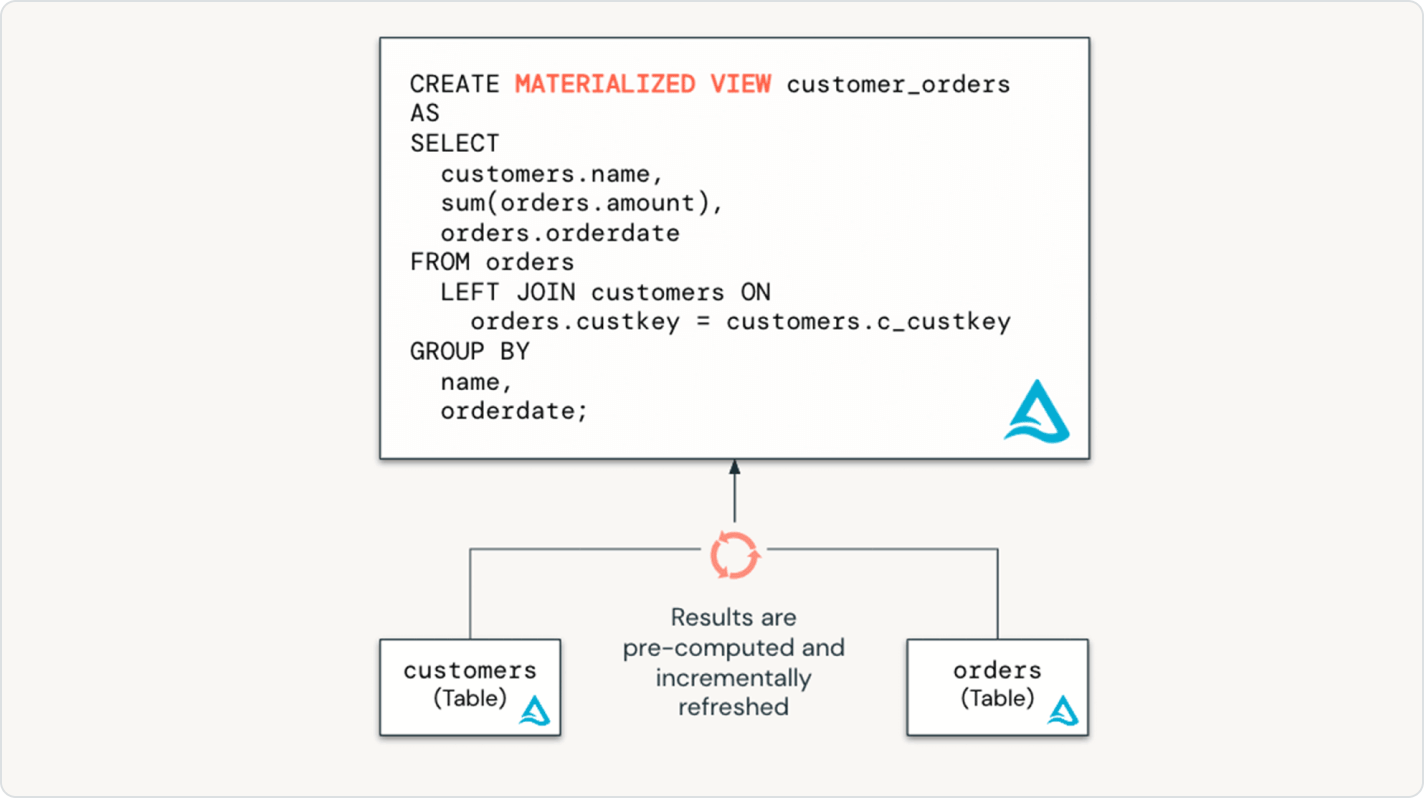
Integre perfeitamente as melhores práticas de engenharia de dados ao mundo do data warehousing
Com os Spark Declarative Pipelines, os usuários de data warehouse têm todo o poder do ETL declarativo por meio de uma interface SQL acessível. Capacite seus analistas de SQL com pipelines de dados de baixo código e sem necessidade de infraestrutura, liberando dados atualizados para a empresa com configuração mínima ou dependências.
Explore as demonstrações dos Spark Declarative Pipelines
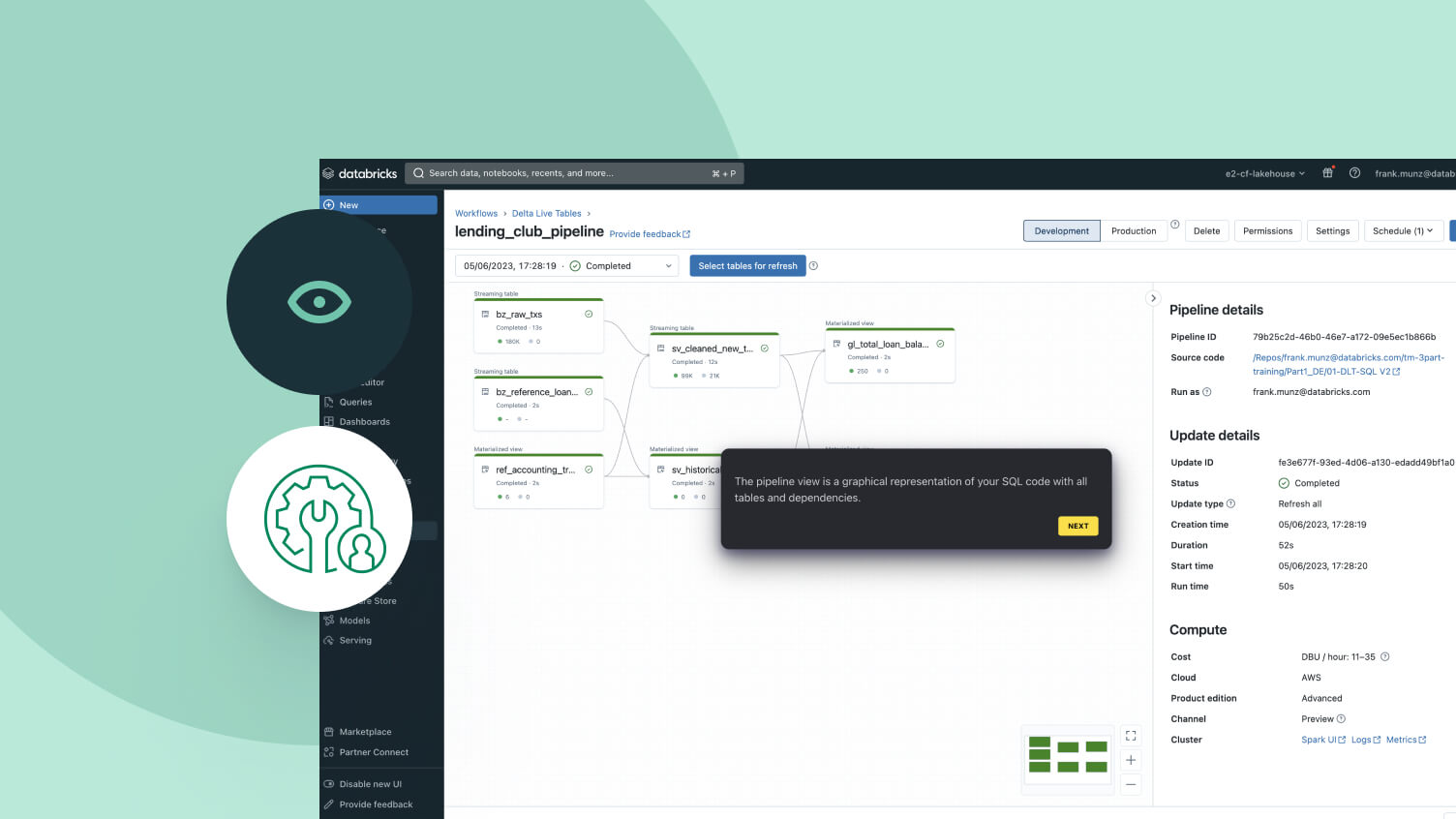
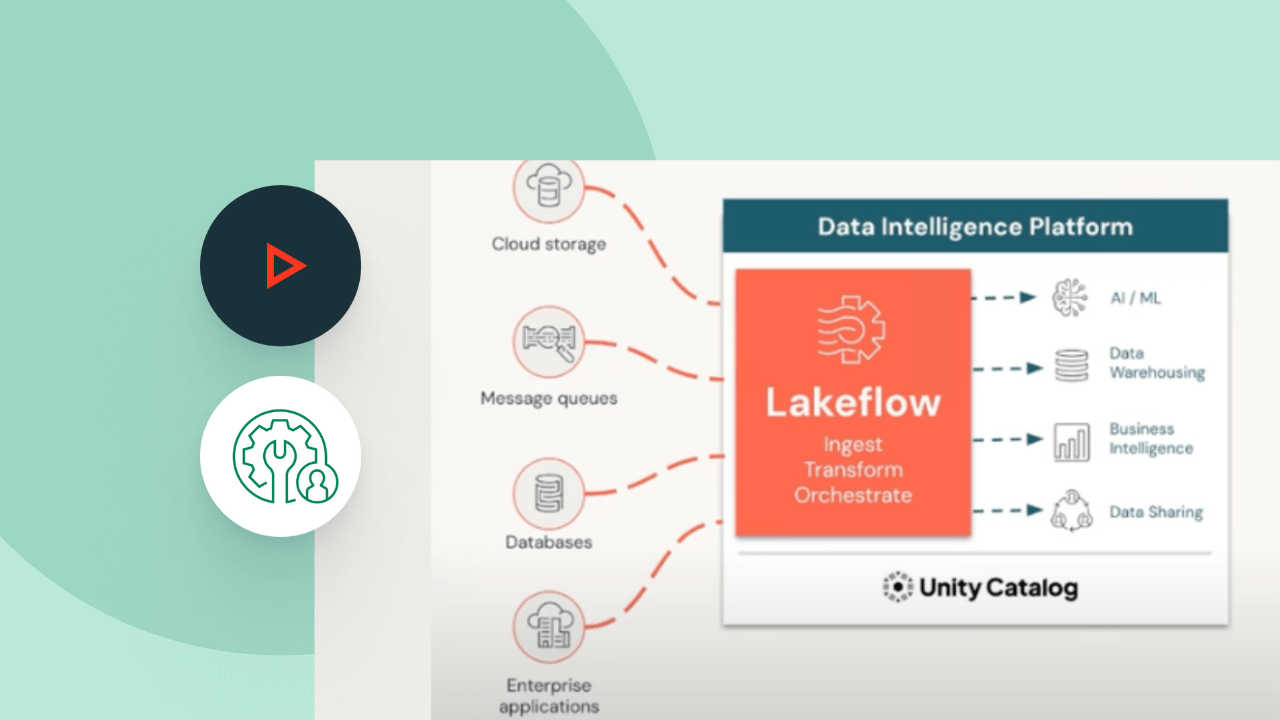
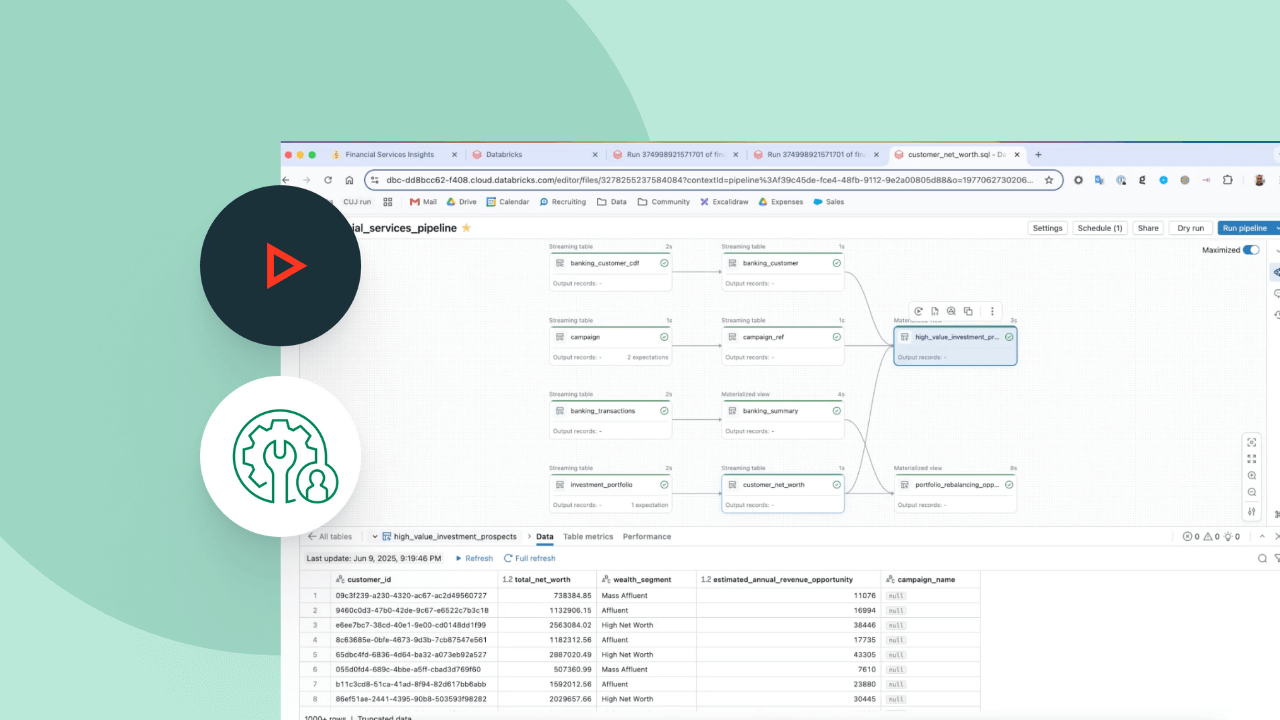
O preço baseado no uso ajuda a controlar despesas
Pague apenas pelos produtos que usar por segundo.Descubra mais
Explore outras ofertas integradas e inteligentes na plataforma de inteligência de dados.
LakeFlow Connect
Conectores eficientes de data ingestion de qualquer fonte e integração nativa com a Plataforma de Inteligência de Dados desbloqueiam fácil acesso a analytics e AI, com governança unificada.

Jobs do Lakeflow
O Workflows permite definir, gerenciar e monitorar facilmente fluxos de trabalho multitarefa para ETL, análises e pipelines de machine learning. Com uma ampla variedade de tipos de tarefas compatíveis, recursos de observabilidade detalhada e alta confiabilidade, suas equipes de dados podem automatizar e orquestrar melhor qualquer pipeline e aumentar a produtividade.

Armazenamento lakehouse
Unifique os dados em seu lakehouse, em todos os formatos e tipos, para todas as suas cargas de trabalho de analytics e AI.

Unity Catalog
Governe sem esforço todos os seus ativos de dados com a única solução de governança unificada e aberta do setor para dados e AI, integrada à Databricks Data Intelligence Platform.
Plataforma de Inteligência de Dados
Descubra como a plataforma Databricks Data Intelligence permite seus dados e cargas de trabalho de IA.
Dê um passo adiante
Conteúdo relacionado




PERGUNTAS FREQUENTES SOBRE OS Spark Declarative Pipelines
Pronto para se tornar uma empresa de dados + AI?
Dê os primeiros passos em sua transformação