ETL (Extrair, Transformar e Carregar)

O que é ETL?
À medida que as organizações crescem em dados, fontes de dados e tipos de dados, torna-se mais importante focar em analítica, ciência de dados e machine learning para aproveitar os dados e gerar percepções de negócios. Uma etapa fundamental para avançar com esse esforço é o processamento de dados brutos e díspares em dados limpos, atualizados e confiáveis. Portanto, a necessidade de priorizar esse esforço coloca mais pressão nas equipes de engenharia de dados. O ETL, sigla em inglês que significa Extrair, Transformar e Carregar, é o processo pelo qual os engenheiros de dados extraem dados de várias fontes, transformam esses dados em recursos utilizáveis e confiáveis e os carregam em sistemas que podem ser acessados pelos usuários finais. Isso permite que os dados sejam aproveitados downstream para resolver problemas de negócios.
Continue explorando



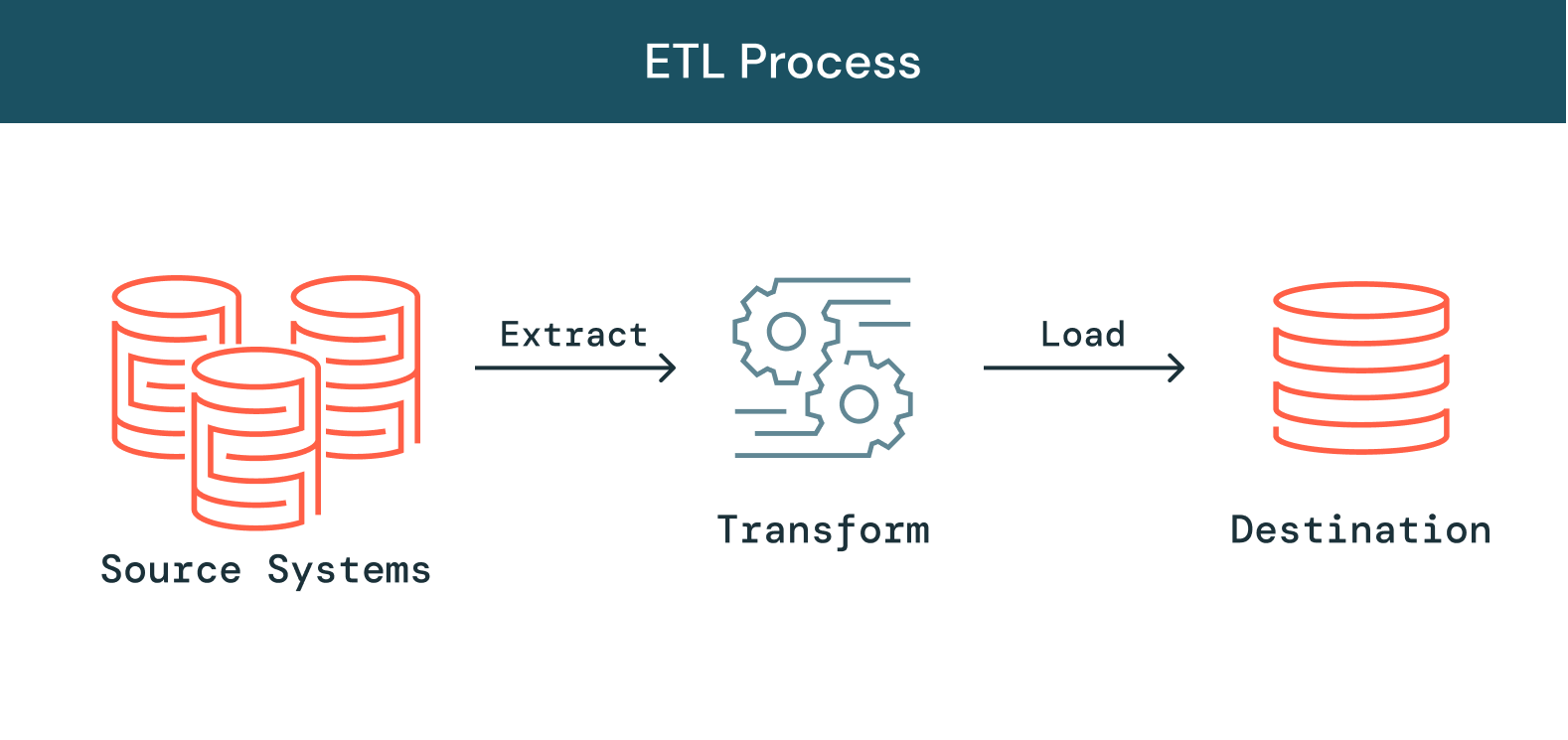
Como funciona o ETL?
Extrair
A primeira etapa é a extração de dados de uma variedade de fontes tipicamente heterogêneas, como sistemas operacionais, APIs, dados de sensores, ferramentas de marketing e bancos de dados transacionais. Como você sabe, alguns desses tipos de dados são saídas estruturadas mais prováveis de sistemas amplamente usados, enquanto outros são logs de servidor JSON semiestruturados. Existem diferentes maneiras para executar a extração:
-
Extração parcial: a maneira mais fácil de obter os dados é quando o sistema de origem notifica você quando os registros são alterados.
-
Extração parcial (com notificação de atualização): nem todos os sistemas podem fornecer uma notificação caso ocorra uma atualização, mas podem especificar registros alterados e extrair esses registros.
-
Extração completa: existem sistemas que não conseguem identificar os dados alterados. Neste caso, pode ser possível extrair dados do sistema apenas por extração completa. Este método requer que uma cópia da última extração esteja no mesmo formato para que as alterações feitas possam ser identificadas.
Transformar
A segunda etapa é transformar os dados brutos extraídos da fonte em um formato que possa ser utilizado por diferentes aplicativos. Os dados são limpos, mapeados e transformados (geralmente em um esquema de dados específico) para atender às necessidades operacionais. Durante este processo, vários tipos de transformações são realizados para garantir a qualidade e a integridade dos dados. Os dados normalmente não são carregados diretamente no data warehouse de destino, mas sim carregados em um banco de dados de preparação. Essa etapa garante uma reversão rápida se algo não sair como planejado. Durante esta fase, você pode criar relatórios de auditoria para conformidade regulatória e diagnosticar e corrigir problemas de dados.
Carregar
Por fim, a função de carregamento é o processo de gravação dos dados transformados da área de preparação para o banco de dados de destino, que podem ou não ter existido anteriormente nesse banco de dados. Este processo pode ser muito simples ou complexo, dependendo dos requisitos da aplicação. Cada uma dessas etapas pode ser realizada com uma ferramenta ETL ou código personalizado.
O que é um pipeline ETL?
Um pipeline ETL (ou pipeline de dados) é um mecanismo para executar o processamento ETL. Um pipeline de dados é um conjunto de ferramentas e atividades que movem dados de um sistema que os armazena e processa para outro que os armazena e gerencia de maneira diferente. Além disso, os pipelines obtêm automaticamente informações de fontes distintas, transformam-nas e consolidam-nas em um único armazenamento de dados de alto desempenho.
Desafios com ETL
ETL é essencial. No entanto, devido ao rápido aumento das fontes de dados e à diversificação dos tipos de dados, a realidade é que construir e manter pipelines de dados altamente confiáveis tornou-se uma tarefa difícil para a data engineering. Em primeiro lugar, criar um pipeline que possa garantir a confiabilidade dos dados é demorado e difícil. Os pipelines de dados são criados com código complexo e capacidade de reutilização limitada. Os pipelines pré-construídos não podem ser usados em ambientes diferentes, mesmo que o código subjacente seja quase idêntico. Como resultado, os engenheiros de dados precisam desenvolver pipelines do zero a cada vez, o que pode se tornar um gargalo. Além disso, existem outros desafios além do desenvolvimento do pipeline, como o gerenciamento da qualidade dos dados em arquiteturas de pipeline cada vez mais complexas. Dados de baixa qualidade geralmente passam pelo pipeline sem ser detectados, desvalorizando todo o conjunto de dados. Manter a qualidade e garantir insights confiáveis requer verificação de qualidade e validação do pipeline em cada etapa, exigindo que os engenheiros de dados escrevam código personalizado extenso. Além disso, à medida que os pipelines crescem em tamanho e complexidade, aumenta a carga do gerenciamento de pipeline nas empresas, tornando extremamente difícil manter a confiabilidade dos dados. A infraestrutura de processamento de dados precisa ser configurada, dimensionada, reinicializada, corrigida e atualizada. Isso adiciona tempo e custos. Falhas de pipeline são difíceis de identificar e ainda mais difíceis de resolver devido à falta de visibilidade e ferramentas. Apesar desses desafios, o ETL confiável é um processo essencial para qualquer empresa que busca obter insights orientados por dados. Sem ferramentas de ETL que mantêm um padrão de confiabilidade de dados, as equipes em toda a empresa são obrigadas a tomar decisões cegamente sem métricas ou relatórios confiáveis. Para escalar continuamente, os engenheiros de dados precisam de ferramentas que simplifiquem e democratizem o ETL, facilitem o ciclo de vida do ETL e permitam que as equipes de dados criem e aproveitem pipelines de dados para obter insights mais rapidamente.
Automatize ETL confiável com o Delta Lake
O Delta Live Tables (DLT) facilita a criação e o gerenciamento de pipelines confiáveis que fornecem dados de alta qualidade no Delta Lake. O DLT ajuda as equipes de data engineering a simplificar o desenvolvimento e o gerenciamento de ETL com desenvolvimento de pipeline declarativo, teste automatizado e visibilidade profunda para monitoramento e restauração.
