O que é o Apache Spark?
Um mecanismo de análise unificado para processamento de dados distribuídos em larga escala, com APIs em Java, Scala, Python e R para processamento em lote, fluxo contínuo, aprendizado de máquina e grafos.
Summary
- Construído sobre conjuntos de dados distribuídos resilientes (RDDs), permitindo operações paralelas em memória tolerantes a falhas com avaliação preguiçosa, proporcionando melhorias de velocidade de 10 a 100 vezes em relação ao Hadoop MapReduce para cargas de trabalho iterativas.
- Fornece API DataFrame com otimizador Catalyst para planejamento de consultas e mecanismo de execução Tungsten para gerenciamento de memória, com suporte a consultas SQL e processamento de dados estruturados.
- Inclui MLlib para aprendizado de máquina distribuído, Structured Streaming para processamento em tempo real e GraphX para análise de grafos, todos compartilhando a mesma estrutura de execução.
O que é o Apache Spark?
O Apache Spark é um mecanismo de análise de código aberto usado para cargas de trabalho de big data. Ele consegue lidar com lotes, cargas de trabalho de análise e processamento de dados em tempo real. O Apache Spark começou em 2009 como um projeto de pesquisa na Universidade da Califórnia, Berkeley. Os pesquisadores procuravam uma maneira de acelerar o processamento de jobs nos sistemas Hadoop. Ele é baseado no Hadoop MapReduce e amplia o modelo MapReduce para usá-lo com eficiência em mais tipos de cálculos, o que inclui queries interativas e processamento de stream. O Spark fornece ligações nativas para as linguagens de programação Java, Scala, Python e R. Além disso, inclui várias bibliotecas para permitir a criação de aplicações para machine learning [MLLib], processamento de stream [Spark Streaming] e processamento gráfico [GraphX]. O Apache Spark consiste no Spark Core e em um conjunto de bibliotecas. O Spark Core é a parte central do Apache Spark, responsável por fornecer transmissão distribuída de tarefas, agendamento e funcionalidade de E/S. O mecanismo Spark Core usa o conceito de um Resilient Distributed Dataset (RDD) como tipo de dados básico. O RDD foi projetado para ocultar a maior parte da complexidade computacional dos usuários. O Spark é inteligente na operação com dados; dados e partições são agregados em um cluster de servidores, onde podem ser computados e movidos para um armazenamento de dados diferente ou executados por meio de um modelo analítico. Você não precisará especificar o destino dos arquivos ou os recursos computacionais que precisam ser usados para armazenar ou recuperar arquivos. 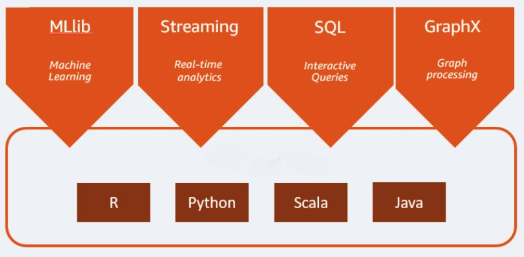
O manual de IA agêntica para empresas

Quais são os benefícios do Apache Spark?
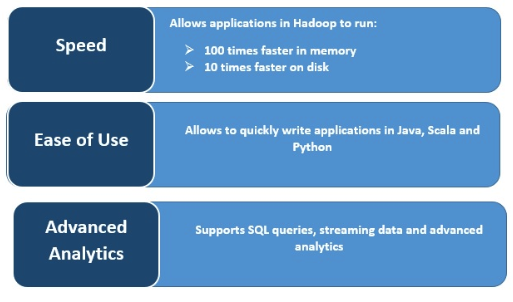
Velocidade
O Spark executa com muita rapidez, armazenando em cache os dados na memória em várias operações paralelas. O principal recurso do Spark é o mecanismo na memória que aumenta a velocidade de processamento, tornando-o até 100 vezes mais rápido do que o MapReduce quando processado na memória e 10 vezes mais rápido no disco, quando se trata de processamento de dados em grande escala. O Spark torna isso possível ao reduzir o número de operações de leitura/gravação em disco.
Processamento de stream em tempo real
O Apache Spark lida com streaming em tempo real junto com a integração de outras estruturas. O Spark ingere dados em minilotes e realiza transformações de RDD nesses minilotes de dados.
Compatível com várias cargas de trabalho
O Apache Spark executa várias cargas de trabalho, incluindo queries interativas, análise em tempo real, machine learning e processamento gráfico. Uma aplicação pode combinar várias cargas de trabalho sem problemas.
Maior usabilidade
A compatibilidade com várias linguagens de programação o torna dinâmica. Ele permite escrever aplicações rapidamente em Java, Scala, Python e R, oferecendo diversas linguagens para criar suas aplicações.
Análise avançada
O Spark é compatível com queries SQL, machine learning, processamento de stream e processamento gráfico.