Photon
A engine de última geração para o Lakehouse
O Photon é a engine de última geração da Plataforma Databricks Lakehouse que oferece desempenho de query extremamente rápido a um custo baixo para ingestão de dados, ETL, streaming, data science e queries interativas, diretamente no seu data lake. O Photon é compatível com a API Apache Spark™. Portanto, basta “virar o botão” para começar, sem alterações de código ou outras restrições.
Cheaper and faster
Built from the ground up for the fastest performance at lower cost, Photon provides up to 80% TCO savings while accelerating data and analytics workloads — up to 12x speedups.
Built for all use cases
Photon is the first engine that enables data teams to standardize on one set of APIs for all workloads — ETL, analytics and data science — in batch or streaming.
No code changes
Photon is an ANSI-compliant engine designed to be compatible with modern Apache Spark APIs and just works with your existing code — SQL, Python, R, Scala and Java — no rewrite required.
Por que Photon?
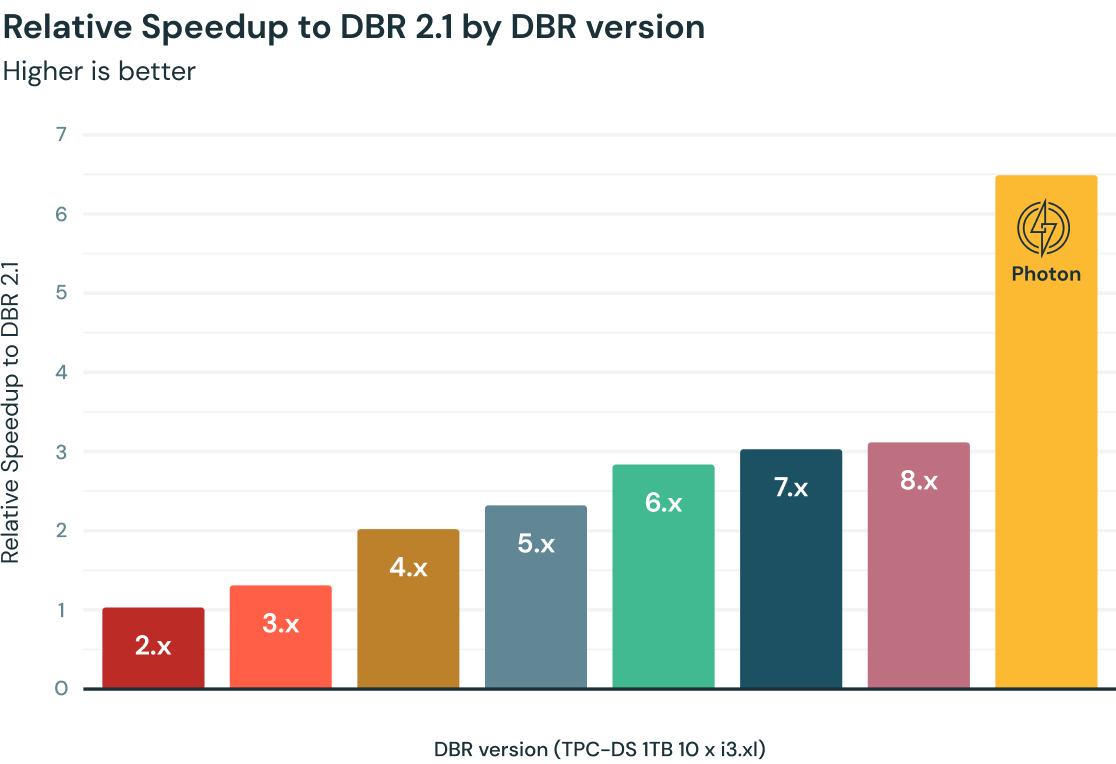
O desempenho da query na Databricks melhorou progressivamente ao longo dos anos, graças ao Apache Spark e milhares de otimizações fornecidas como parte do Databricks Runtimes (DBR). O Photon, uma nova engine nativa vetorizada escrita inteiramente em C++, oferece o dobro de velocidade adicional no benchmark TPC-DS 1TB. Além disso, os clientes observaram velocidades de três a oito vezes mais rápidas em média, dependendo da carga de trabalho, em comparação com as versões mais recentes do DBR.
Casos de uso

Production jobs
Accelerate large-scale production jobs on SQL and Spark DataFrames

IoT applications
Faster time-series analysis using Photon compared to Spark and traditional Databricks Runtime

Data privacy and compliance
Query petabyte-scale data sets to identify and delete records without duplicating data with Delta Lake, production jobs and Photon

Loading data into Delta Lake and Parquet
Photon’s vectorized I/O speeds up data loads for Delta Lake and Parquet tables, lowering overall runtime and the cost of data engineering jobs
Como funciona?
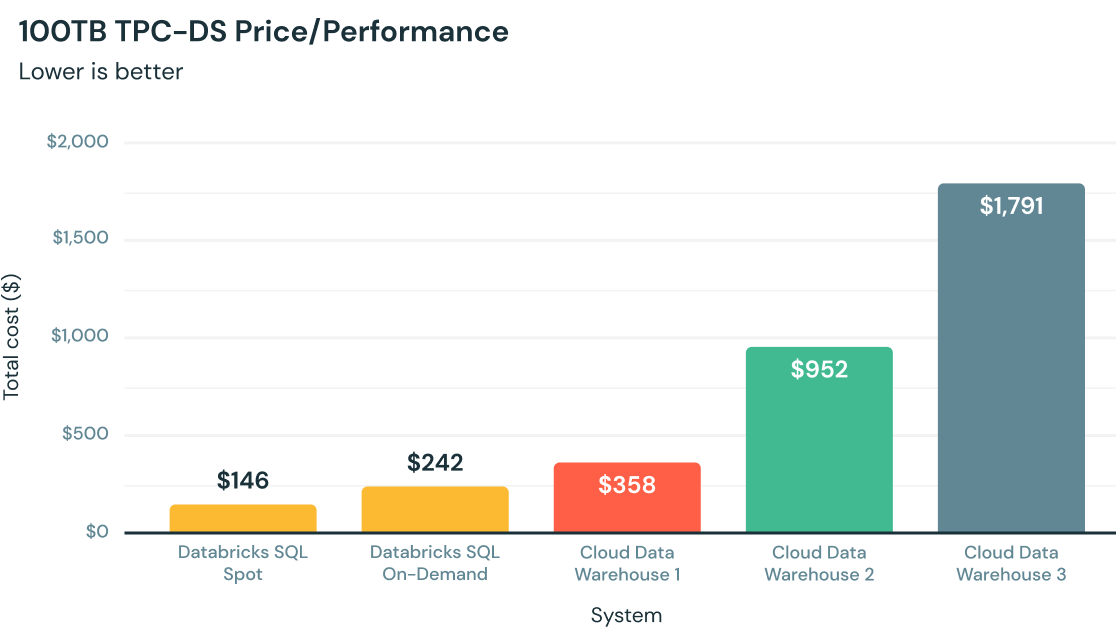
Melhor preço/desempenho para análises na nuvem
Escrito desde o início em C++, o Photon usa hardware moderno para queries mais rápidas, com preço/desempenho até 12 vezes melhor do que outros data warehouses em nuvem, tudo nativamente no seu data lake.
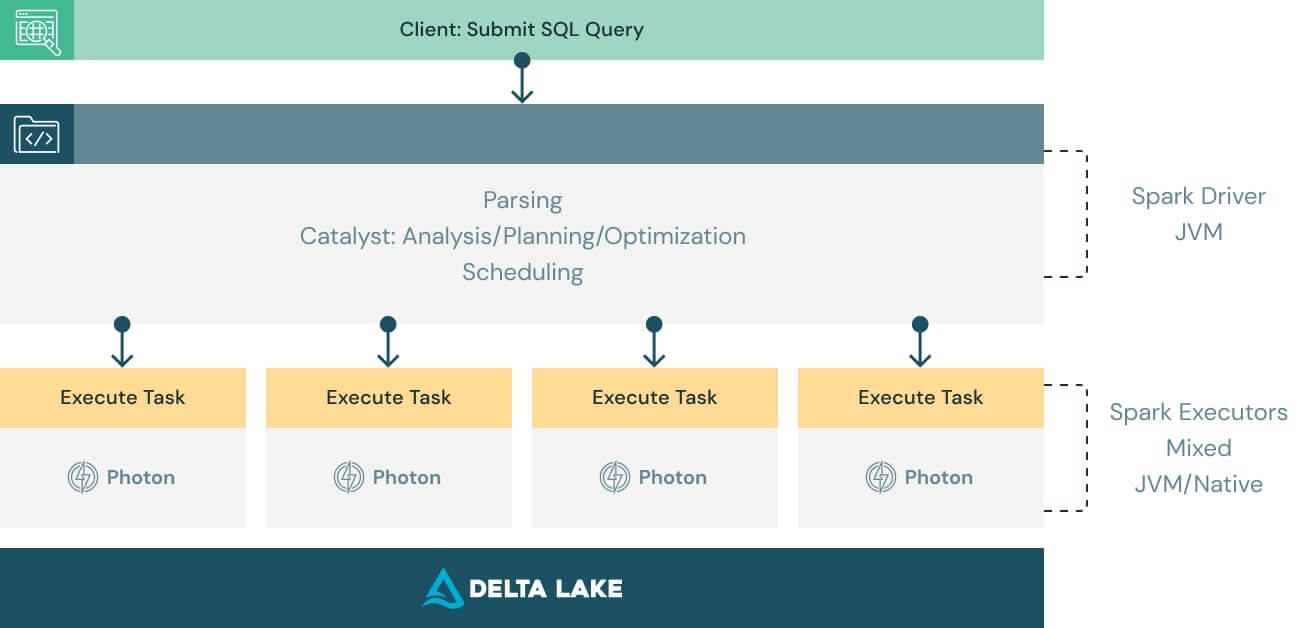
Funciona com código existente e não se compromete com nenhum provedor
O Photon foi projetado para ser compatível com Apache Spark DataFrame e APIs SQL, para garantir que as cargas de trabalho sejam executadas sem problemas e sem alterações de código. Tudo o que você precisa fazer para colher os benefícios do Photon é “girar a chave”. O Photon coordenará o trabalho e os recursos de maneira totalmente integrada e acelerará de forma transparente partes das queries SQL e Spark. Nenhum ajuste ou intervenção do usuário é necessário.

Otimize para todos os casos de uso e cargas de trabalho de dados
O Photon nasceu com foco no SQL para fornecer aos clientes desempenho avançado de data warehouse em seus data lakes, mas desde então expandimos a oferta de fontes de aquisição, formatos, APIs e métodos suportados pelo Photon. Os clientes se beneficiaram, portanto, de reduções drásticas nos custos de infraestrutura e maior velocidade no Photon em todas as suas cargas de trabalho Spark (por exemplo, Spark SQL e DataFrame).
Recursos
Recursos
Artigos
Eventos
Blogs
Tudo pronto para começar?