Costruito per l'archiviazione di dati aperti e intelligenti
Scegli dove archiviare i tuoi dati e in quale formato, mantenendone piena proprietà e portabilit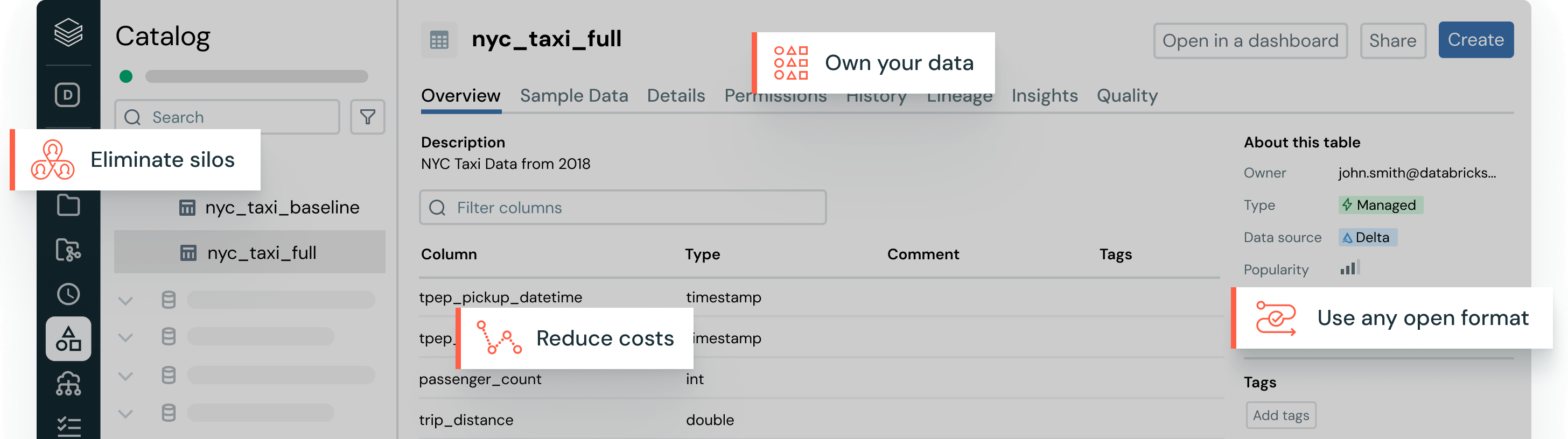
IL SUCCESSO DEI MIGLIORI TEAM POGGIA SULLA DATA INTELLIGENCE
Archiviazione Lakehouse flessibile e veloce
Elimina i problemi di gestione dei dati con formati di tabella aperti, governance centralizzata e ottimizzazioni automatiche dei dati.Formati compatibili
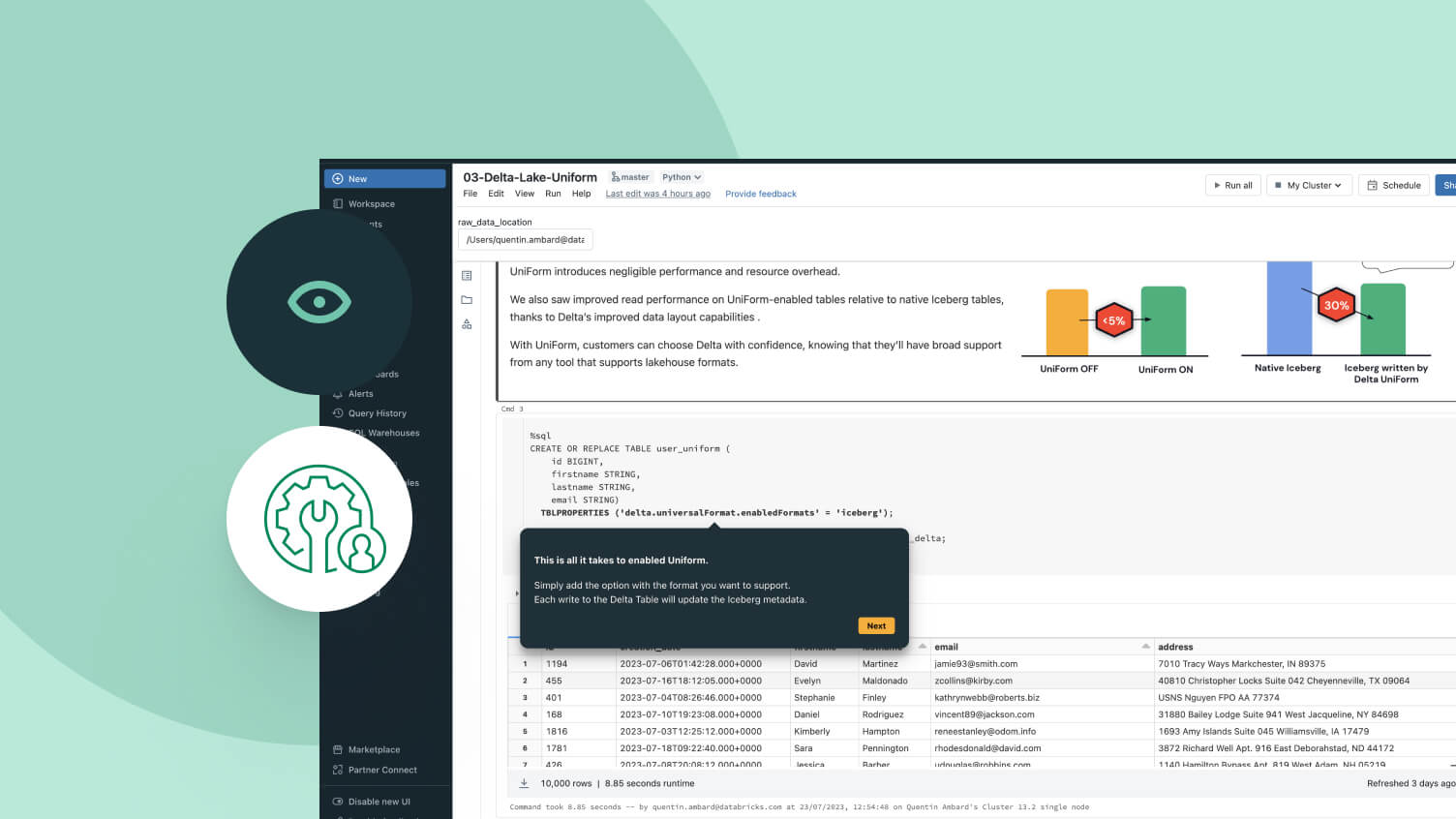
Una singola copia dei dati di origine in Delta Lake o Apache Iceberg™ che può essere accessibile da qualsiasi motore.
Governance unificata
Un singolo catalogo per la scoperta dei dati e la governance, attraverso i tuoi dati e asset AI.
Prestazioni guidate dall'AI
I modelli alimentati da AI ottimizzano e mantengono autonomamente i dati per velocità e basso costo.
I tuoi dati, a tuo modo
Scegli la posizione di archiviazione e il formato aperto che funziona per te. Mantieni i tuoi dati portabili, senza il blocco del fornitore.Prestazioni di lettura e scrittura di prim'ordine per le tabelle Delta Lake e Apache Iceberg™, pronte all'uso, con ottimizzazioni di archiviazione non disponibili in nessun altro lakehouse.
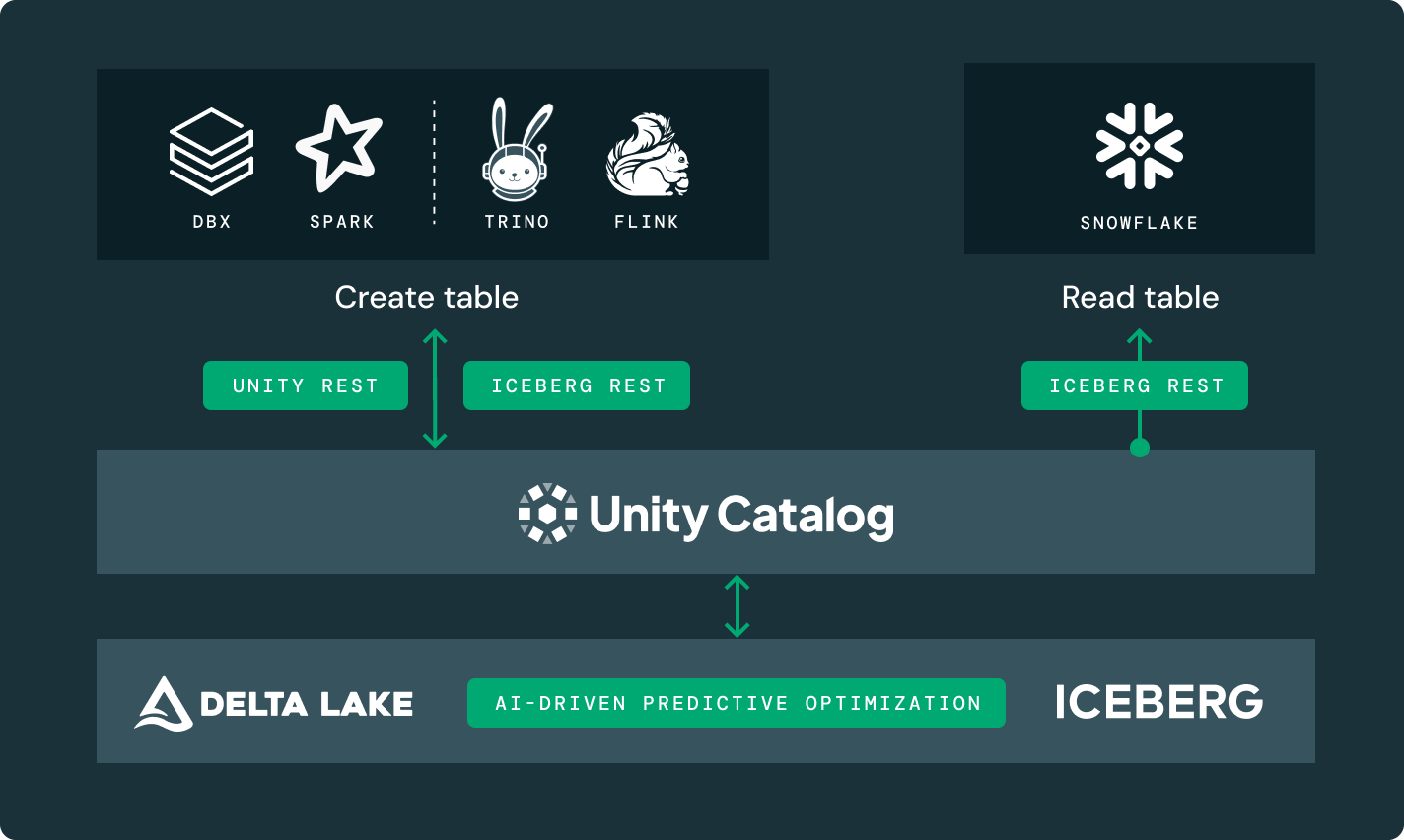
Accedi a tabelle gestite da cataloghi esterni come Glue, HMS e Snowflake Horizon e sfrutta le funzionalità avanzate del Catalogo Unity come i controlli di accesso a grana fine.
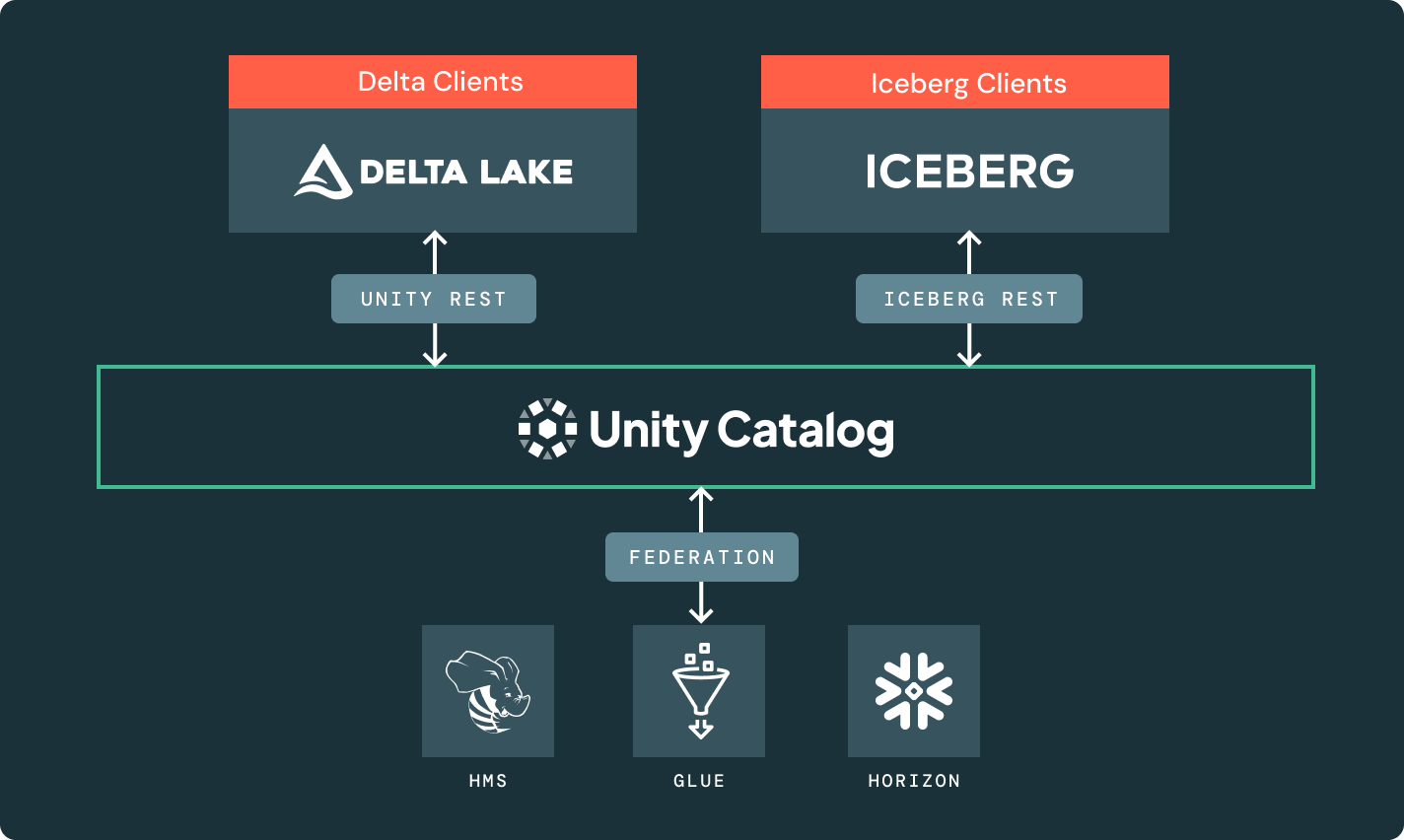
Le API del Catalogo REST di Unity e Iceberg sbloccano l'intero ecosistema del lakehouse, attraverso formati e motori.
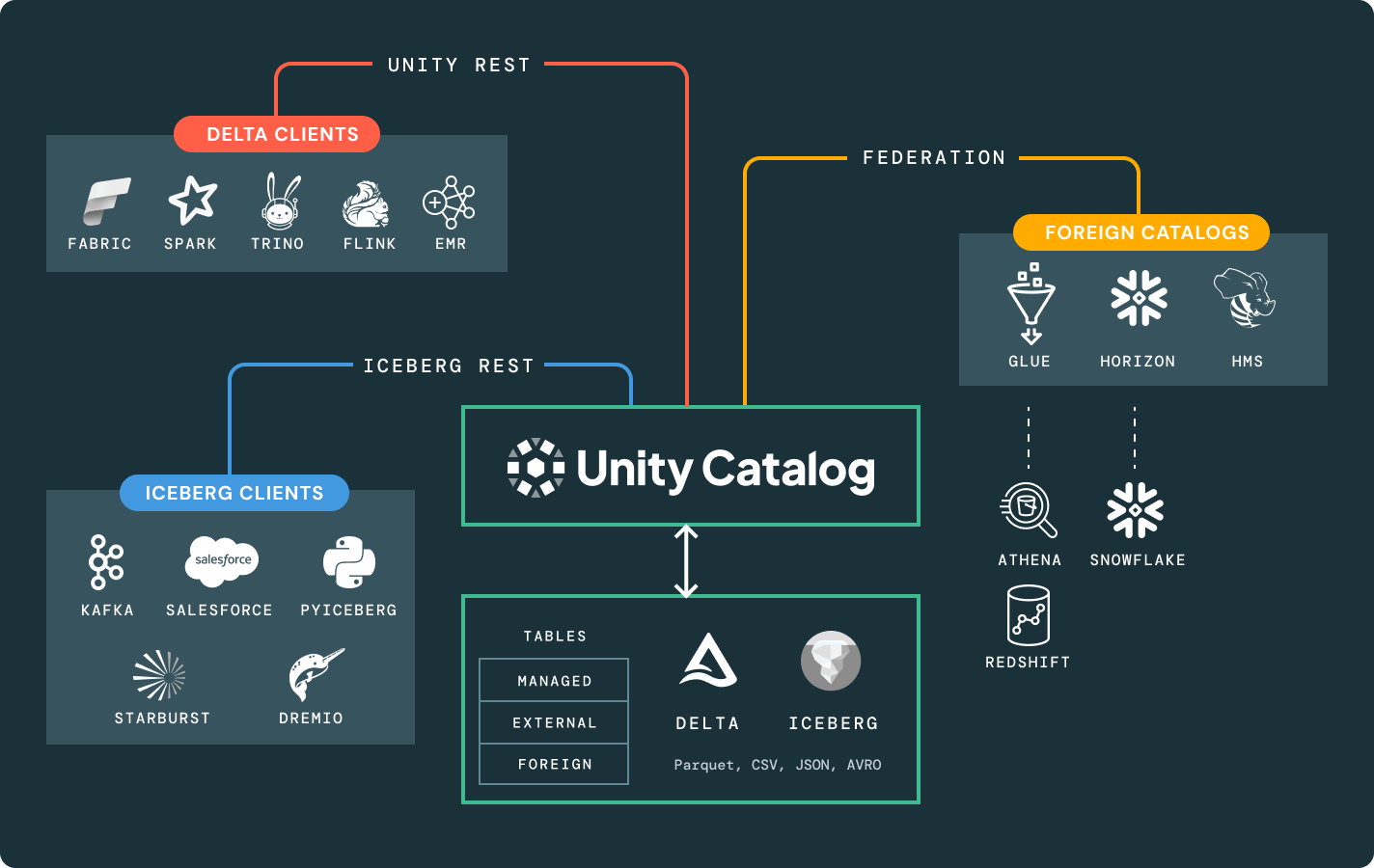
Altre funzioni
Per tutti i tuoi carichi di lavoro di analisi e AI

Costruisci e gestisci pipeline di dati affidabili
Le tabelle gestite fungono sia da tabelle batch che da fonte e destinazione di streaming. Acquisizione di dati in streaming, caricamenti di dati storici in batch e query interattive sono tutte operazioni che funzionano "out of the box" e si integrano direttamente con Spark Structured Streaming.
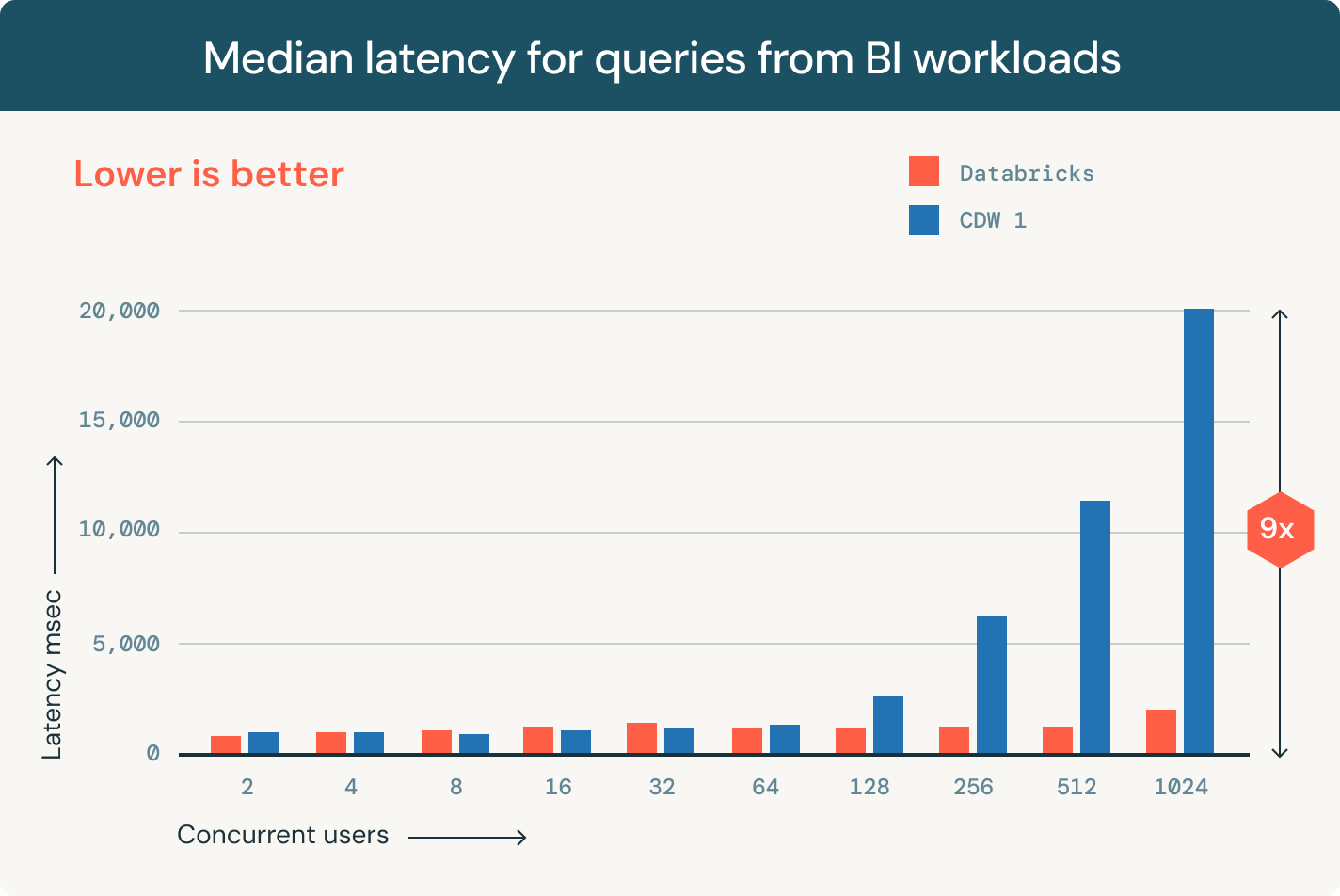

Scopri, governa e condividi i tuoi dati e le tue risorse di intelligenza artificiale
Scopri come la Databricks Data Intelligence Platform supporta i tuoi team di dati in tutti i carichi di lavoro di dati e AI.
Unity Catalog
Integrata nella Databricks Data Intelligence Platform, è l'unica soluzione di governance unificata e aperta del settore per dati e AI.

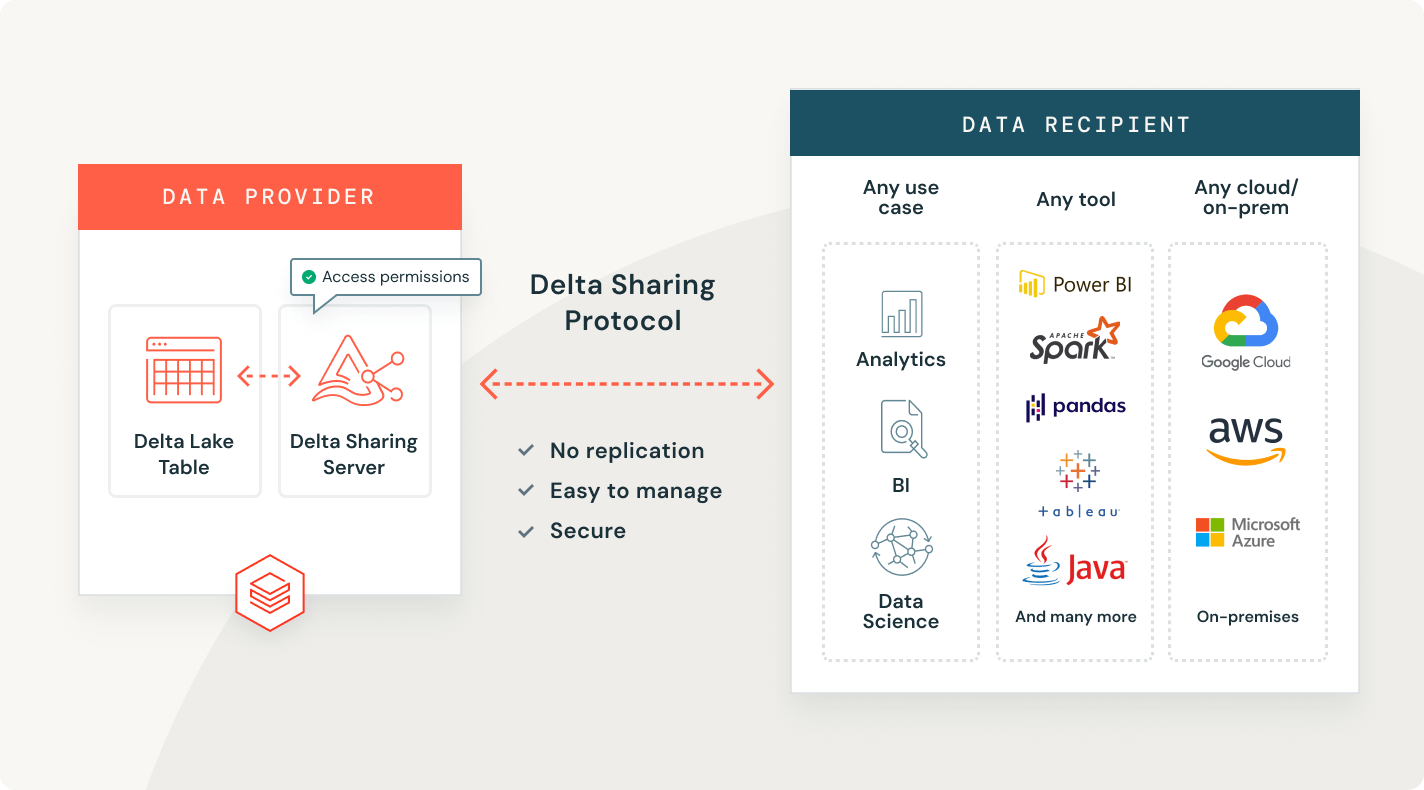
Delta Sharing
Il primo approccio open source alla condivisione di dati tra dati, analisi e AI. Condividi dati live in modo sicuro tra piattaforme, cloud e regioni.

Data Intelligence Platform
Esplora l'intera gamma di strumenti disponibili sulla Databricks Data Intelligence Platform per integrare perfettamente dati e AI in tutta l'organizzazione.
Maggiori informazioni




FAQ sulla memorizzazione Lakehouse
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il percorso di trasformazione