Partner Connect
Scopri e integra facilmente soluzioni per dati, analisi e AI con il lakehouse
Partner Connect aiuta a scoprire strumenti di gestione e analisi dei dati e di AI sulla piattaforma Databricks, integrandoli velocemente con gli strumenti già in uso. Con Partner Connect, per l'integrazione di nuovi strumenti bastano pochi clic e le funzionalità del lakehouse possono essere ampliate velocemente.
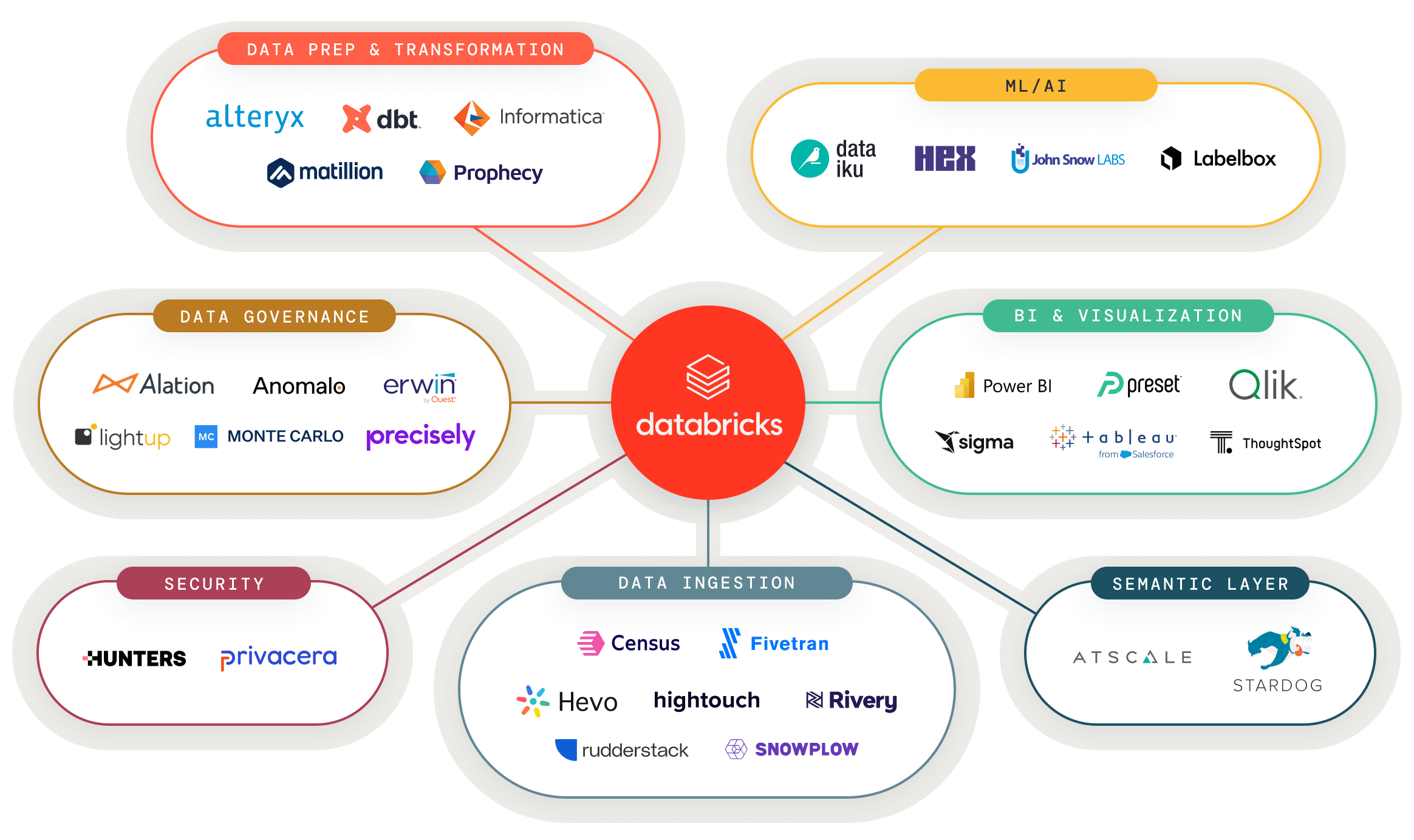
Collegare al lakehouse gli strumenti per la gestione di dati e AI
Connetti facilmente i tuoi strumenti preferiti per dati e AI al lakehouse e alimenta qualsiasi caso d'uso di analisi

Soluzioni validate per dati e AI per nuovi casi d'uso
Un portale unico con le soluzioni validate di aziende partner per costruire più velocemente le prossime applicazioni di gestione dei dati
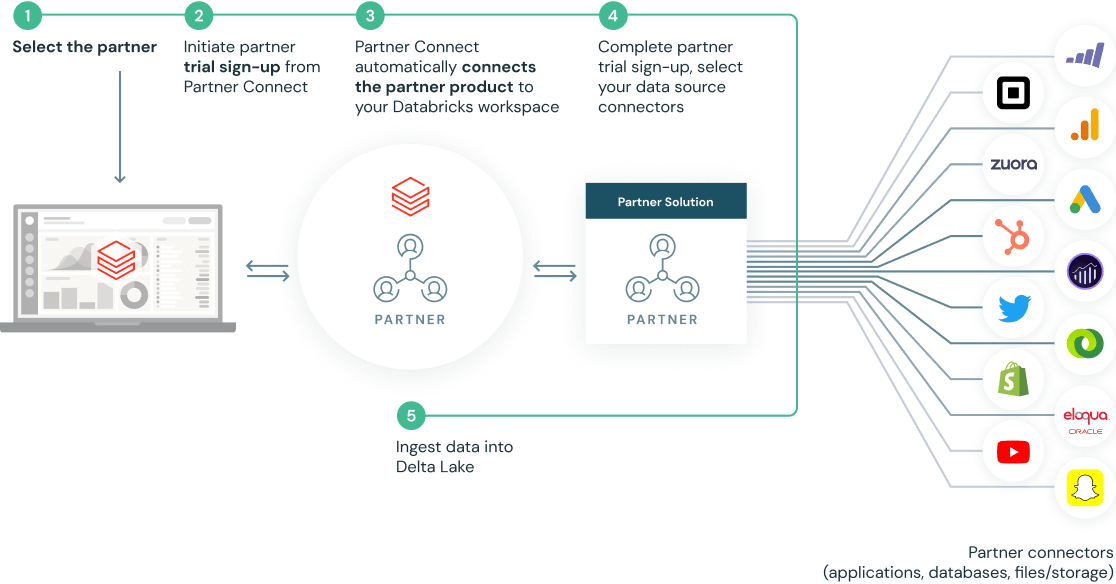
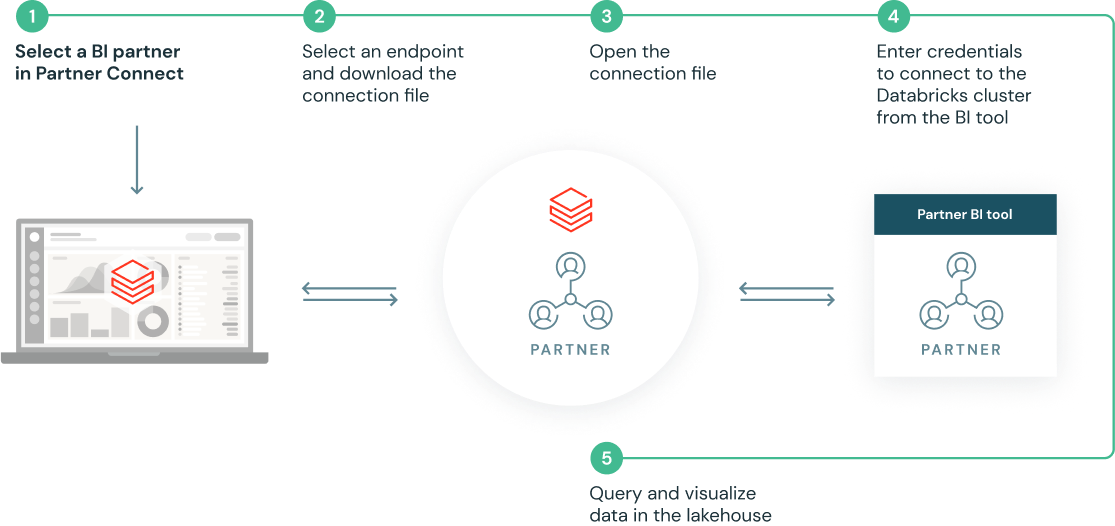
Impostazione in pochi clic con integrazioni predefinite
Partner Connect semplifica le integrazioni configurando automaticamente le risorse (inclusi cluster, token e file di connessione) per la connessione con le soluzioni dei nostri partner
Primi passi come partner
I partner di Databricks sono in una posizione unica per offrire ai clienti analisi approfondite più velocemente. Sfrutta le risorse di sviluppo e le partnership di Databricks per crescere insieme alla nostra piattaforma aperta in cloud.
Demo
Risorse
Blog
Documentazione
Pronto per saperne di più?
Sfrutta le risorse di sviluppo e le partnership di Databricks per crescere insieme alla nostra piattaforma aperta in cloud