Extract Transform Load (ETL)

Cosa significa ETL?
Mentre le organizzazioni si trovano a dover gestire volumi sempre maggiori di dati di diverso tipo provenienti da diverse sorgenti, aumenta anche l'esigenza di utilizzare tali dati in iniziative analitiche, di Data Science e di machine learning per ricavarne informazioni preziose. La necessità di dare priorità a queste iniziative aumenta la pressione sui team di data engineering, perché l'elaborazione dei dati grezzi e disordinati per trasformarli in dati puliti, aggiornati e affidabili è un passo fondamentale e preliminare a queste iniziative. ETL, acronimo di "extract, transform and load", è il processo che i data engineer utilizzano per estrarre i dati da fonti diverse, trasformarli in risorse utilizzabili e affidabili e caricarli nei sistemi a cui gli utenti finali possono accedere per utilizzarli a valle nella risoluzione di problemi aziendali.
Ecco altre informazioni utili



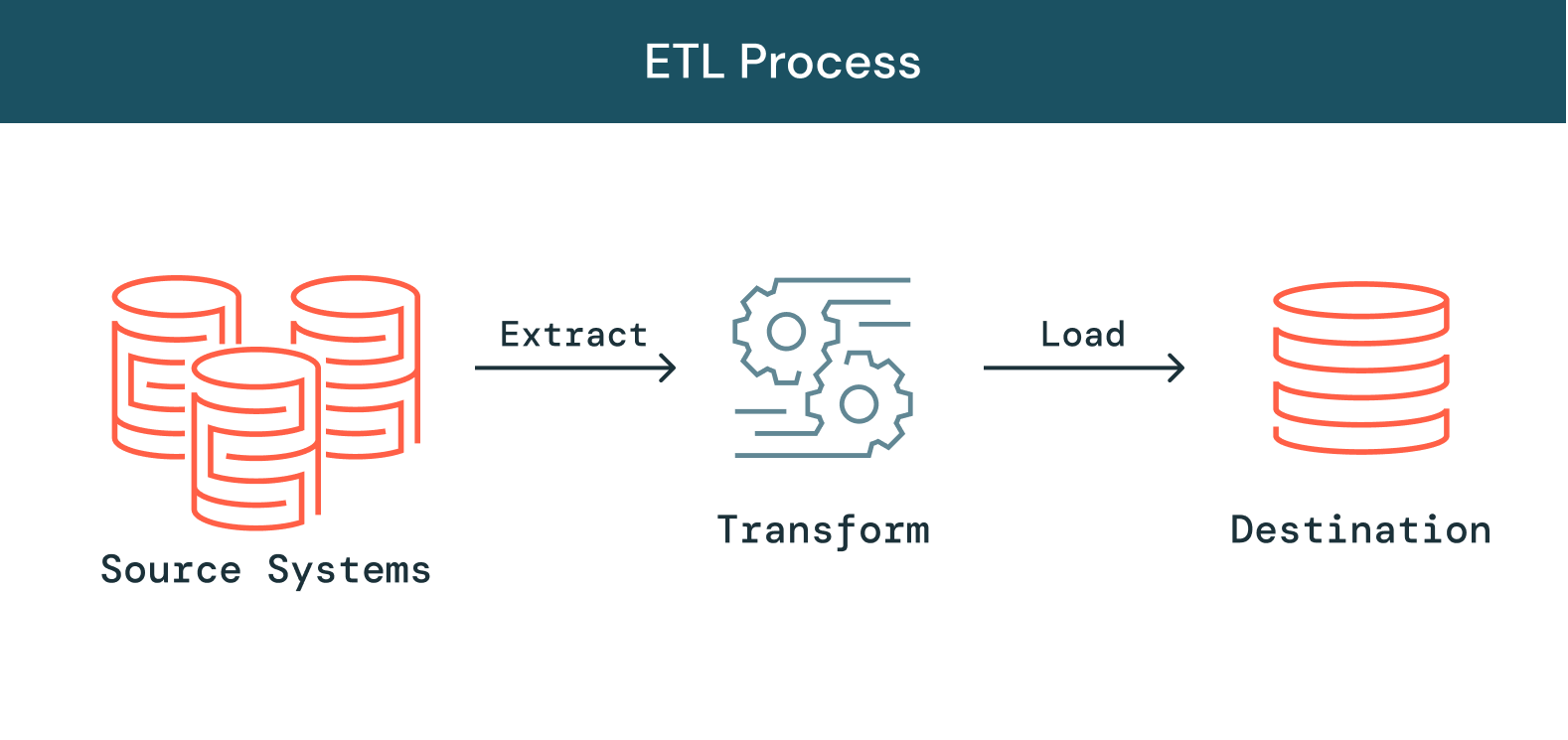
Come funziona l'ETL?
Estrazione
La prima fase di questo processo consiste nell'estrarre i dati dalle fonti di destinazione, che di solito sono eterogenee e includono sistemi aziendali, API, dati di sensori, strumenti di marketing, database delle transazioni e altro. Come si può vedere, alcuni di questi tipi di dati sono probabilmente output strutturati di sistemi ampiamente utilizzati, mentre altri sono registri di server semi-strutturati in formato JSON. L'estrazione può essere eseguita secondo modalità diverse:
-
Estrazione parziale: il modo più semplice per ottenere i dati prevede che il sistema di origine invii una notifica quando un record viene modificato.
-
Estrazione parziale (con notifica di aggiornamento): non tutti i sistemi sono in grado di inviare una notifica in caso di aggiornamento; tuttavia, possono puntare ai record che sono stati modificati e fornirne un'estrazione.
-
Estrazione completa: alcuni sistemi non sono in grado di identificare quali dati sono stati modificati. In questo caso, l'estrazione completa è l'unica possibilità per estrarre i dati dal sistema. Questo metodo richiede di conservare una copia dell'ultima estrazione nello stesso formato, in modo da poter identificare le modifiche che sono state apportate.
Trasformazione
La seconda fase consiste nel trasformare i dati grezzi estratti dalle fonti in un formato utilizzabile da diverse applicazioni. I dati vengono puliti, mappati e trasformati, spesso secondo uno schema specifico, in modo da soddisfare le esigenze operative. Questo processo comporta diversi tipi di trasformazioni che assicurano la qualità e l'integrità dei dati. In genere, i dati non vengono caricati direttamente nella sorgente di dati di destinazione, ma in un database di staging. Questo passaggio rende possibile un rapido ripristino nel caso di imprevisti. Durante questa fase l'utente ha la possibilità di generare rapporti di audit per la conformità alle normative o di diagnosticare e riparare eventuali problemi ai dati.
Caricamento
Infine, la funzione di caricamento è il processo di scrittura dei dati convertiti da un'area di staging a un database di destinazione, che può essere preesistente o meno. A seconda dei requisiti dell'applicazione, questo processo può essere semplice o complesso. Ciascuna di queste fasi può essere eseguita con strumenti ETL o con codice personalizzato.
Cos'è una pipeline ETL?
Una pipeline ETL (o pipeline di dati) è il meccanismo con cui avvengono i processi ETL. Le pipeline di dati sono un insieme di strumenti e attività utilizzati per spostare i dati da un sistema con un proprio metodo di archiviazione ed elaborazione dei dati a un altro sistema in cui possono essere archiviati e gestiti in modo diverso. Inoltre, le pipeline consentono di ottenere automaticamente informazioni da molte fonti diverse, per poi trasformarle e consolidarle in un unico archivio dati ad alte prestazioni.
Problematiche dell'ETL
L'ETL riveste un ruolo cruciale ma alla luce dell'aumento esponenziale di sorgenti di dati e di tipologie, la costruzione e il mantenimento di pipeline di dati affidabili è diventata una delle parti più impegnative del data engineering. Fin dall'inizio, la costruzione di pipeline che garantiscano l'affidabilità dei dati è un'operazione lenta e difficile perché queste pipeline sono costruite con codice complesso e hanno una riusabilità limitata. Una pipeline integrata in un ambiente non può essere utilizzata in un altro, neanche se il codice sottostante è molto simile, il che significa che i data engineer sono spesso il collo di bottiglia e si trovano ogni volta a dover reinventare la ruota. Al di là delle difficoltà insite nello sviluppo della pipeline, anche gestire la qualità dei dati in architetture di pipeline sempre più complesse non è cosa da poco. Spesso si lascia che dei dati di cattiva qualità fluiscano attraverso una pipeline senza essere rilevati, inficiando così il valore dell'intero dataset. Per preservare la qualità dei dati e garantire informazioni affidabili, i data engineer devono scrivere ampi blocchi di codice specifico per implementare controlli di qualità e operazioni di convalida in ogni fase della pipeline. Infine, via via che le pipeline aumentano di dimensioni e di complessità, le aziende devono far fronte a un maggiore carico operativo per la loro gestione, il che rende incredibilmente difficile mantenere l'affidabilità dei dati. L'infrastruttura di elaborazione dei dati deve essere configurata, scalata, riavviata, patchata e aggiornata, con un aumento di tempi e costi. I guasti alle pipeline sono difficili da identificare e ancor più da risolvere, a causa della mancanza di visibilità e di strumenti. Indipendentemente da tutte queste sfide, un ETL affidabile è un processo assolutamente essenziale per qualsiasi azienda che ambisca a essere "insights-driven". Senza strumenti ETL che mantengano uno standard di affidabilità dei dati, i team aziendali sono costretti a prendere decisioni alla cieca senza metriche o report affidabili. Per continuare a crescere, i data engineer hanno bisogno di strumenti che snelliscano e democratizzino l'ETL, semplificando il suo ciclo di vita e consentendo ai team di dati di costruire e sfruttare le loro pipeline per arrivare più velocemente alle informazioni.
Automatizzare processi ETL affidabili su Delta Lake
Delta Live Tables (DLT) semplifica la costruzione e la gestione di pipeline affidabili che forniscono dati di alta qualità su Delta Lake. DLT aiuta i team di data engineering a semplificare lo sviluppo e la gestione di processi ETL attraverso pipeline dichiarative, test automatici sui dati e visibilità approfondita per monitoraggio e recupero.
