Aprofundando: Como a Concorrência em Nível de Linha Funciona Prontamente
Use o Agrupamento Líquido para resolução automática de conflitos concorrentes
Summary
- A concorrência em nível de linha do Databricks fornece garantias de concorrência prontas para uso para clientes com gravações concorrentes e operações de manutenção.
- Métodos tradicionais de concorrência, como loops de repetição e partição, são difíceis de usar e podem aumentar os tempos de consulta e o custo.
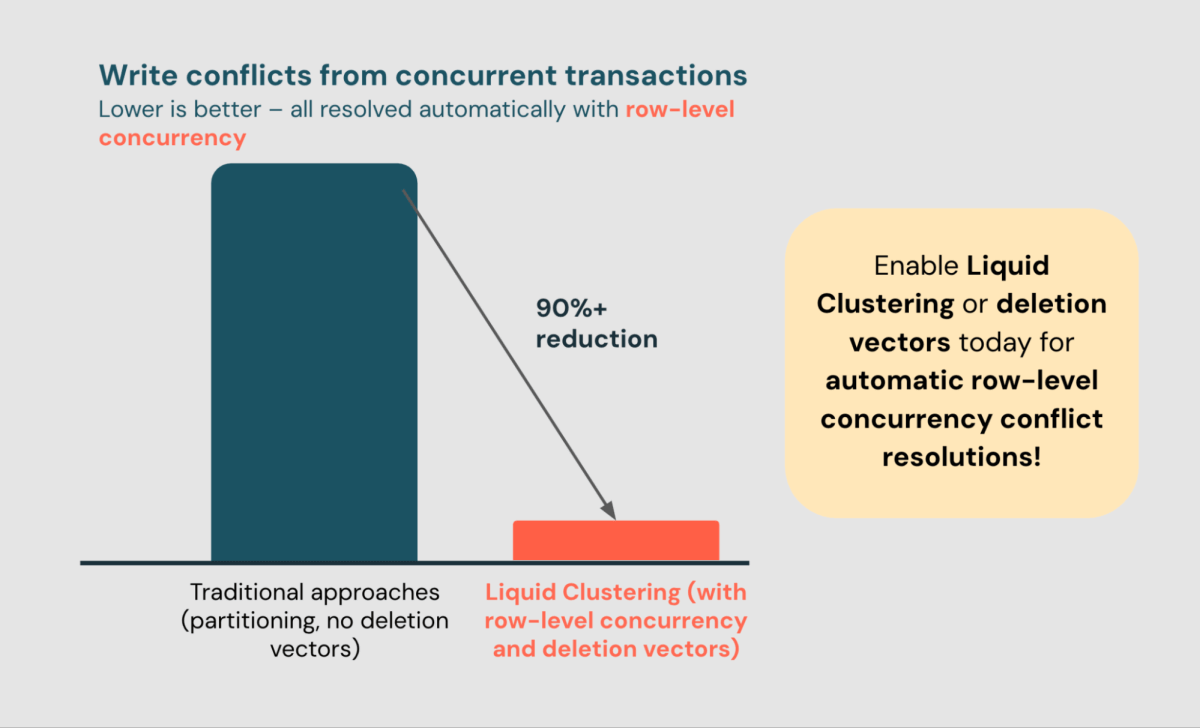
- Comece a se beneficiar da concorrência em nível de linha hoje usando o Agrupamento Líquido.
Liquid Clustering é uma técnica inovadora de gerenciamento de dados que simplifica significativamente suas decisões relacionadas ao layout de dados. Você só precisa escolher chaves de agrupamento com base nos padrões de acesso à consulta. Milhares de clientes se beneficiaram de um melhor desempenho de consulta com o Liquid Clustering, e agora temos mais de 3000 clientes ativos mensalmente escrevendo mais de 200 PB de dados em tabelas agrupadas por Liquid por mês.
Se você ainda está usando particionamento para gerenciar vários escritores, está perdendo uma característica chave do Liquid Clustering: concorrência a nível de linha.
Neste post, explicaremos como o Databricks oferece garantias de concorrência prontas para uso para clientes com modificações concorrentes em suas tabelas. A concorrência a nível de linha permite que você se concentre em extrair insights de negócios, eliminando a necessidade de projetar layouts de dados complexos ou coordenar cargas de trabalho, simplificando seu código e pipelines de dados.
A concorrência em nível de linha é ativada automaticamente quando você usa Liquid Clustering. Ele também é habilitado com vetores de exclusão ao usar o Databricks Runtime 14.2+. Se você tem modificações simultâneas que falham frequentemente com ConcurrentAppendException ou ConcurrentUpdateException, ative o Liquid Clustering ou vetores de exclusão na sua tabela hoje para ter detecção de conflitos em nível de linha e reduzir conflitos. Começar é simples:
Continue lendo para um mergulho profundo em como a concorrência em nível de linha lida automaticamente com gravações concorrentes que modificam o mesmo arquivo.
Abordagens tradicionais: difíceis de gerenciar e propensas a erros
Escritas simultâneas ocorrem quando vários processos, trabalhos ou usuários escrevem simultaneamente na mesma tabela. Esses são comuns em cenários como gravações contínuas de várias streams, diferentes pipelines ingerindo dados em uma tabela, ou operações em segundo plano como exclusões do GDPR. Gerenciar gravações simultâneas é ainda mais complicado ao gerenciar tarefas de manutenção - você tem que programar seu OPTIMIZE em torno das cargas de trabalho do negócio.
O Delta Lake garante a integridade dos dados durante essas operações usando controle de concorrência otimista, que fornece garantias transacionais entre gravações. Isso significa que se duas gravações entrarem em conflito, apenas uma terá sucesso, enquanto a outra falhará ao tentar confirmar.
Vamos considerar este exemplo: dois escritores de duas fontes diferentes, por exemplo, vendas nos EUA e no Reino Unido, tentam ao mesmo tempo mesclar na tabela global de números de vendas, que é particionada por date - um padrão de particionamento comum que vemos de clientes gerenciando grandes conjuntos de dados. Suponha que as vendas dos EUA sejam escritas na tabela com streamA, enquanto as vendas do Reino Unido são escritas com streamB.
Aqui, se o streamA preparar seus commits primeiro e o streamB tentar modificar a mesma partição, o Delta Lake rejeitará a escrita do streamB no momento do commit com uma exceção de modificação concorrente, mesmo quando os dois fluxos modificam linhas diferentes. Isso ocorre porque, com tabelas particionadas, os conflitos são detectados na granularidade das partições. Como resultado, as escritas do streamB são perdidas e muitos recursos computacionais são desperdiçados.
Para lidar com esses conflitos, os clientes podem redesenhar suas cargas de trabalho usando loops de repetição, que tentam a escrita do streamBnovamente. No entanto, a lógica de repetição pode levar a tempos de resposta de duração de trabalho aumentados e custos computacionais ao tentar repetidamente a mesma escrita, até que o commit seja bem-sucedido. Encontrar o equilíbrio certo é complicado -poucas tentativas arriscam falhas, enquanto muitas causam ineficiência e altos custos.
Outra abordagem é o particionamento mais detalhado, mas gerenciar partições de tabela mais detalhadas para isolar escritas também é difícil, especialmente quando várias equipes escrevem na mesma tabela. Escolher a chave de partição correta é desafiador, e a partição não funciona para todos os padrões de dados. Além disso, a partição é inflexível - você precisa reescrever toda a tabela ao alterar as chaves de partição para se adaptar a cargas de trabalho em evolução.
Neste exemplo, os clientes poderiam reescrever a tabela e particionar por date e country para que cada fluxo escreva em uma partição separada, mas isso pode causar problemas com arquivos pequenos. Isso acontece quando alguns países geram uma grande quantidade de dados de vendas enquanto outros produzem muito pouco - um padrão de dados muito comum.
Agrupamento Líquido evita todos esses problemas de pequenos arquivos, enquanto a concorrência em nível de linha oferece garantias de concorrência no nível da linha, que é ainda mais granular e mais flexível do que a partição. Vamos mergulhar para ver como a concorrência em nível de linha funciona!
Como a concorrência em nível de linha fornece resoluções automáticas de conflitos concorrentes sem intervenção manual
A concorrência em nível de linha é uma técnica inovadora no Databricks Runtime que detecta conflitos de escrita no nível da linha. Para tabelas agrupadas em Liquid, a capacidade resolve automaticamente conflitos entre operações de modificação como MERGE, UPDATE e DELETE desde que as operações não leiam ou modifiquem as mesmas linhas.
Além disso, para todas as tabelas com vetores de exclusão ativados - incluindo tabelas agrupadas em líquido, garante que operações de manutenção como OTIMIZAR e REORG não interferirão em outras operações de gravação. Você não precisa mais se preocupar em projetar para cargas de trabalho de gravação concorrentes, tornando suas cargas de trabalho no Databricks ainda mais simples.
Usando nosso exemplo, com concorrência em nível de linha, ambos os fluxos podem confirmar com sucesso suas modificações nos dados de vendas, desde que não estejam modificando a mesma linha - mesmo que as linhas estejam armazenadas no mesmo arquivo.
Por Trás das Cenas da Concorrência em Nível de Linha: Como Funciona
Como isso funciona? O Databricks Runtime reconcilia automaticamente as modificações concorrentes durante o tempo de commit. Ele usa vetores de exclusão (DV) e rastreamento de linha, recursos do Delta Lake, para acompanhar as alterações realizadas em cada transação e reconciliar modificações de forma eficiente.
Usando nosso exemplo, quando os novos dados de vendas são escritos na tabela, os novos dados são inseridos em um novo arquivo de dados, enquanto as linhas antigas são marcadas como excluídas usando vetores de exclusão sem a necessidade de reescrever o arquivo original. Vamos ampliar para o nível do arquivo, para ver como a concorrência em nível de linha funciona com vetores de exclusão.
Por exemplo, temos um arquivo A com quatro linhas, linha 0 até linha 3. A transação 1 (T1) do fluxoA tenta excluir linha 3 no arquivo A. Em vez de reescrever arquivo A, o Runtime do Databricks marca linha 3 como excluída no vetor de exclusão para o arquivo A, denotado como DV para A.
Agora a transação 2 (T2) entra a partir de streamB. Digamos que essa transação tente excluir linha 0. Com vetores de exclusão, Arquivo A permanece inalterado. Em vez disso, DV para A agora rastreia que linha 0 foi excluída. Sem concorrência em nível de linha, isso causaria um conflito com a transação 1 porque ambas estão tentando modificar o mesmo arquivo ou vetor de exclusão.
Com concorrência em nível de linha, a detecção de conflito no Runtime do Databricks identifica que as duas transações afetam linhas diferentes. Como não há conflito lógico, o Runtime do Databricks pode reconciliar as modificações concorrentes nos mesmos arquivos combinando os Vetores de Exclusão de ambas as transações.
Com todas essas inovações, o Databricks tem o único motor de lakehouse, em todos os formatos, que oferece concorrência a nível de linha no formato aberto Delta Lake. Outros motores adotam bloqueio em seus formatos proprietários, o que pode resultar em enfileiramento e operações de gravação lentas, ou você tem que confiar em métodos de concorrência baseados em partição complicados para suas gravações concorrentes.
No último ano, a concorrência em nível de linha ajudou mais de 6.500 clientes a resolver mais de 110B conflitos automaticamente, reduzindo conflitos de escrita em mais de 90% (os conflitos restantes são causados por tocar na mesma linha).
Comece hoje mesmo!
A Concorrência a Nível de Linha é ativada automaticamente com o Liquid Clustering no Databricks Runtime 13.3+ sem ajustes! No Databricks Runtime 14.2+, ele também é habilitado por padrão com todas as tabelas não particionadas que têm vetores de exclusão habilitados.
Se suas cargas de trabalho já estão usando o Liquid Clustering, você está pronto! Se não, adote o Liquid Clustering, ou ative vetores de exclusão em suas tabelas não particionadas para desbloquear os benefícios da concorrência a nível de linha.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Produto
June 12, 2024/11 min de leitura
