Baixando dezenas de milhões de imagens de contêiner diariamente do Registro de Artefatos otimizado para Serverless
Summary
- Os produtos de Dados e IA sem servidor da Databricks baixam dezenas de milhões de imagens de contêiner todos os dias. Construímos propositalmente o Registro de Artefatos otimizado para Serverless. Em comparação com os registros de código aberto, reduziu a latência de busca de imagem P99 em 90% e reduziu o uso de recursos de computação em 80%.
- O Registro de Artefatos escala perfeitamente para o tráfego Serverless intermitente. As principais otimizações incluem a substituição do banco de dados relacional de escalonamento vertical por armazenamento de objetos na nuvem, cache extensivo no caminho quente e redução de saltos de rede.
- Para confiabilidade, implementamos um design minimalista onde removemos 4 serviços remotos do sistema que minimiza os modos de falha. Também implementamos failover baseado em geografia para sobreviver a interrupções regionais do armazenamento de objetos na nuvem.
Introdução
Neste blog, compartilhamos a jornada de construção de um Registro de Artefatos otimizado para Serverless do zero. Os principais objetivos são garantir que a distribuição da imagem do contêiner escale de maneira contínua sob tráfego Serverless imprevisível e intenso, e permaneça disponível em cenários desafiadores, como falhas importantes de dependência.
Contêineres são o formato moderno de implantação nativa da nuvem que apresenta isolamento, portabilidade e um rico ecossistema de ferramentas. Os serviços internos do Databricks têm sido executados como contêineres desde 2017. Implantamos um projeto de código aberto maduro e rico em recursos como o registro de contêiner. Funcionou bem, pois os serviços geralmente eram implantados em um ritmo controlado.
Avançando para 2021, quando a Databricks começou a lançar os produtos DBSQL e ModelServing Serverless, esperava-se que milhões de VMs fossem provisionadas todos os dias, e cada VM puxaria mais de 10 imagens do registro de contêiner. Ao contrário de outros serviços internos, o tráfego de extração de imagem Serverless é impulsionado pelo uso do cliente e pode atingir um limite superior muito mais alto.
A Figura 1 é uma carga de tráfego de produção de 1 semana (por exemplo, clientes lançando novos data warehouses ou endpoints MLServing) que mostra que o tráfego de pico do Dataplane Serverless é mais de 100x comparado ao dos serviços internos.
Com base em nossos testes de estresse, concluímos que o registro de contêiner de código aberto não poderia atender aos requisitos do Serverless.
Desafios sem servidor
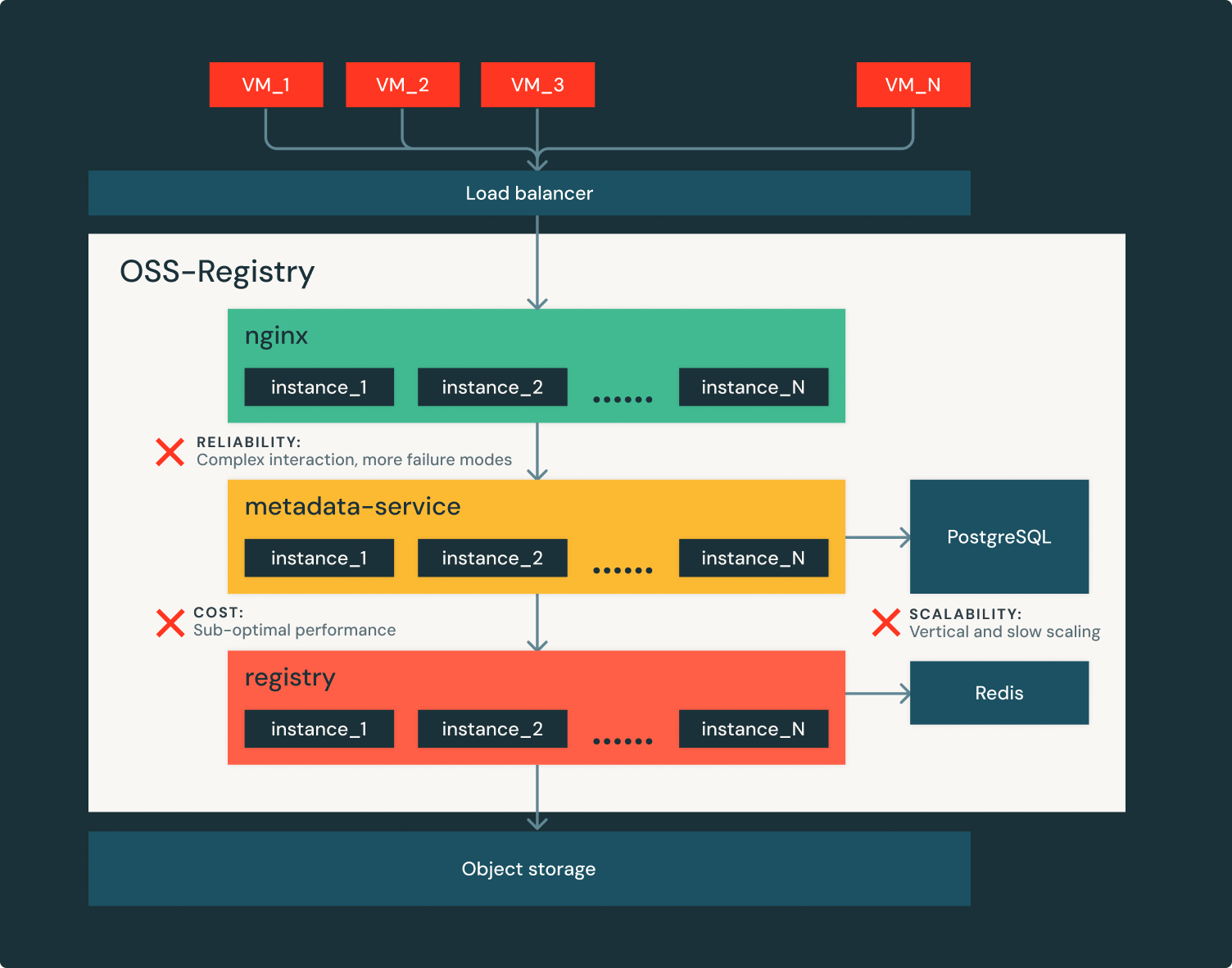
A Figura 2 mostra os principais desafios de atender cargas de trabalho Serverless com registro de contêiner de código aberto:
- Difícil acompanhar o crescimento da Databricks:
- Os metadados da imagem do contêiner são suportados por bancos de dados relacionais, que escalam verticalmente e lentamente.
- No pico de tráfego, milhares de instâncias de registro precisam ser provisionadas em alguns segundos, o que muitas vezes se torna um gargalo no caminho crítico da extração de imagem.
- Não é suficientemente confiável:
- O atendimento de solicitações é complexo na arquitetura baseada em OSS, que introduz mais modos de falha.
- Dependências como banco de dados relacional ou armazenamento de objetos na nuvem sendo interrompidos levam a uma interrupção total regional.
- Caro para operar: Os registros OSS não são otimizados para desempenho e tendem a ter alto uso de recursos (intensivo em CPU). Executá-los na escala da Databricks é proibitivamente caro.
E quanto aos registros de contêineres gerenciados na nuvem? Eles geralmente são mais escaláveis e oferecem SLA de disponibilidade. No entanto, diferentes serviços de provedores de nuvem têm diferentes cotas, limitações, confiabilidade, escalabilidade e características de desempenho. Como a Databricks opera em várias nuvens, descobrimos que a heterogeneidade das nuvens não atendia aos requisitos e era muito cara para operar.
A distribuição de imagem peer-to-peer (P2P) é outra abordagem comum para melhorar a escalabilidade, em uma camada de infraestrutura diferente. Principalmente reduz a carga para os metadados do registro, mas ainda está sujeito aos riscos de confiabilidade mencionados anteriormente. Mais tarde, também introduzimos a camada P2P para reduzir a taxa de transferência de saída do armazenamento na nuvem. Na Databricks, acreditamos que cada camada precisa ser otimizada para fornecer confiabilidade para toda a pilha.
Apresentando o Artifact Registry
Concluímos que era necessário construir um registro otimizado para Serverless para atender aos requisitos e garantir que continuamos à frente do rápido crescimento do Databricks. Portanto, construímos o Registro de Artefatos - um serviço de registro de contêiner multicloud desenvolvido internamente. O Registro de Artefatos é projetado com os seguintes princípios:
- Tudo escala horizontalmente:
- Removemos o banco de dados relacional (PostgreSQL); em vez disso, os metadados foram persistidos no armazenamento de objetos na nuvem (uma dependência existente para armazenamento de manifestos e camadas de imagens). Os armazenamentos de objetos em nuvem são muito mais escaláveis e foram bem abstraídos entre as nuvens.
- Removemos a instância de cache (Redis) e a substituímos por um cache simples em memória.
- Escalando para cima/baixo em segundos: adicionamos extenso cache para solicitações de manifestos de imagem e blob para reduzir a ocorrência do caminho de código lento (registro). Como resultado, apenas algumas instâncias (provisionadas em alguns segundos) precisam ser adicionadas em vez de centenas.
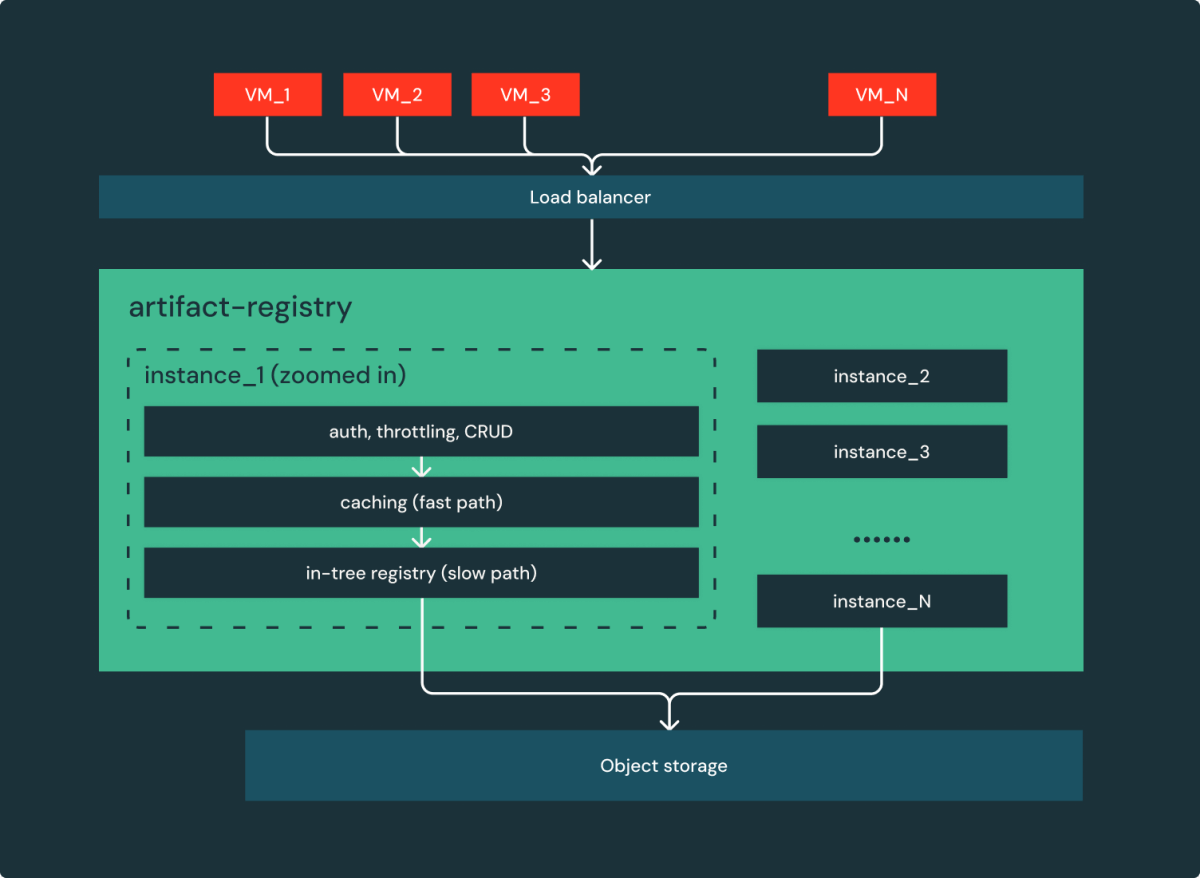
- Simples é confiável: consolidamos 3 micro-serviços de código aberto (nginx, serviço de metadados e registro) em um único serviço, registro de artefatos. Isso reduz 2 saltos extras de rede e melhora o desempenho/confiabilidade.
Como mostrado na Figura 3, transformamos essencialmente o sistema original composto por 5 serviços em um simples serviço web: um monte de instâncias sem estado atrás de um balanceador de carga atendendo solicitações!
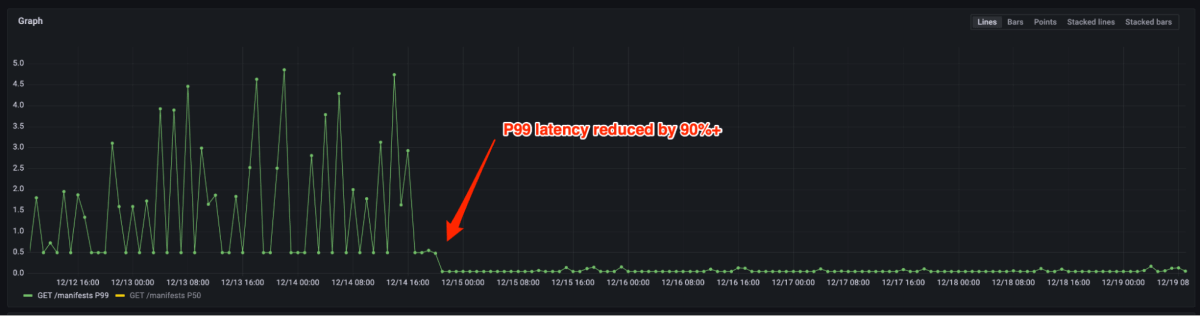
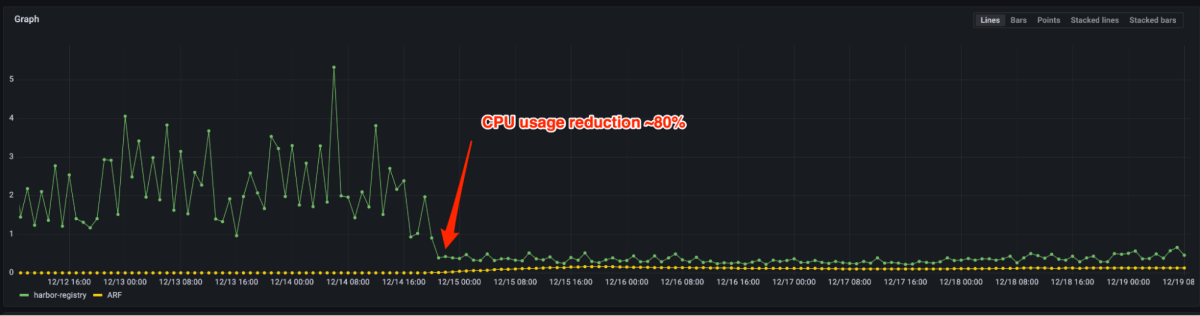
As Figuras 4 e 5 mostram que a latência P99 reduziu em mais de 90% e o uso de CPU reduziu em 80% após a migração do registro de código aberto para o Registro de Artefatos. Agora só precisamos provisionar algumas instâncias para a mesma carga vs. milhares anteriormente. Na verdade, lidar com o tráfego de pico de produção não requer escala na maioria dos casos. No caso de o auto-escalamento ser acionado, ele pode ser feito em alguns segundos.
A principal decisão de design é substituir completamente os bancos de dados relacionais por armazenamento de objetos na nuvem para metadados de imagem. Bancos de dados relacionais são ideais para consistência e capacidade de consulta enriquecida, mas têm limitações em termos de escalabilidade e confiabilidade. Por exemplo, cada solicitação de extração de imagem exigia autenticação/autorização, que era atendida pelo PostgreSQL na implementação de código aberto. Os picos de tráfego regularmente causavam soluços de desempenho. A consulta de pesquisa usada pela autenticação pode ser facilmente substituída por uma operação GET de um armazenamento de Chave/Valor mais escalável. Também fizemos trocas cuidadosas entre conveniência e confiabilidade. Por exemplo, usando um banco de dados relacional, é fácil agregar a contagem de imagens, o tamanho total agrupando por diferentes dimensões. No entanto, suportar tais recursos é não trivial no armazenamento de objetos. Em favor da confiabilidade e escalabilidade, decidimos que o Registro de Artefatos não suportaria tais estatísticas.
Sobrevivendo a interrupções do armazenamento de objetos na nuvem
Com a confiabilidade do serviço significativamente melhorada após eliminar as dependências do banco de dados relacional, cache remoto e microserviços internos, ainda há um modo de falha que ocasionalmente acontece: interrupções do armazenamento de objetos na nuvem. Os armazenamentos de objetos na nuvem são geralmente muito confiáveis e escaláveis; no entanto, quando estão indisponíveis (às vezes por horas), isso potencialmente causa interrupções regionais. A Databricks mantém um alto padrão de confiabilidade para minimizar o impacto das interrupções da nuvem subjacente e continuar a atender nossos clientes.
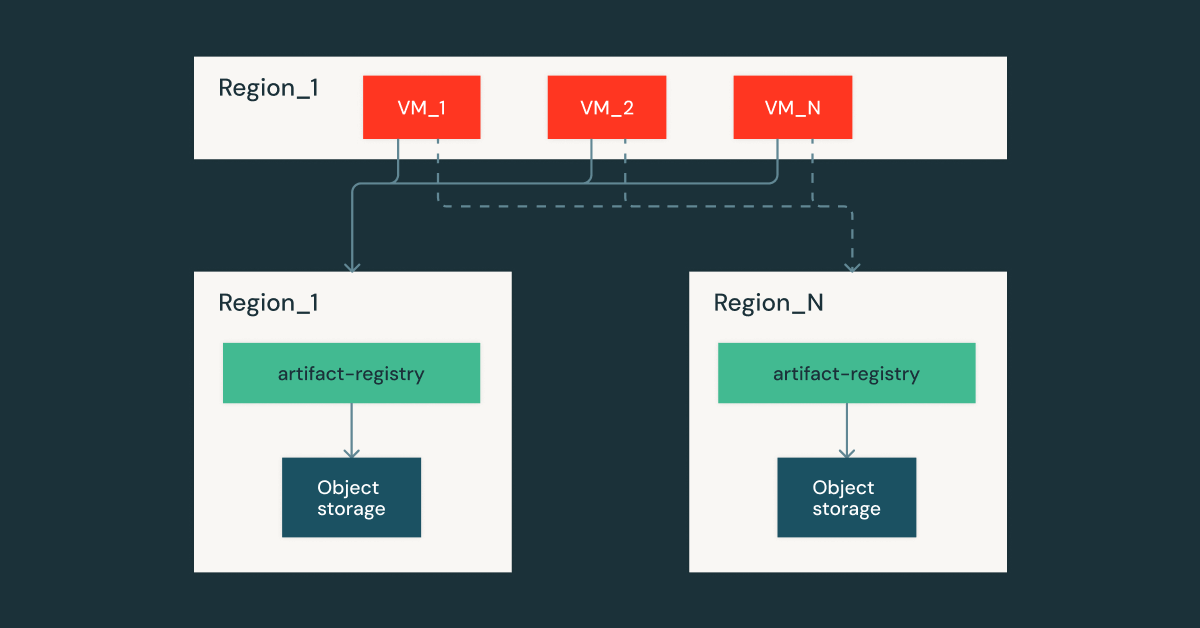
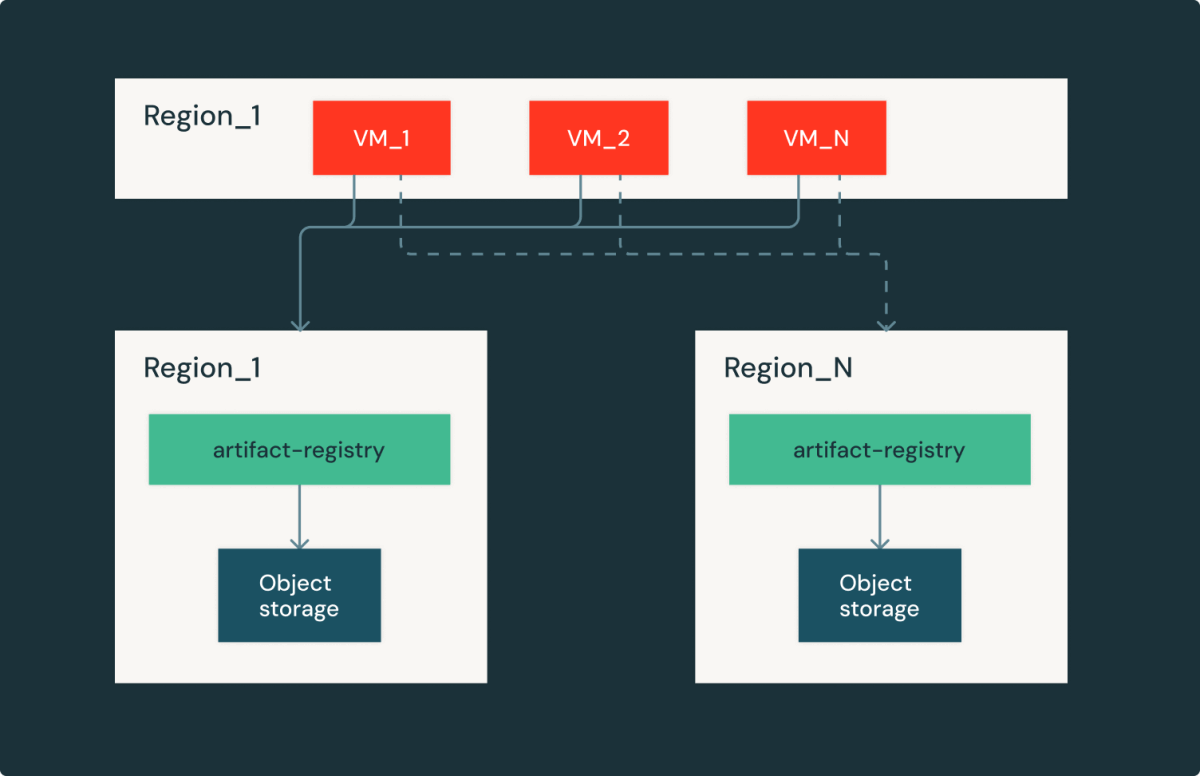
O Artifact Registry é um serviço regional, o que significa que cada nuvem/região possui uma réplica idêntica dentro da região. Esta configuração nos dá a capacidade de falhar para diferentes regiões com o compromisso na latência de download da imagem e no custo de saída. Ao cuidadosamente curar latência e capacidade, conseguimos nos recuperar rapidamente das interrupções do provedor de nuvem e continuar atendendo aos clientes da Databricks.
Conclusão
Neste post do blog, compartilhamos nossa jornada de construção do registro de contêineres Databricks, desde o atendimento ao tráfego interno de baixa rotatividade até as cargas de trabalho Serverless voltadas para o cliente. Nós construímos propositalmente o Registro de Artefatos otimizado para Serverless. Em comparação com o registro de código aberto, ele entregou 90% de redução de latência P99 e 80% de uso de recursos. Além disso, projetamos o sistema para tolerar interrupções regionais do provedor de nuvem, melhorando ainda mais a confiabilidade. Hoje, o Artifact Registry continua a ser uma base sólida que torna a confiabilidade, escalabilidade e eficiência contínuas em meio ao rápido crescimento do Serverless no Databricks.
Agradecimento
Construir uma infraestrutura Serverless confiável e escalável é um esforço de equipe de nossos principais contribuidores: Robert Landlord, Tian Ouyang, Jin Dong e Siddharth Gupta. O blog também é um trabalho em equipe - agradecemos as revisões perspicazes fornecidas por Xinyang Ge e Rohit Jnagal.
(This blog post has been translated using AI-powered tools) Original Post

Data Engineering
November 26, 2024/9 min de leitura
Booting Databricks VMs 7x Faster for Serverless Compute
Nunca perca uma postagem da Databricks
O que vem a seguir?
Data Engineering
September 12, 2025/11 min de leitura
Databricks em Databricks: Escalando a Confiabilidade de Banco de Dados

Anúncios
September 25, 2025/6 min de leitura