Apresentando a Avaliação Avançada de Agentes
Personalização Mais Fácil e Melhor Colaboração com Stakeholders de Negócios
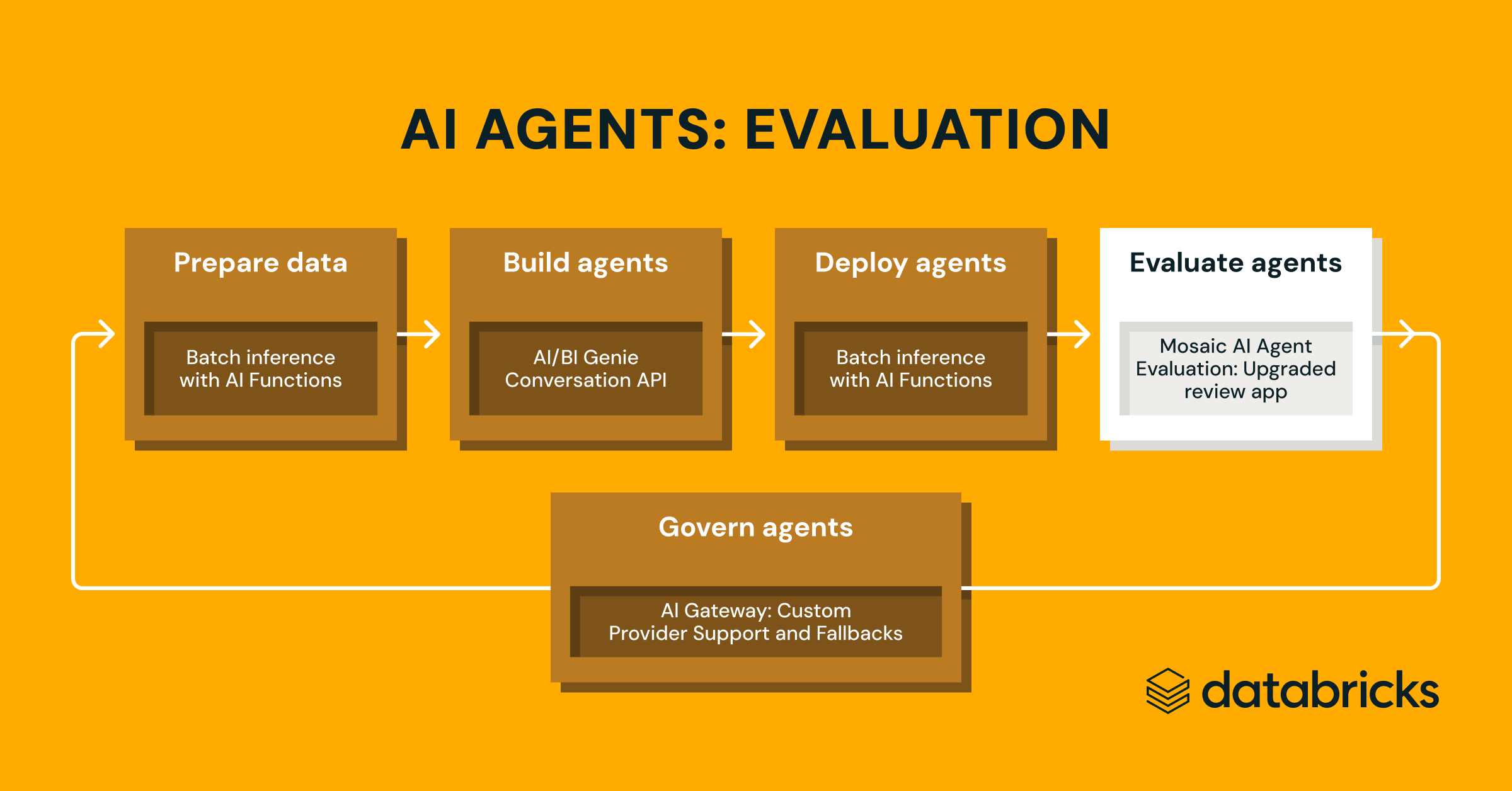
Summary
- Do Piloto à Produção – Simplifique a adoção do GenAI com avaliações automatizadas, feedback de especialistas e caminhos claros de iteração em ambas as fases.
- Avaliação GenAI Personalizável – Defina métricas personalizadas, use o novo Juiz de IA de Diretrizes, e avalie qualquer caso de uso com esquemas de entrada/saída flexíveis.
- Colaboração de Especialistas Sem Interrupções – O aplicativo de revisão atualizado simplifica a coleta de feedback e a gestão do conjunto de dados de avaliação.
No início desta semana, anunciamos novas capacidades de desenvolvimento de agentes no Databricks. Após conversar com centenas de clientes, notamos dois desafios comuns para avançar além das fases piloto. Primeiro, os clientes não têm confiança no desempenho de produção de seus modelos. Segundo, os clientes não têm um caminho claro para iterar e melhorar. Juntos, esses fatores geralmente levam a projetos estagnados ou processos ineficientes, onde as equipes se desdobram para encontrar especialistas no assunto para avaliar manualmente as saídas do modelo.
Hoje, estamos enfrentando esses desafios expandindo a Avaliação do Agente Mosaic AI com novas capacidades de Visualização Pública. Esses aprimoramentos ajudam as equipes a entender melhor e aprimorar suas aplicações GenAI através de avaliações automatizadas personalizáveis e feedback simplificado dos stakeholders do negócio.
- Personalize avaliações automatizadas: Use juízes de IA de Diretrizes para avaliar aplicativos GenAI com regras em inglês simples, e defina métricas críticas para o negócio com avaliações personalizadas em Python.
- Colabore com especialistas do domínio: Aproveite o Review App e o novo SDK de conjunto de dados de avaliação para coletar feedback de especialistas do domínio, rotular rastros do aplicativo GenAI e refinar conjuntos de dados de avaliação—alimentados por tabelas Delta e governança do Catálogo Unity.
Para ver essas capacidades em ação, confira nosso notebook de exemplo.
Personalize a avaliação do GenAI para as necessidades do seu negócio
As aplicações GenAI e sistemas de Agentes apresentam muitas formas - desde a sua arquitetura subjacente usando bancos de dados vetoriais e ferramentas, até seus métodos de implantação, seja em tempo real ou em lote. Na Databricks, aprendemos que tarefas específicas de domínio bem-sucedidas exigem que os agentes também utilizem efetivamente os dados da empresa. Esta gama exige uma abordagem de avaliação igualmente flexível.
Hoje, estamos introduzindo atualizações na Avaliação de Agentes Mosaic AI para torná-la altamente personalizável, projetada para ajudar as equipes a medir o desempenho em qualquer aplicação específica de domínio para qualquer tipo de aplicação GenAI ou sistema de Agentes.

Juiz de Diretrizes AI: use linguagem natural para verificar se os aplicativos GenAI seguem as diretrizes
Expandindo nosso catálogo de juízes LLM integrados e ajustados pela pesquisa que oferecem precisão de primeira classe, estamos introduzindo o Juiz de IA de Diretrizes (Pré-visualização Pública), que ajuda os desenvolvedores a usar listas de verificação ou rubricas em linguagem simples em sua avaliação. Às vezes referido como notas de classificação, as diretrizes são semelhantes à forma como os professores definem critérios (por exemplo, “O ensaio deve ter cinco parágrafos”, “Cada parágrafo deve ter uma frase tópico”, “O último parágrafo de cada frase deve resumir todos os pontos feitos no parágrafo”, …).
Como funciona: Forneça diretrizes ao configurar a Avaliação de Agentes, que serão automaticamente avaliadas para cada solicitação.
Exemplos de diretrizes:
- A resposta deve ser profissional.
- Quando o usuário pede para comparar dois produtos, a resposta deve exibir uma tabela.
Por que isso importa: As diretrizes melhoram a transparência da avaliação e a confiança com os stakeholders do negócio por meio de rubricas de classificação estruturadas e fáceis de entender, resultando em uma pontuação consistente e transparente das respostas do seu aplicativo.

Veja nossa documentação para mais informações sobre como as Diretrizes aprimoram as avaliações
Métricas Personalizadas: defina métricas em Python, adaptadas às necessidades do seu negócio
Métricas personalizadas permitem que você defina critérios de avaliação personalizados para sua aplicação de IA além das métricas integradas e juízes LLM. Isso lhe dá controle total para avaliar programaticamente entradas, saídas e rastros da maneira que as exigências do seu negócio determinam. Por exemplo, você pode escrever uma métrica personalizada para verificar se a consulta de um agente gerador de SQL realmente é executada com sucesso em um banco de dados de teste ou uma métrica para personalizar como o juiz de solidez integrado é usado para medir a consistência entre uma resposta e um documento fornecido.
Como funciona: Escreva uma função Python, decore-a com @metric, e passe-a para mlflow.evaluate(extra_metrics=[..]). A função pode acessar informações ricas sobre cada registro, incluindo a solicitação, resposta, o rastreamento completo do MLflow, ferramentas disponíveis e chamadas que são pós-processadas a partir do rastreamento, etc.
Por que isso importa: Essa flexibilidade permite que você defina regras específicas para o seu negócio ou verificações avançadas que se tornam métricas de primeira classe na avaliação automatizada.
Confira nossa documentação para informações sobre como definir métricas personalizadas.
Esquemas de Entrada/Saída Arbitrários
Os fluxos de trabalho do GenAI no mundo real não se limitam a aplicações de chat. Você pode ter um agente de processamento em lote que recebe documentos e retorna um JSON com informações chave, ou usar um LLMI para preencher um modelo. A Avaliação de Agentes agora suporta a avaliação de esquemas de entrada/saída arbitrários.
Como funciona: Passe qualquer Dicionário serializável (por exemplo, dict[str, Any]) como entrada para mlflow.evaluate().
Por que isso importa: Agora você pode avaliar qualquer aplicação GenAI com a Avaliação de Agentes.
Saiba mais sobre esquemas arbitrários em nossa documentação.
Colabore com especialistas de domínio para coletar rótulos
A avaliação automática sozinha muitas vezes não é suficiente para entregar aplicativos GenAI de alta qualidade. Os desenvolvedores GenAI, que muitas vezes não são os especialistas no caso de uso que estão construindo, precisam de uma maneira de colaborar com as partes interessadas do negócio para melhorar seu sistema GenAI.
Review App: interface de rotulagem personalizada
Atualizamos o Aplicativo de Revisão de Avaliação de Agente, tornando fácil coletar feedback personalizado de especialistas no domínio para a construção de um conjunto de dados de avaliação ou coleta de feedback. O Aplicativo de Revisão integra-se com o ecossistema Databricks MLFlow GenAI, simplificando a colaboração entre desenvolvedor ⇔ especialista com uma interface de usuário simples, porém totalmente personalizável.
O aplicativo de revisão agora permite que você:
- Coletar feedback ou rótulos esperados: Coletar feedback de aprovação ou reprovação sobre gerações individuais do seu aplicativo GenAI, ou coletar rótulos esperados para criar um conjunto de dados de avaliação em uma única interface.
- Enviar Qualquer Rastro para Rotulação: Encaminhe rastros do desenvolvimento, pré-produção ou produção para rotulação por especialistas do domínio.
- Personalizar Rotulagem: Personalize as perguntas apresentadas aos especialistas em uma Sessão de Rotulagem e defina as etiquetas e descrições coletadas para garantir que os dados estejam alinhados com o seu caso de uso específico do domínio.
Exemplo: Um desenvolvedor pode descobrir rastros potencialmente problemáticos em um aplicativo GenAI em produção e enviar esses rastros para revisão de seu especialista no domínio. O especialista no domínio receberia um link e revisaria o chat de várias etapas, rotulando onde a resposta do assistente era irrelevante e fornecendo respostas esperadas para criar um conjunto de dados de avaliação.
Por que isso importa: A colaboração com rótulos de especialistas do domínio permite que os desenvolvedores do aplicativo GenAI entreguem aplicações de maior qualidade aos seus usuários, dando aos stakeholders de negócios muito mais confiança de que seu aplicativo GenAI implantado está entregando valor aos seus clientes.
"Na Bridgestone, estamos usando dados para impulsionar nossos casos de uso GenAI, e a Avaliação de Agentes Mosaic AI tem sido fundamental para garantir que nossas iniciativas GenAI sejam precisas e seguras. Com seu aplicativo de revisão e ferramentas de conjunto de dados de avaliação, conseguimos iterar mais rápido, melhorar a qualidade e ganhar a confiança do negócio.” — Coy McNew, Arquiteto Chefe de IA, Bridgestone

Confira nossa documentação para aprender mais sobre como usar o aplicativo de revisão atualizado.
Conjuntos de Dados de Avaliação: Suítes de Teste para GenAI
Conjuntos de dados de avaliação surgiram como o equivalente a testes de "unidade" e "integração" para GenAI, ajudando os desenvolvedores a validar a qualidade e o desempenho de suas aplicações GenAI antes de liberá-las para produção.
Avaliação do Agente Conjunto de Dados de Avaliação, exposto como uma Tabela Delta gerenciada no Catálogo Unity, permite que você gerencie o ciclo de vida dos seus dados de avaliação, compartilhe-os com outros interessados e governe o acesso. Com Conjuntos de Dados de Avaliação, você pode sincronizar facilmente as etiquetas do Review App para usar como parte do seu fluxo de trabalho de avaliação.
Como funciona: Use nossos SDKs para criar um conjunto de dados de avaliação, depois use nossos SDKs para adicionar rastros de seus logs de produção, adicionar rótulos de especialista no domínio a partir do Aplicativo de Revisão, ou adicione dados de avaliação sintéticos.
Por que isso é importante: Um conjunto de dados de avaliação permite que você corrija iterativamente problemas identificados na produção e garanta que não haja regressões ao enviar novas versões, dando aos stakeholders do negócio a confiança de que seu aplicativo funciona nos casos de teste mais importantes.
"O aplicativo de revisão da Avaliação de Agentes Mosaic AI tornou significativamente mais fácil criar e gerenciar conjuntos de dados de avaliação, permitindo que nossas equipes se concentrem em refinar a qualidade do agente em vez de lidar com dados. Com sua geração de dados sintéticos integrada, podemos testar e iterar rapidamente sem esperar pela rotulagem manual - acelerando nosso tempo de lançamento em produção em 50%. Isso otimizou nosso fluxo de trabalho e melhorou a precisão de nossos sistemas de IA, especialmente em nossos agentes de IA construídos para auxiliar nosso Centro de Atendimento ao Cliente.” — Chris Nishnick, Diretor de Inteligência Artificial na Lippert
Passo a passo completo (com um caderno de amostra) de como usar essas capacidades para avaliar e melhorar um aplicativo GenAI
Vamos agora ver como essas capacidades podem ajudar um desenvolvedor a melhorar a qualidade de um aplicativo GenAI que foi lançado para testadores beta ou usuários finais em produção.
> Para percorrer esse processo você mesmo, você pode importar este blog como um notebook de nossa documentação.
O exemplo abaixo usará um agente de chamada de ferramenta simples que foi implantado para ajudar a responder perguntas sobre Databricks. Este agente possui algumas ferramentas e fontes de dados simples. Não nos concentraremos em COMO este agente foi construído, mas para um passeio detalhado de como construir este agente, consulte nosso fluxo de trabalho do desenvolvedor de aplicativos de IA Generativa que o guia pelo processo de ponta a ponta de desenvolver um aplicativo GenAI [AWS | Azure].
Instrumente seu agente com MLflow
Primeiro, adicionaremos o Rastreamento MLflow e o configuraremos para registrar rastreamentos no Databricks. Se o seu aplicativo foi implantado com o Agent Framework, isso acontece automaticamente, então este passo é necessário apenas se o seu aplicativo for implantado fora do Databricks. No nosso caso, como estamos usando LangGraph, podemos nos beneficiar da capacidade de auto-registro do MLFlow:
O MLFlow suporta autologging da maioria das bibliotecas GenAI populares, incluindo LangChain, LangGraph, OpenAI e muitas outras. Se o seu aplicativo GenAI não está usando nenhuma das bibliotecas GenAI suportadas , você pode usar Rastreamento Manual:
Revisar logs de produção
Agora, vamos revisar alguns logs de produção sobre o seu agente. Se o seu agente foi implantado com o Agent Framework, você pode consultar a tabela de logs de solicitação de carga útil e filtrar algumas solicitações por databricks_request_id:
Podemos inspecionar o Rastreamento MLflow para cada log de produção:

Crie um conjunto de dados de avaliação a partir desses logs
Definir métricas para avaliar o agente versus nossos requisitos de negócios
Agora, faremos uma avaliação usando uma combinação de juízes integrados da Avaliação de Agentes e métricas personalizadas:
- Usando Diretrizes:
- O agente se recusa corretamente a responder perguntas relacionadas a preços?
- A resposta do agente é relevante para o usuário?
- Usando Métricas Personalizadas:
- As ferramentas selecionadas pelo agente são lógicas, dado o pedido do usuário?
- A resposta do agente está fundamentada nas saídas das ferramentas e não está alucinando?
- Qual �é o custo e a latência do agente?
Para a brevidade deste post de blog, incluímos apenas um subconjunto das métricas acima, mas você pode ver a definição completa no caderno de demonstração
Execute a avaliação
Agora, podemos usar a integração da Avaliação do Agente com o MLflow para calcular essas métricas contra nosso conjunto de avaliação.
Olhando para esses resultados, vemos alguns problemas:
- O agente chamou a ferramenta de multiplicação quando a consulta exigia soma.
- A questão sobre spark não está representada em nosso conjunto de dados, o que levou a uma resposta irrelevante.
- O LLM responde a perguntas sobre preços, o que viola nossas diretrizes.

Corrija o problema de qualidade
Para corrigir os dois problemas, podemos tentar:
- Atualizando o prompt do sistema para encorajar o LLM a não responder a perguntas sobre preços
- Adicionando uma nova ferramenta para adição
- Adicionando um documento sobre a última versão do spark.
Em seguida, reexecutamos a avaliação para confirmar que resolveu nossos problemas:

Verifique a correção com as partes interessadas antes de implantar novamente na produção
Agora que resolvemos o problema, vamos usar o Aplicativo de Revisão para liberar as perguntas que corrigimos para as partes interessadas para verificar se são de alta qualidade. Vamos personalizar o App de Revisão para coletar ambos os feedbacks, e quaisquer diretrizes adicionais que nossos especialistas de domínio identifiquem durante a revisão
Podemos compartilhar o Review App com qualquer pessoa em nosso SSO da empresa, mesmo que eles não tenham acesso ao espaço de trabalho Databricks.

Finalmente, podemos sincronizar de volta os rótulos que coletamos para nosso conjunto de dados de avaliação e reexecutar a avaliação usando as diretrizes adicionais e o feedback que o especialista de domínio forneceu.
Uma vez que isso é verificado, podemos implantar novamente nosso aplicativo!
O que vem a seguir?
Já estamos trabalhando na nossa próxima geração de capacidades.
Primeiro, através de uma integração com a Avaliação de Agentes, Monitoramento Lakehouse para GenAI, suportará o monitoramento de produção do desempenho do aplicativo GenAI (latência, volume de solicitações, erros) e métricas de qualidade (precisão, correção, conformidade). Usando o Monitoramento Lakehouse para GenAI, os desenvolvedores podem:
- Acompanhe a qualidade e o desempenho operacional (latência, volume de solicitações, erros, etc.).
- Execute avaliações baseadas em LLM no tráfego de produção para detectar deriva ou regressões
- Aprofundar-se em solicitações individuais para depurar e melhorar as respostas do agente.
- Transforme logs do mundo real em conjuntos de avaliação para impulsionar melhorias contínuas.
Segundo, Rastreamento MLflow [Código Aberto | Databricks], construído sobre o Open Telemetry padrão da indústria para observabilidade, suportará a coleta de dados de observabilidade (rastreamento) de qualquer aplicativo GenAI, mesmo que seja implantado fora do Databricks. Com algumas linhas de código copiado/colado, você pode instrumentar qualquer aplicativo GenAI ou agente e aterrissar dados de rastreamento em seu Lakehouse.
Se você quiser experimentar essas capacidades, por favor, entre em contato com sua equipe de conta.

Começar
Seja você está monitorando agentes de IA em produção, personalizando a avaliação, ou otimizando a colaboração com os stakeholders do negócio, essas ferramentas podem ajudá-lo a construir aplicações GenAI mais confiáveis e de alta qualidade.
Para começar, confira a documentação:
- Experimente o caderno de demonstração mencionado acima
- Avaliação de Agente de IA Mosaic Aplicativo de Revisão
- Rastreamento MLflow
- Avaliação de Agente AI Mosaic Métricas Personalizadas
- Avaliação do Agente AI Mosaic Guia do juiz
Assista ao vídeo de demonstração.
E confira o Guia Compacto para Agentes de IA para aprender como maximizar seu ROI do GenAI.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Produto
June 12, 2024/11 min de leitura
Apresentando o AI/BI: analítica inteligente para dados do mundo real

IA generativa
January 7, 2025/8 min de leitura