
Estratégia Data + AI
As empresas estão pressionando para democratizar os dados e a IA
Todas as empresas querem se beneficiar dos efeitos transformadores das suas iniciativas de GenAI. Elas também querem colocar o poder da inteligência de dados nas mãos de todos os funcionários. No entanto, como as informações estão agrupadas em silos e o gerenciamento de dados está espalhado por muitas ferramentas, as equipes muitas vezes têm dificuldade para colocar esses projetos em prática.
A questão urgente entre os líderes empresariais neste momento é: Qual é a melhor e mais rápida maneira de democratizar a IA?
O relatório State of Data + AI fornece um retrato de como as organizações estão priorizando dados e iniciativas de IA. Ao analisar dados de uso anônimos de 10.000 clientes que já usam a Databricks Data Intelligence Platform hoje, incluindo mais de 300 empresas da Fortune 500, somos capazes de fornecer insights incomparáveis sobre o status dos esforços de adoção de GenAI das organizações e das ferramentas que as ajudam nesse processo.
Descubra como as empresas mais inovadoras estão obtendo sucesso com machine learning, adotando a GenAI e respondendo às crescentes necessidades de governança. Além disso, saiba como sua própria empresa pode desenvolver uma estratégia de dados adequada à era emergente da IA corporativa.
Veja um resumo do que descobrimos:
A IA está em produção
11 vezes mais modelos de IA foram colocados em produção
As empresas vêm experimentando o machine learning (ML), um componente-chave da IA, há anos. Muitas vezes, enfrentam grandes obstáculos quando se trata de transferir experiências controladas de ML para aplicações de produção reais, sejam silos de dados, processos de implementação complexos ou governação. Mas agora estamos vendo sinais de sucesso crescente. Entre as empresas, 1.018% mais modelos foram introduzidos em produção este ano do que no ano anterior. Essa foi a primeira vez em nossa pesquisa que o crescimento dos modelos registrados excedeu o dos experimentos registrados (que, por sua, vez aumentou 134%).
Mas, quando se trata de ML, cada setor tem requisitos e objetivos diferentes. Analisamos seis setores principais e observamos a proporção entre modelos log e registrados para entender melhor essas tendências. O que nós descobrimos? Que nas nossas três indústrias mais eficientes, 25% dos modelos entraram em produção.
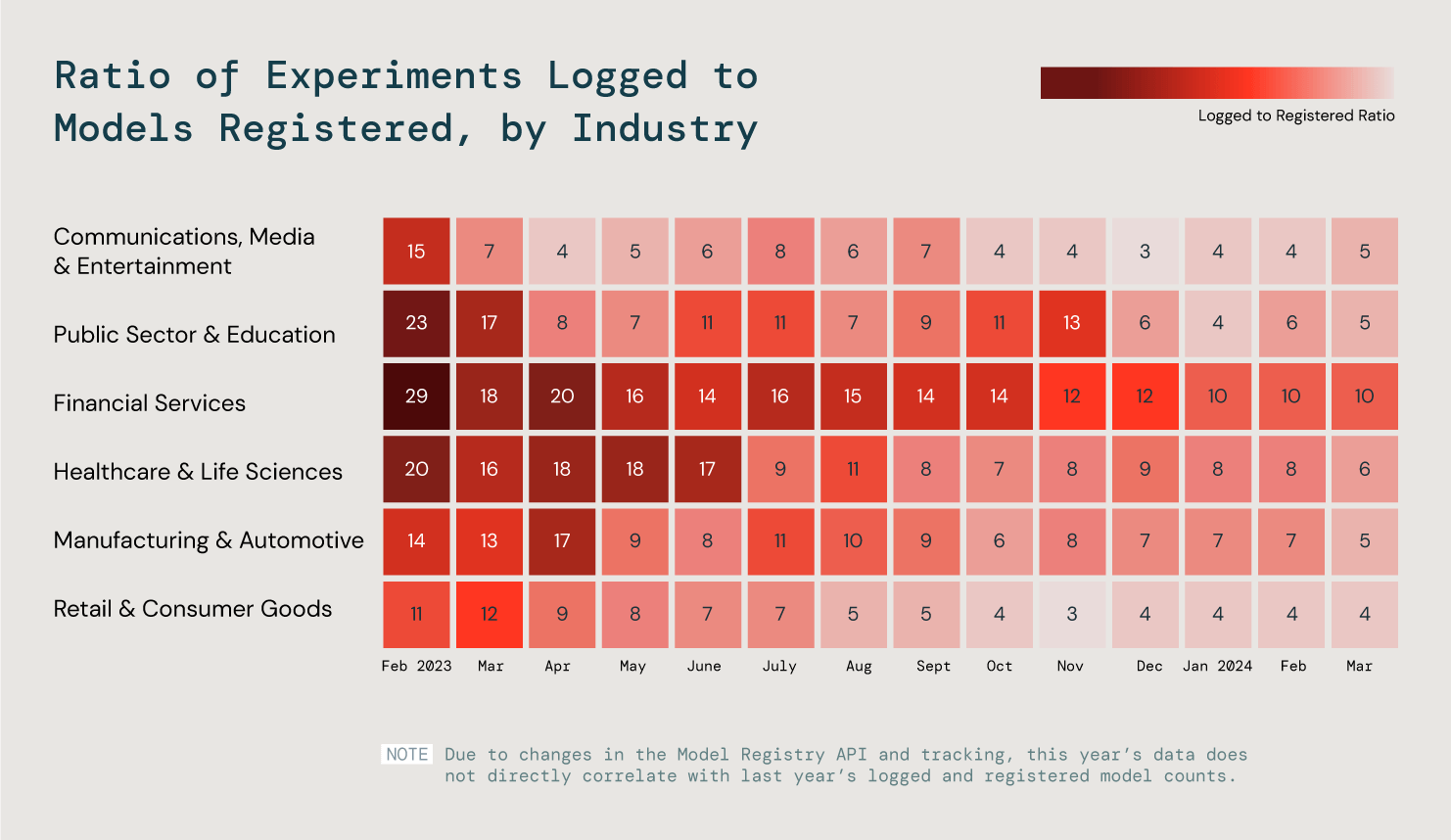
Analisamos a proporção de logs para modelos registrados em todos os clientes para avaliar o progresso da produção do ML.
É na produção que o verdadeiro valor da IA entra em jogo, seja um produto para suas equipes internas ou para seus clientes. Prevemos que o sucesso crescente em ML abrirá caminho para um sucesso ainda maior no desenvolvimento de aplicações GenAI de nível de produção.
Personalização do LLM
O uso de bancos de dados vetoriais aumentou 377%
As empresas estão se tornando cada vez mais maduras em direção à GenAI. Como resultado, procuram cada vez mais adaptar os LLMs existentes às suas necessidades muito específicas, usando os próprios dados privados.
A geração aumentada de recuperação (RAG) é um mecanismo importante para que as organizações obtenham melhor desempenho ao implantar LLMs de código aberto e proprietários. O RAG usa um banco de dados vetorial para treinar os modelos subjacentes com dados privados e, assim, gerar resultados mais precisos que são hiper-relevantes para os processos específicos da empresa.
As empresas estão implementando agressivamente esses ajustes. Como resultado, o uso de bases de dados vetoriais aumentou 377% no ano passado.
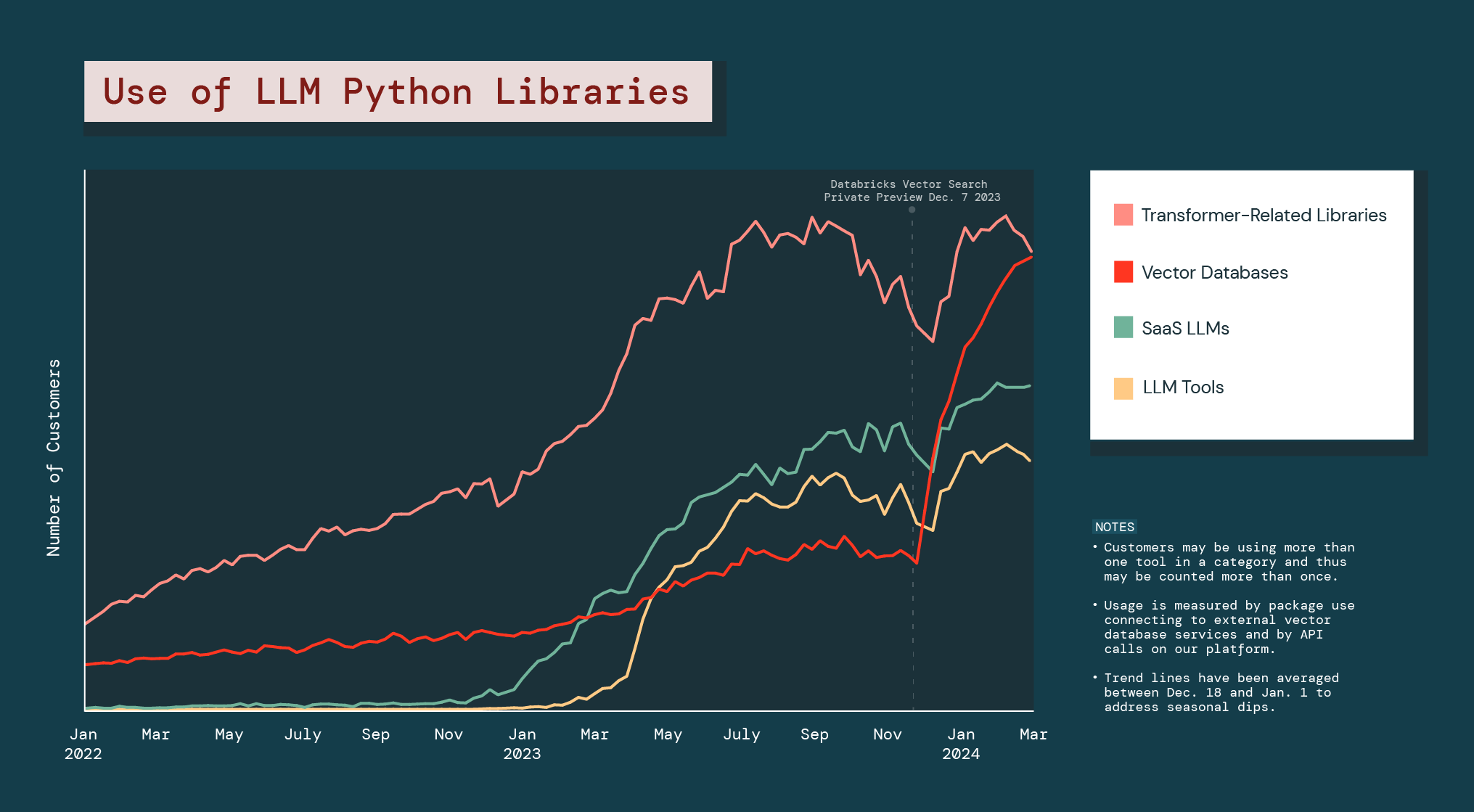
Desde o início da versão de pré-lançamento público do Databricks Vector Search, toda a categoria de banco de dados vetorial cresceu 186%, tornando-o significativamente mais forte do que todas as outras bibliotecas LLM Python.
A explosão dos bancos de dados vetoriais mostra que as empresas estão em busca de alternativas de GenAI que possam ajudá-las a resolver problemas ou oferecer oportunidades específicas para seus negócios. Também sugere que as empresas provavelmente contarão com uma combinação de diferentes modelos GenAI nas suas operações no futuro.
LLMs de código aberto
As empresas preferem modelos pequenos
Uma das maiores vantagens dos LLMs de código aberto é a capacidade de adaptá-los a casos de uso específicos, especialmente em um ambiente corporativo. Na prática, os clientes experimentam com frequência muitos modelos e famílias de modelos. Analisamos o uso de modelos de código aberto de Meta Llama e Mistral, os dois maiores fornecedores.
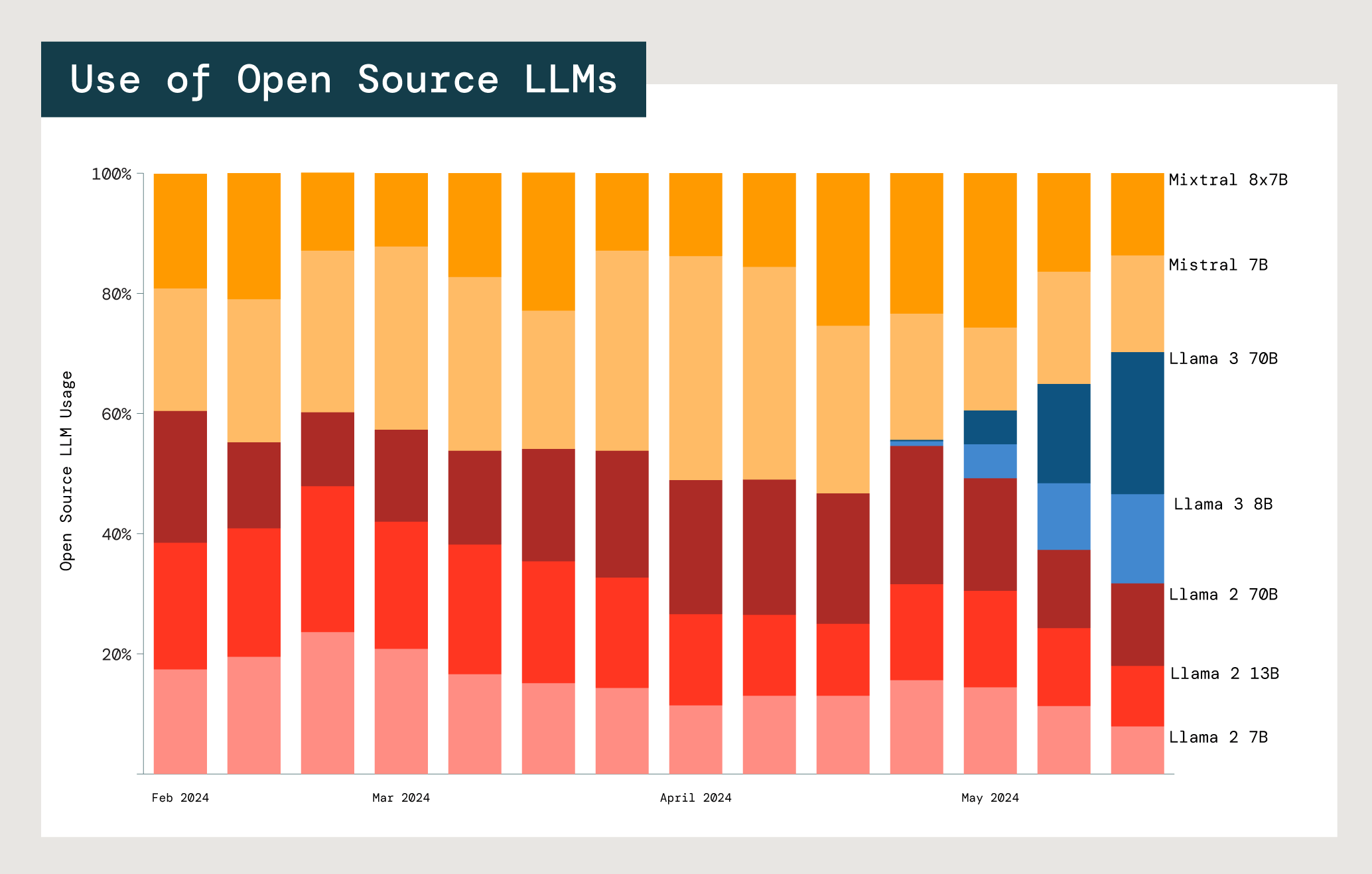
Uso relativo de modelos Mistral e Meta Llama de código aberto em APIs de modelo básico da Databricks.
Com cada modelo, há uma compensação entre custo, latência e desempenho. O uso dos dois menores modelos Meta Llama 2 (7 e 13 bilhões de parâmetros, respectivamente) é significativamente maior do que o do maior modelo, Meta Llama 2 (70 bilhões). Tanto para os usuários do Llama quanto do Mistral, 77% escolhem modelos que tem no máximo 13 bilhões de parâmetros. Esse fato sugere que as empresas ponderam os custos e os benefícios do tamanho do modelo ao selecionar o modelo apropriado para um caso de uso específico.
