Grandes modelos de linguagem (LLMs)
O que são grandes modelos de linguagem (LLMs)?
Modelos de linguagem são um tipo de AI generativa (GenAI) que usam o processamento de linguagem natural (NLP) para entender e gerar a linguagem humana. Grandes modelos de linguagem (LLMs) são os mais poderosos deles. Os LLMs são treinados com datasets massivos usando algoritmos avançados de machine learning (ML) para aprender os padrões e as estruturas da linguagem humana e gerar respostas de texto para prompts escritos. Exemplos de LLMs incluem BERT, Claude, Gemini, Llama e a família de LLMs Generative Pretrained Transformer (GPT).
Os LLMs superaram significativamente seus predecessores em desempenho e capacidade em diversas tarefas relacionadas à linguagem. A capacidade deles de gerar conteúdo complexo e com nuances e automatizar tarefas para obter resultados semelhantes aos de humanos está impulsionando avanços em diversas áreas. Os LLMs estão sendo amplamente integrados ao mundo dos negócios para gerar impacto em diversos ambientes e casos de uso de negócios, incluindo a automação do suporte, a apresentação de percepções e a geração de conteúdo personalizado.
As principais capacidades de AI de LLM e linguagem incluem:
- Compreensão de linguagem natural: Os LLMs conseguem entender as nuances da linguagem humana, incluindo contexto, semântica e intenção.
- Geração de conteúdo multimodal: LLMs podem produzir textos semelhantes aos humanos para diversas finalidades, desde programação até escrita criativa, bem como imagens, fala e muito mais.
- Respostas a perguntas: LLMs podem responder a perguntas abertas de forma inteligente.
- Escalabilidade: os LLMs podem aproveitar os recursos da unidade de processamento gráfico (GPU) para realizar com eficiência tarefas de linguagem em grande escala e se adaptar às crescentes necessidades de negócios.
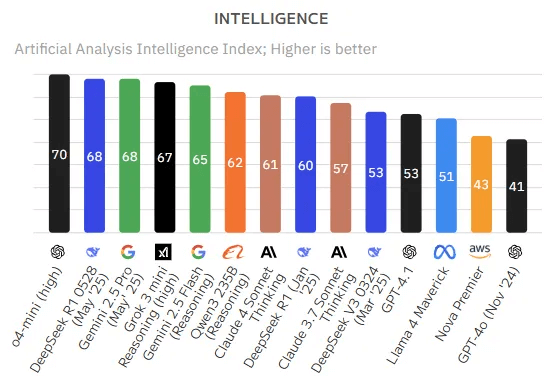
Como funcionam os LLMs?
A maioria dos LLMs usa uma arquitetura transformer. Eles funcionam quebrando o texto de entrada em tokens (unidades de subpalavras), incorporando esses tokens em vetores numéricos e usando mecanismos de atenção para entender as relações no texto de entrada. Em seguida, eles preveem os próximos tokens em uma sequência para gerar resultados coerentes.
O que significa pré-treinar LLMs?
O pré-treinamento de um modelo LLM refere-se ao processo de treiná-lo em um grande conjunto de dados, como texto ou código, sem usar nenhum conhecimento prévio ou pesos de um modelo existente. O resultado do pré-treinamento completo é um modelo básico que pode ser usado diretamente ou ajustado para tarefas downstream.
O pré-treinamento garante que o conhecimento fundamental do modelo seja personalizado para seu domínio específico. O resultado é um modelo personalizado que se diferencia pelos dados exclusivos da sua organização. No entanto, o pré-treinamento costuma ser o tipo de treinamento maior e mais caro e não é comum para a maioria das organizações.
O que significa fazer o ajuste fino de LLMs?
Ajuste fino é o processo de adaptação de um LLM pré-treinado em um dataset comparativamente menor que é específico a um domínio ou tarefa individual. Durante o processo de ajuste fino, ele continua treinando por um curto período, possivelmente ajustando um número relativamente menor de pesos em comparação com todo o modelo.
As duas formas mais comuns de ajuste fino são:
Ajuste fino de instruções supervisionadas: essa abordagem envolve o treinamento contínuo de um LLM pré-treinado em um dataset de exemplos de treinamento de entrada e saída — geralmente conduzidos com milhares de exemplos de treinamento.
Pré-treinamento contínuo: esse método de ajuste fino não depende de exemplos de entrada e saída, mas usa textos não estruturados específicos do domínio para continuar o mesmo processo de pré-treinamento (como a previsão do próximo tokens e a modelagem de linguagem mascarada).
O ajuste fino é importante porque permite que uma organização use um LLM de base e o ensine com seus próprios dados para obter maior acurácia e personalização para o domínio e as cargas de trabalho da empresa. Isso também permite controlar os dados usados no treinamento para você ter certeza de que está usando a IA com responsabilidade.
Redes neurais e arquitetura transformer
Os LLMs são baseados em aprendizagem profunda, uma forma de AI na qual grandes quantidades de dados são inseridas em um programa para ensiná-lo, com base em probabilidade. Com a exposição a datasets massivos, os LLMs podem ensinar a si mesmos para reconhecer padrões e relações de linguagem sem programação explícita, com mecanismos de autoaprendizagem para melhorar continuamente a precisão.
A base dos LLMs são as redes neurais artificiais, inspiradas na estrutura do cérebro humano. Essas redes consistem em nós interconectados organizados em camadas, incluindo uma camada de entrada, uma camada de saída e uma ou mais camadas intermediárias. Cada nó processa e transmite informações para a próxima camada com base em padrões aprendidos.
Os LLMs usam um tipo de rede neural chamada de modelo transformer. Esses modelos inovadores conseguem analisar uma frase inteira de uma só vez, ao contrário dos modelos mais antigos que processam as palavras sequencialmente. Isso permite que eles compreendam a linguagem de forma mais rápida e eficiente. Os modelos Transformer usam uma técnica matemática chamada de autoatenção, que atribui importâncias variadas a diferentes palavras em uma frase, permitindo que o modelo compreenda as nuances de significado e entenda o contexto. A codificação posicional ajuda o modelo a entender a importância da ordem das palavras em uma frase, o que é essencial para compreender a linguagem. O modelo transformer permite que os LLMs processem grandes quantidades de dados, aprendam informações contextualmente relevantes e gerem conteúdo coerente.
Uma versão simplificada do processo de treinamento de LLM
Saiba mais sobre transformadores, a base de todo LLM
Continue explorando

The Big Book of Generative AI
Práticas recomendadas para construir aplicativos de GenAI com qualidade de produção.

Aproveite o potencial dos LLMs
Como aumentar a eficiência e reduzir os custos com IA.
O Databricks foi classificado em primeiro lugar em Execução e Visão
Quadrante Mágico™ da Gartner® de 2025 para Plataformas de Ciência de Dados e Machine Learning
Quais são os casos de uso para LLMs?
Os LLMs podem impulsionar o impacto nos negócios em todos os casos de uso e em diferentes setores. Exemplos de casos de uso incluem:
- Chatbots e assistentes virtuais: os LLMs são usados para que os chatbots possam dar a clientes e funcionários a capacidade de ter conversas abertas para ajudar no suporte ao cliente, acompanhamento de leads do site e ser um assistente pessoal.
- Criação de conteúdo: os LLMs podem gerar diferentes tipos de conteúdo, como artigos, postagens no blog e atualizações para redes sociais.
- Geração e depuração de código: os LLMs podem gerar trechos de código úteis, identificar e corrigir erros no código e programas completos com base em instruções de entrada.
- Análise de sentimento: os LLMs podem entender automaticamente o sentimento de um texto para avaliar a satisfação do cliente.
- Classificação e agrupamento de texto: os LLMs podem organizar, categorizar e classificar grandes volumes de dados para identificar temas comuns e tendências para dar suporte à tomada de decisão informada.
- Tradução de idiomas: os LLMs podem traduzir documentos e páginas da web para diferentes idiomas para alcançar diferentes mercados.
- Resumo e paráfrase: os LLMs podem resumir artigos, ligações de clientes ou reuniões e apresentar os pontos mais importantes.
- Segurança: os LLMs podem ser usados em cibersegurança para identificar padrões de ameaça e automatizar respostas.
Quais são alguns clientes em que os LLMs foram implantados de forma eficaz?
JetBlue
A JetBlue implementou o "BlueBot", um chatbot que usa modelos de IA generativa de código aberto complementados por dados corporativos, com tecnologia da Databricks. Esse chatbot pode ser usado por todas as equipes da JetBlue para obter acesso a dados que são governados por função. Por exemplo, a equipe de finanças pode ver os dados da SAP e os registros regulatórios, mas a equipe de operações só verá as informações de manutenção.
Chevron Phillips
A Chevron Phillips utiliza soluções de AI generativa baseadas em modelos de código aberto como o Dolly da Databricks para otimizar a automação de processos de documentos. Essas ferramentas transformam dados não estruturados de PDFs e manuais em percepções estruturadas, permitindo uma extração de dados mais rápida e precisa para operações e inteligência de mercado. As políticas de governança garantem produtividade e gerenciamento de riscos, mantendo a rastreabilidade.
Thrivent Financial
A Thrivent Financial está usando AI generativa e o Databricks para acelerar as pesquisas, fornecer percepções mais claras e acessíveis e aumentar a produtividade da engenharia. Ao reunir os dados em uma única plataforma com governança baseada em funções, a empresa cria um espaço seguro onde as equipes podem inovar, explorar e trabalhar com mais eficiência.
Por que os LLMs se tornaram populares de repente?
Há muitos avanços tecnológicos recentes que levaram os LLMs para o centro das atenções:
- Avanço das tecnologías de machine learning: os LLMs utilizam muitos avanços nas técnicas de ML. A mais notável é a arquitetura do transformador, que é a arquitetura subjacente à maioria dos modelos de LLM.
- Acessibilidade ampliada: O lançamento do ChatGPT abriu as portas para que qualquer pessoa com acesso à internet pudesse interagir com um dos LLMs mais avançados por meio de uma interface web simples, permitindo que o mundo entendesse o poder dos LLMs.
- Aumento do poder computacional: a disponibilidade de recursos computacionais mais potentes, como unidades de processamento gráfico (GPUs) e técnicas melhores de processamento de dados, permitiu que os pesquisadores ensinassem modelos muito maiores.
- Quantidade e qualidade dos dados de treinamento: A disponibilidade de grandes datasets e a capacidade de processá-los melhoraram drasticamente o desempenho do modelo. Por exemplo, o GPT-3 foi treinado em big data (cerca de 500 bilhões de tokens) que incluiu subconjuntos de dados de alta qualidade, como o dataset WebText2 (17 milhões de documentos), que contém páginas da web rastreadas publicamente com ênfase na qualidade.
Como posso personalizar um LLM com os dados da minha organização?
Existem quatro padrões de arquitetura a considerar ao personalizar uma aplicação de LLM com os dados da sua organização. Essas técnicas são descritas abaixo e não são mutuamente exclusivas. Em vez disso, elas podem (e devem) ser combinadas para aproveitar os pontos fortes de cada uma.
| Método | Definição | Caso de uso principal | Requisitos de dados | Vantagens | Considerações |
|---|---|---|---|---|---|
| Elaboração de prompts especializados para orientar o comportamento do LLM | Orientação rápida e instantânea do modelo | Nenhuma | Rápida, econômica, sem necessidade de treinamento | Menos controle do que o ajuste fino | |
| Combinar um LLM com recuperação de conhecimento externo | Datasets dinâmicos e conhecimento externo | Base de conhecimento externa ou base de dados (por exemplo, base de dados vetorial) | Contexto atualizado dinamicamente, maior precisão | Aumenta o comprimento do prompt e o cálculo da inferência | |
| Adaptando um LLM pré-treinado a datasets ou domínios específicos | Especialização de domínio ou tarefa | Milhares de exemplos específicos de domínio ou instruções | Controle granular, alta especialização | Exige dados rotulados, custo computacional | |
| Treinar um LLM do zero | Tarefas exclusivas ou corpora específicos do domínio | Grandes datasets (bilhões a trilhões de tokens) | Controle máximo, personalizado para necessidades específicas | Extremamente intensivo em recursos |

Independentemente da técnica selecionada, a criação de uma solução de maneira bem estruturada e modularizada garante que as organizações estejam preparadas para iterar e se adaptar. Saiba mais sobre esta abordagem e muito mais em The Big Book of Generative AI.
O que significa engenharia de prompt em relação aos LLMs?
A engenharia de prompt é a prática de ajustar os prompts de texto dados a um LLM para obter respostas mais precisas ou relevantes. Nem todo modelo de LLM produzirá a mesma qualidade, já que a engenharia de prompt é específica do modelo. A seguir estão algumas dicas gerais que funcionam para vários modelos:
- Use prompts claros e concisos, que podem incluir instruções, contexto (se necessário), query ou entrada do usuário e uma descrição do tipo ou formato de saída desejado.
- Forneça exemplos em seu prompt ("aprendizado rápido") para ajudar o LLM a entender o que você deseja.
- Diga ao modelo como se comportar. Por exemplo, diga a ele para admitir se não conseguir responder a uma pergunta.
- Diga ao modelo para pensar passo a passo ou explicar seu raciocínio.
- Se o seu prompt incluir entrada do usuário, use técnicas para evitar a invasão do prompt, como deixar bem claro quais partes do prompt correspondem à sua instrução e quais correspondem à entrada do usuário.
O que significa geração aumentada por recuperação (RAG) em relação aos LLMs?
Geração aumentada por recuperação, ou RAG, é uma abordagem de arquitetura que pode melhorar a eficácia das aplicações de LLM aproveitando dados personalizados. Isso é feito recuperando dados/documentos relevantes para uma pergunta ou tarefa e fornecendo-os como contexto para o LLM. A RAG está tendo sucesso no suporte a chatbots e sistemas de perguntas e respostas que precisam manter informações atualizadas ou acessar conhecimento específico do domínio.
Saiba mais sobre a RAG aqui.
Quais são os LLMs mais comuns e quais são as diferenças entre eles?
O campo dos LLMs está lotado de opções para escolher. De modo geral, você pode agrupar LLMs em duas categorias: serviços proprietários e modelos de código aberto.
Modelos proprietários
Os modelos de LLM proprietários são desenvolvidos e pertencem a empresas privadas e, geralmente, exigem licenças para serem acessados. Talvez o LLM proprietário de maior destaque seja o GPT-4o, que alimenta o ChatGPT, lançado em 2022 com grande alarde. O ChatGPT oferece uma interface de pesquisa amigável em que os usuários podem alimentar prompts e, em geral, receber uma resposta rápida e relevante. Os desenvolvedores podem acessar a API do ChatGPT para integrar esse LLM em seus próprios aplicativos, produtos ou serviços. Outros modelos proprietários incluem o Gemini do Google e o Claude da Anthropic.
Modelos de código aberto
Outra opção é auto-hospedar um LLM, normalmente usando um modelo de código aberto e disponível para uso comercial. A comunidade de código aberto alcançou rapidamente o desempenho dos modelos proprietários. Modelos de LLM de código aberto populares incluem o Llama 4 da Meta e o Mixtral 8x22B.
Como avaliar a melhor escolha
As maiores considerações e diferenças na abordagem entre o uso de uma API de um fornecedor terceirizado fechado em relação à auto-hospedagem do seu próprio modelo LLM de código aberto (ou com ajuste fino) incluem ser à prova de futuro, gerenciar custos e aproveitar seus dados como uma vantagem competitiva. Modelos proprietários podem ser preteridos e removidos, quebrando seus pipelines existentes e índices vetoriais; modelos de código aberto estarão acessíveis a você para sempre. Modelos de código aberto e ajustados podem oferecer mais opções e personalização para sua aplicação, permitindo uma relação melhor entre custo e desempenho. O planejamento para o ajuste fino futuro de seus próprios modelos permitirá aproveitar os dados da sua organização como uma vantagem competitiva para criar modelos melhores do que os disponíveis publicamente. Finalmente, os modelos proprietários podem suscitar preocupações de governança, pois esses LLMs de "caixa preta" permitem menos supervisão de seus processos de treinamento e pesos.
Hospedar seus próprios modelos de LLM de código aberto exige mais trabalho do que usar LLMs proprietários. O MLflow da Databricks facilita para alguém com experiência em Python usar qualquer modelo de transformador como um objeto Python.
Como escolher qual LLM usar?
Avaliar LLMs é uma atribuição desafiadora e em evolução, principalmente porque os LLMs geralmente demonstram capacidades desiguais em diferentes tarefas. Um LLM pode se destacar em um benchmark, mas pequenas variações na solicitação ou no problema podem afetar drasticamente o desempenho.
Algumas ferramentas e benchmarks proeminentes usados para avaliar o desempenho do LLM incluem:
- MLflow
- Fornece um conjunto de ferramentas LLMops para avaliação de modelos.
- Mosaic Model Gauntlet
- Uma abordagem de avaliação agregada, categorizando a competência do modelo em seis domínios amplos (mostrados abaixo), em vez de resumi-la a uma única métrica monolítica.
- O Hugging Face reúne centenas de milhares de modelos de colaboradores abertos do LLM
- BIG-bench (benchmark além do Jogo da Imitação)
- Uma estrutura dinâmica de benchmarking, que atualmente hospeda mais de 200 tarefas, com foco na adaptação a futuros recursos de LLM.
- Avaliação de LM EleutherAI
- Uma estrutura holística que avalia modelos em mais de 200 tarefas, combinando avaliações como BIG-bench e MMLU, promovendo reprodutibilidade e comparabilidade.
Leia também as práticas recomendadas para avaliação de LLM de aplicativos RAG.
Como você operacionaliza o gerenciamento de LLMs via operações de grandes modelos de linguagem?
As operações de grandes modelos de linguagem (LMOps) englobam as práticas, técnicas e ferramentas usadas para o gerenciamento operacional de grandes modelos de linguagem em ambientes de produção.
O LLMOps permite a implantação, o monitoramento e a manutenção eficientes de LLMs. O LLMOps, como o tradicional Machine Learning Ops (MLOps), exige uma colaboração de data scientists, engenheiros de DevOps e profissionais de TI. Veja mais detalhes do LLMOps aqui.
Onde posso encontrar mais informações sobre modelos de linguagem grandes (LLMs)?
Existem muitos recursos disponíveis para encontrar mais informações sobre LLMs, incluindo:
Treinamento
- LLMs: Foundation Models From the Ground Up (EDX e treinamento da Databricks) — Treinamento gratuito da Databricks que se aprofunda nos detalhes dos modelos básicos em LLMs
- LLMs: Application Through Production (EDX e treinamento da Databricks) — Treinamento gratuito da Databricks que se concentra na criação de aplicativos focados em LLM com as estruturas mais recentes e conhecidas
e-books
- The Big Book of Generative AI
- O Guia Compacto para Ajuste Fino e Criação de LLMs Personalizados
- Guia compacto para grandes modelos de linguagem
Blogs técnicos
- Apresentando o Llama 4 da Meta na Databricks Data Intelligence Platform | Blog da Databricks
- Disponibilizando modelos Qwen no Databricks | Databricks Blog
- Práticas recomendadas para avaliação de LLM de aplicativos RAG
- Usar MLflow AI Gateway e Llama 2 para construir aplicativos de IA generativa
- Crie aplicativos RAG de alta qualidade com o Mosaic AI Agent Framework e a Avaliação de Agentes, Model Serving e Busca Vetorial.
- LLMops: tudo o que você precisa saber para gerenciar LLMs
Passos seguintes
- Entre em contato com a Databricks para agendar uma demonstração e conversar com alguém sobre seus projetos de grandes modelos de linguagem (LLM)
- Leia sobre as ofertas da Databricks para LLMs
- Leia mais sobre o caso de uso de geração aumentada de recuperação (RAG) (a arquitetura de LLM mais comum)