Servindo modelo
Implantação e governança unificadas para todos os modelos e agentes de AI


Introdução
O Mosaic AI Model Serving fornece às empresas uma solução robusta para implantar modelos clássicos de ML, modelos generativos de AI e agentes de AI. Ele oferece suporte a modelos proprietários, como Azure OpenAI, AWS Bedrock e Anthropic, bem como modelos de código aberto, como Llama e Mistral. Os clientes também podem fornecer modelos de código aberto ajustados ou modelos clássicos de ML treinados em seus próprios dados. Os clientes podem usar facilmente os modelos servidos como endpoints em seus fluxos de trabalho, como inferência em lotes em grande escala ou aplicativos em tempo real. O Model Serving também vem com governança, linhagem e monitoramento integrados para garantir resultados de alta qualidade.
Citações de clientes
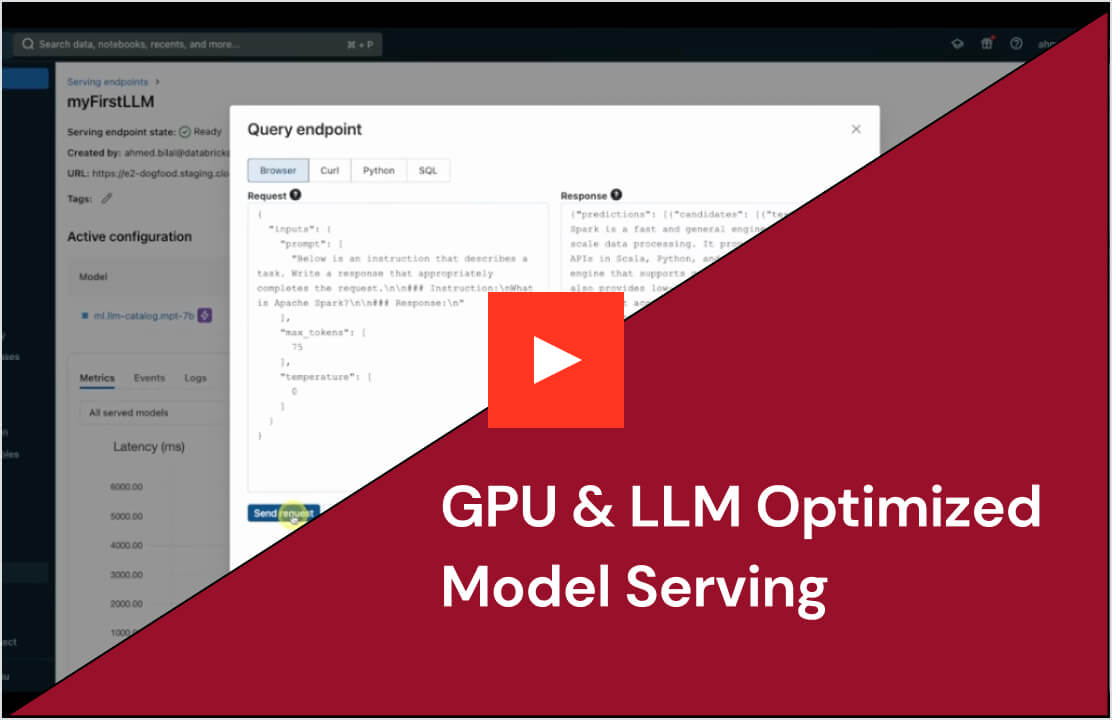
Implantação simplificada para todos os modelos e agentes de AI
Implante qualquer tipo de modelo, desde modelos de código aberto pré-treinados até modelos personalizados construídos em seus próprios dados — tanto em CPUs quanto em GPUs. A construção automatizada de contêineres e o gerenciamento de infraestrutura reduzem os custos de manutenção e aceleram a implantação para que você possa se concentrar na criação de seus sistemas de agentes de AI e na entrega de valor mais rapidamente para sua empresa.
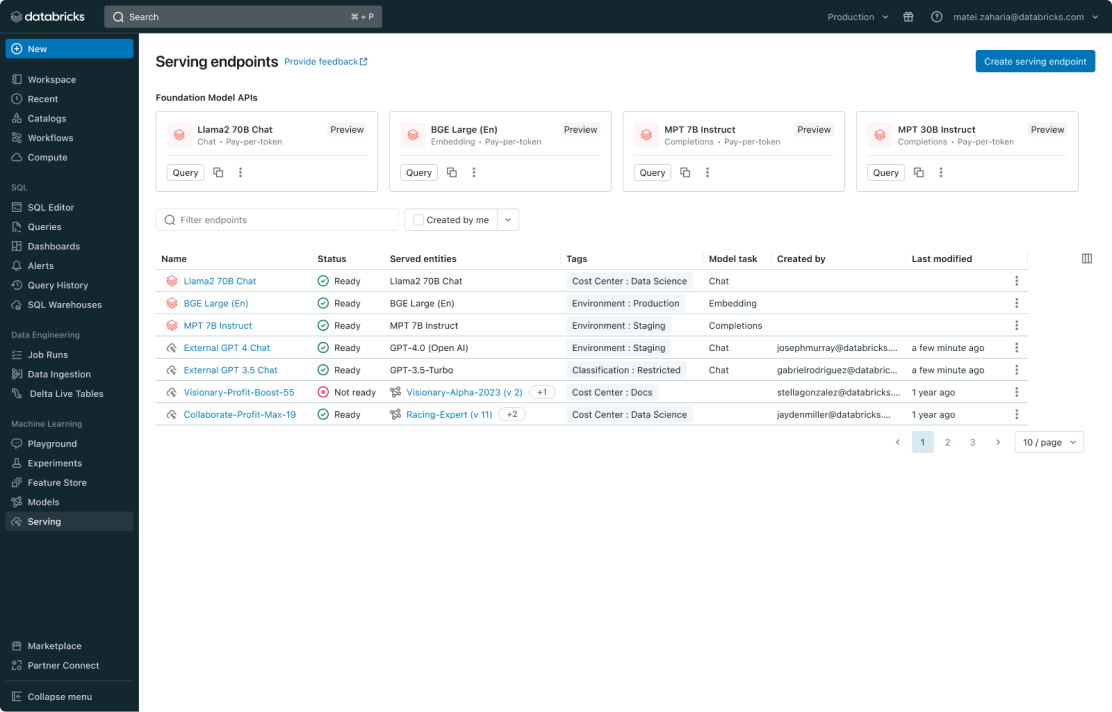
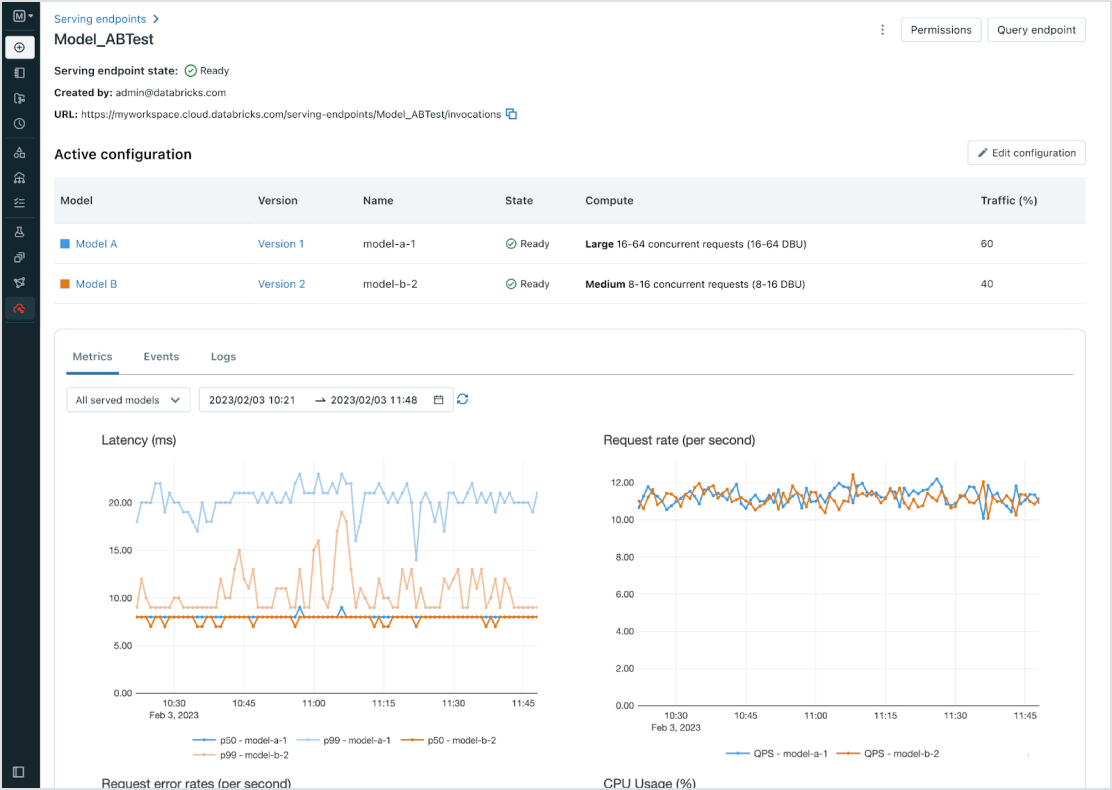
Gerenciamento unificado para todos os modelos
Gerencie todos os modelos, incluindo modelos de ML personalizados, como PyFunc, scikit-learn e LangChain, modelos básicos (FMs) no Databricks, como Llama 3, MPT e BGE, e modelos básicos hospedados em outros locais, como ChatGPT, Claude 3, Cohere e Stable Diffusion. O Model Serving torna todos os modelos acessíveis em uma interface de usuário e API unificadas, incluindo modelos hospedados pela Databricks ou de outro provedor de modelos no Azure ou AWS.
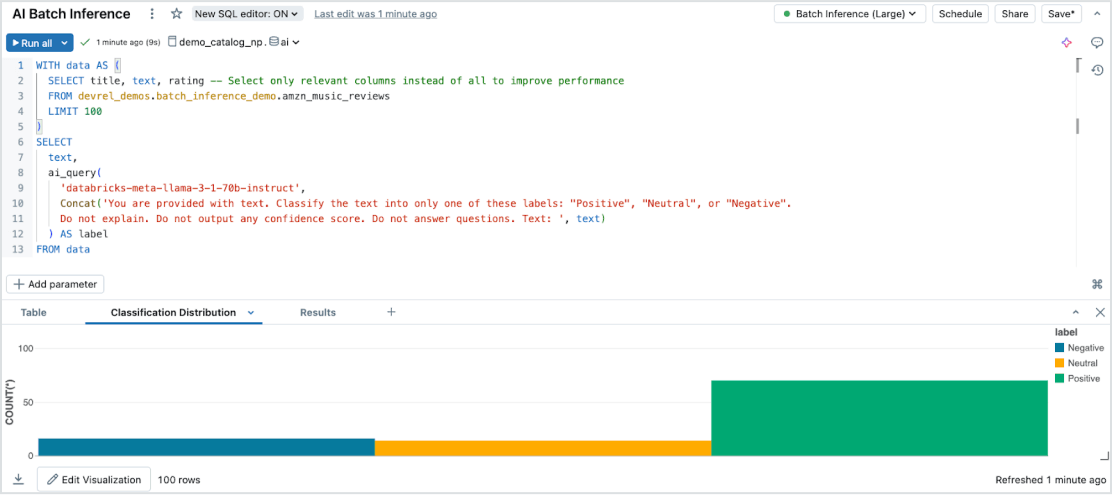
Inferência em lote sem esforço
O Model Serving permite inferência de AI eficiente e serverless em grandes datasets em todos os tipos de dados e modelos. Integre-se perfeitamente ao Databricks SQL, Notebooks e fluxos de trabalho para aplicar a AI em escala. Com o AI Functions, execute inferência em lote em grande escala instantaneamente, sem gerenciamento de infraestrutura, garantindo velocidade, escalabilidade e governança.
Governança incorporada
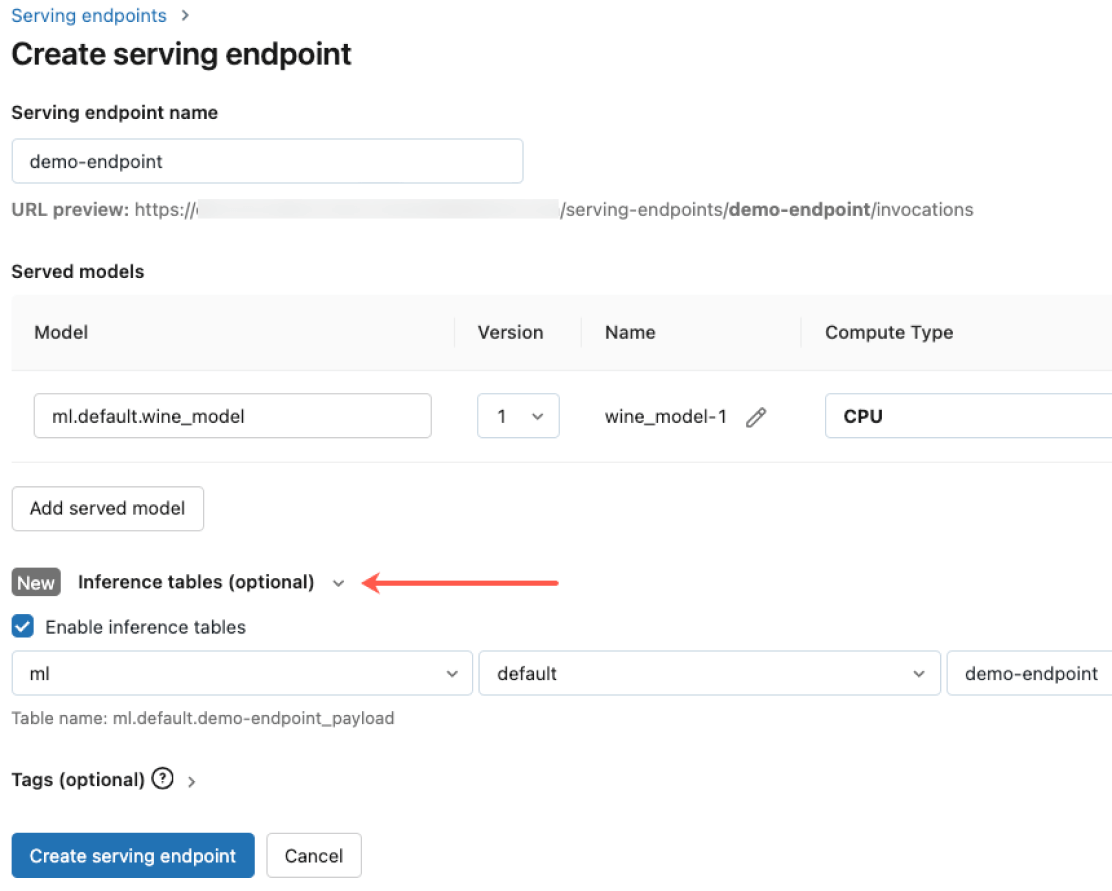
Integre-se ao Mosaic AI Gateway para atender aos rigorosos requisitos de segurança e governança avançada. Você pode impor as permissões adequadas, monitorar a qualidade do modelo, definir limites de taxa e rastrear a linhagem em todos os modelos, estejam eles hospedados pela Databricks ou em qualquer outro provedor de modelos.
Modelos baseados em dados
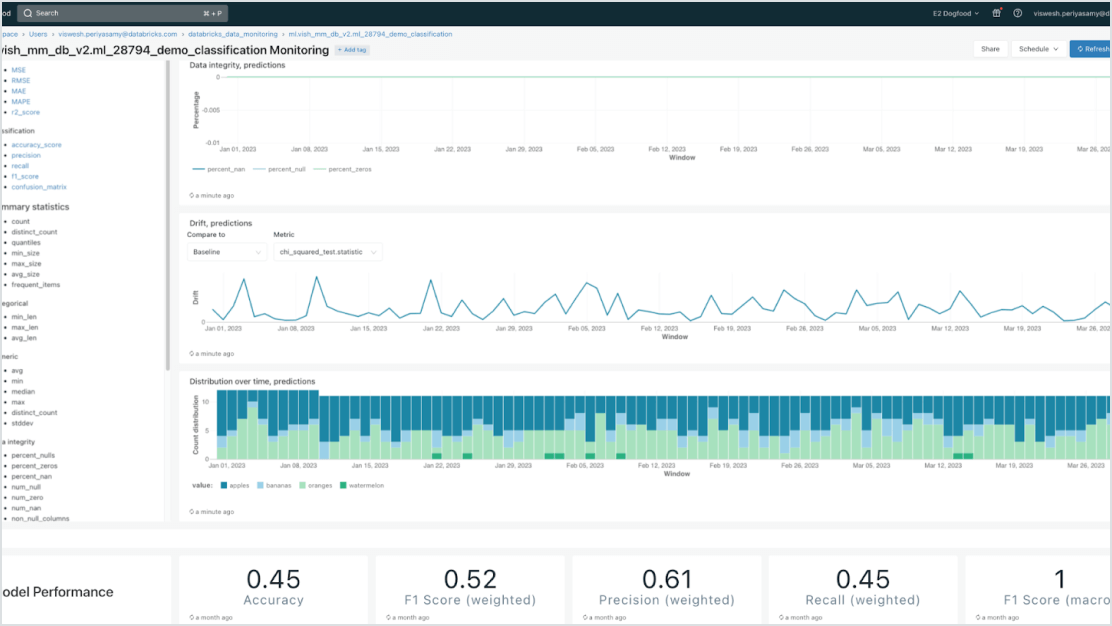
Acelere as implementações e reduza os erros por meio da integração profunda com a plataforma de inteligência de dados. Você pode hospedar facilmente vários modelos clássicos de ML e AI generativa, aumentados (RAG) ou ajustados com seus dados empresariais. O Model Serving oferece pesquisas automatizadas, monitoramento e governança em todo o ciclo de vida da AI.
Econômico
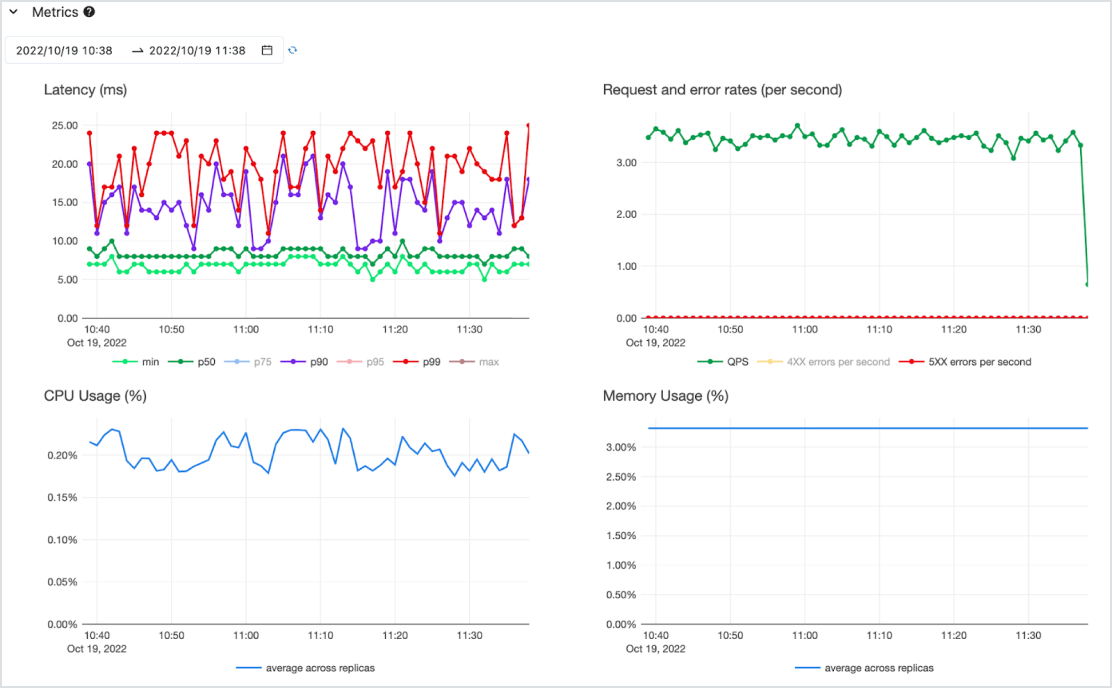
Disponibilize modelos como uma API de baixa latência em um serviço serverless altamente disponível com suporte de CPU e GPU. Dimensione sem esforço a partir do zero para atender às suas necessidades mais críticas e reduza a escala quando os requisitos mudarem. Você pode começar rapidamente com um ou mais modelos pré-implantados e cargas de trabalho de compute pagas por token (sob demanda, sem compromissos) ou pagas por provisionamento para obter throughput garantido. A Databricks cuidará do gerenciamento da infraestrutura e dos custos de manutenção, para que você possa se concentrar em gerar valor comercial.