ingegnerizzazione delle feature
Ingegneria delle funzionalità per il machine learning
L'ingegneria delle funzionalità, detta anche pre-elaborazione dei dati, è il processo di conversione dei dati grezzi in funzionalità utilizzabili per sviluppare modelli di machine learning. Questo articolo descrive i concetti principali dell'ingegneria delle funzionalità e il ruolo che essa svolge nella gestione del ciclo di vita del ML.
Nel contesto del machine learning, le funzionalità sono i dati di input utilizzati per addestrare un modello, ovvero gli attributi di un'entità che il modello imparerà a conoscere. Generalmente, i dati grezzi devono essere elaborati prima di poter essere utilizzati come input per un modello di ML. Una buona ingegneria delle funzionalità rende più efficiente il processo di sviluppo e si traduce in modelli più semplici, flessibili e accurati.
Che cos'è l'ingegneria delle funzionalità?
L'ingegneria delle funzionalità è il processo di trasformazione e arricchimento dei dati volto a migliorare le prestazioni degli algoritmi di machine learning utilizzati per addestrare i modelli che fanno uso di tali dati.
L'ingegneria delle funzionalità comprende fasi quali il ridimensionamento o la normalizzazione dei dati, la codifica di dati non numerici (come testo o immagini), l'aggregazione in base al tempo o all'entità, l'unione di dati provenienti da fonti diverse o il trasferimento di conoscenze da altri modelli. L'obiettivo di queste trasformazioni è aumentare la capacità degli algoritmi di machine learning di apprendere dai set di dati, allo scopo di restituire previsioni più accurate.
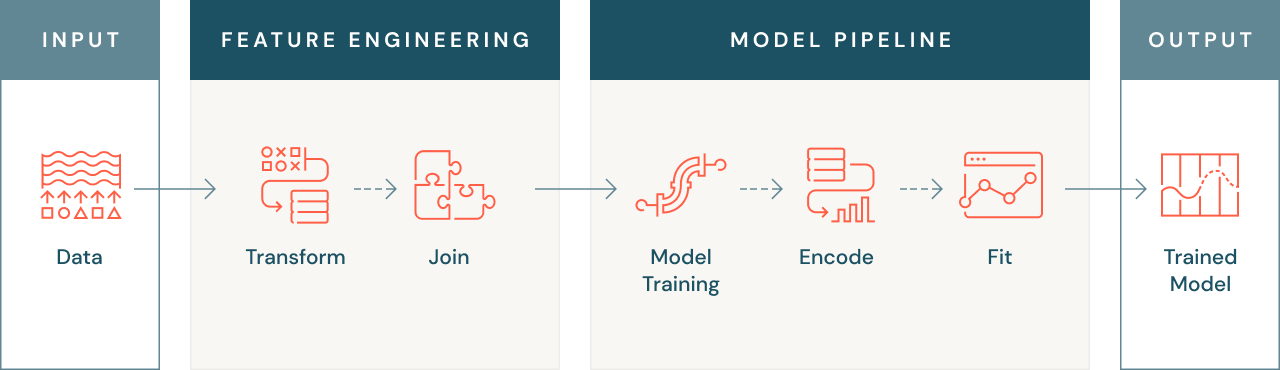
Perché l'ingegneria delle funzionalità è importante?
L'ingegneria delle funzionalità ricopre diverse funzioni importanti. In primo luogo, come accennato in precedenza, i modelli di machine learning non sono sempre in grado di operare su dati grezzi, e quindi tali dati devono essere convertiti in una forma numerica che il modello possa comprendere. Ciò può comportare ad esempio la conversione di dati di testo o di immagini in forma numerica, o la creazione di funzionalità aggregate come i valori medi delle transazioni per un cliente.
A volte le funzionalità rilevanti per un problema di machine learning possono essere presenti in più sorgenti di dati: un'ingegneria delle funzionalità efficace prevederà l'unione di queste sorgenti di dati per creare un unico data set utilizzabile. In questo modo, sarà possibile utilizzare tutti i dati disponibili per addestrare il modello, migliorandone accuratezza e prestazioni.
Un altro scenario comune è il riutilizzo sotto forma di funzionalità dei risultati e dell'apprendimento di altri modelli per un nuovo problema, tramite un processo noto come apprendimento per trasferimento. Ciò consente di sfruttare le conoscenze acquisite dai modelli precedenti per migliorare le prestazioni di un nuovo modello. L'apprendimento per trasferimento può essere particolarmente utile nelle situazioni in cui si ha a che fare con set di dati grandi e complessi, in cui non è conveniente addestrare un modello da zero.
Un'ingegneria delle funzionalità efficace consente anche di ottenere funzionalità affidabili nel momento dell'inferenza, quando il modello viene utilizzato per fare previsioni su nuovi dati. Si tratta di un aspetto importante perché le funzionalità utilizzate al momento dell'inferenza devono essere le stesse impiegate per l'addestramento così da evitare il cosiddetto "online/offline skew", il problema che si determina quando le funzionalità utilizzate al momento della predizione sono calcolate in modo diverso rispetto a quelle utilizzate per l'addestramento.
In che modo l'ingegneria delle funzionalità è diversa da altre forme di trasformazione dei dati?
L'obiettivo dell'ingegneria delle funzionalità è creare un set di dati che possa essere addestrato per costruire un modello di machine learning. Molti degli strumenti e delle tecniche utilizzati per le trasformazioni dei dati sono impiegati anche dall'ingegneria delle funzionalità.
Dal momento che l'ingegneria delle funzionalità si pone come obiettivo lo sviluppo di un modello, ha tipicamente alcuni requisiti specifici che non sono presenti in altri tipi di trasformazioni. Ad esempio, si potrebbe voler fare in modo che le funzionalità siano riutilizzabili in più modelli o in più team all'interno dell'organizzazione. Per rispondere a questa esigenza, serve un metodo robusto per individuare le funzionalità.
Inoltre, quando le funzionalità vengono riutilizzate, serve un sistema per tenere traccia di dove e come le funzionalità sono calcolate. Questo è reso possibile dalla "feature lineage" (derivazione delle funzionalità). La riproducibilità dei calcoli delle funzionalità è di particolare importanza per il machine learning perché la funzionalità non deve essere calcolata soltanto per l'addestramento del modello, ma anche ricalcolata esattamente nello stesso modo quando il modello viene utilizzato per l'inferenza.
Quali sono i vantaggi di un'ingegneria delle funzionalità efficace?
Avere un'efficace pipeline di ingegneria delle funzionalità significa avere pipeline di modellazione più robuste e, in ultima analisi, modelli più affidabili e performanti. Migliorare le funzionalità utilizzate sia per l'addestramento sia per l'inferenza può avere un impatto notevole sulla qualità del modello. Da migliori funzionalità derivano modelli migliori.
Da un altro punto di vista, un'ingegneria delle funzionalità efficace incoraggia anche il riutilizzo delle funzionalità, facendo non solo risparmiare tempo ai professionisti, ma migliorando anche la qualità dei loro modelli. Questo riutilizzo delle funzionalità è importante per due motivi: da una parte consente di risparmiare tempo, dall'altra avere funzionalità definite in modo robusto aiuta a evitare che i modelli utilizzino dati di funzionalità diversi nella fase di addestramento e in quella di inferenza, causa questa del cosiddetto "online/offline skew".
Quali strumenti sono necessari per l'ingegneria delle funzionalità?
In generale, gli strumenti usati per l'ingegneria dei dati possono essere riutilizzati per l'ingegneria delle funzionalità, dal momento che la maggior parte delle trasformazioni è comune a entrambe. Di solito, questi strumenti includono un sistema di archiviazione e gestione dei dati, l'accesso a linguaggi di trasformazione standard aperti (SQL, Python, Spark, ecc.) e l'accesso a un tipo di elaboratore per eseguire le trasformazioni.
Esistono, tuttavia, alcuni strumenti aggiuntivi che possono essere implementati per l'ingegneria delle funzionalità, sotto forma di librerie Python specifiche che aiutano a creare trasformazioni di dati specifiche per il machine learning, come l'integrazione di testo o immagini, o la codifica one-hot di variabili categoriali. Esistono anche alcuni progetti open-source che aiutano a tenere traccia delle funzionalità utilizzate da un modello.
Il versioning dei dati è uno strumento importante per l'ingegneria delle funzionalità, dal momento che spesso i modelli vengono addestrati su un set di dati che nel frattempo è stato soggetto a modifiche. Una corretta gestione del versioning dei dati consente di riprodurre un determinato modello mentre i dati si evolvono naturalmente nel corso del tempo.
Che cos'è un archivio di funzionalità?
Un archivio di funzionalità è uno strumento progettato per rispondere alle sfide dell'ingegneria delle funzionalità. È un repository centralizzato che consente di gestire e condividere funzionalità all'interno di un'organizzazione. I data scientist possono utilizzare un archivio di funzionalità per individuare e condividere le funzionalità e tracciarne la derivazione. Un archivio di funzionalità garantisce inoltre che vengano utilizzati gli stessi valori delle funzionalità tanto in fase di addestramento quanto in fase di inferenza. La riproducibilità del calcolo delle funzionalità è di particolare importanza per il machine learning, perché la funzionalità non deve essere calcolata soltanto per l'addestramento del modello, ma anche ricalcolata esattamente nello stesso modo quando il modello viene utilizzato per l'inferenza.
Perché utilizzare Databricks Feature Store?
Databricks Feature Store è completamente integrato con gli altri componenti di Databricks. È possibile utilizzare notebook Databricks per sviluppare il codice, creare funzionalità e costruire modelli basati su di esse. Quando si distribuisce un modello con Databricks, esso cerca automaticamente i valori delle funzionalità nell'archivio di funzionalità per l'inferenza. Databricks Feature Store offre tutti i vantaggi degli archivi di funzionalità descritti in questo articolo:
- Individuazione. L'interfaccia utente dell'archivio di funzionalità, accessibile dallo spazio di lavoro Databricks, consente di cercare le funzionalità esistenti.
- Derivazione. Quando si crea una tabella delle funzionalità con Databricks Feature Store, le sorgenti di dati utilizzate per crearla restano salvate e accessibili. Per ogni funzionalità nella tabella, sarà possibile accedere anche ai modelli, ai notebook, ai processi e agli endpoint che la utilizzano.
Inoltre, Databricks Feature Store fornisce:
- Integrazione con l'assegnazione di punteggio ai modelli e la loro distribuzione. Quando si utilizzano le funzionalità di Databricks Feature Store per addestrare un modello, questo viene creato in un pacchetto con i metadati delle funzionalità. Quando lo si utilizza per l'assegnazione di punteggi batch o per l'inferenza online, il modello recupera automaticamente le funzionalità dal Databricks Feature Store. Non è necessario che il chiamante le conosca o che includa la logica per cercare o combinare funzionalità per assegnare un punteggio ai nuovi dati. La distribuzione e gli aggiornamenti dei modelli risultano così molto più semplici.
- Ricerche point-in-time. Databricks Feature Store supporta casi d'uso basati su serie temporali ed eventi che richiedono correttezza point-in-time.