Cosa sono le applicazioni Spark?
Scopri come i processi driver ed esecutori lavorano insieme per eseguire calcoli distribuiti su un cluster

Summary
- Comprendere l'architettura delle applicazioni Spark, incluso il modo in cui i processi driver gestiscono la logica dell'applicazione e coordinano il lavoro nel cluster.
- Scoprire come i processi esecutori eseguono le attività assegnate e segnalano lo stato di elaborazione al driver.
- Esplorare come i gestori di cluster come YARN, Mesos e Spark standalone allocano risorse per più applicazioni simultanee.
Le applicazioni Spark sono costituite da un processo driver e un insieme di processi executor (esecutori). Il processo driver esegue la funzione main(), risiede su un nodo nel cluster ed è responsabile di tre attività: mantenere le informazioni sull'applicazione Spark; rispondere a un programma o un input dell'utente; e analizzare, distribuire e schedulare il lavoro fra gli esecutori (definiti al momento). Il processo driver è assolutamente fondamentale, è il cuore dell'applicazione Spark e mantiene tutte le informazioni rilevanti per tutta la vita dell'applicazione. Gli esecutori sono responsabili della concreta esecuzione del lavoro assegnato loro dal driver. Ogni esecutore, quindi, ha solo due responsabilità: eseguire il codice assegnatogli dal driver e riferire al nodo del driver lo stato del calcolo su quello stesso esecutore.
Gartner®: Databricks leader dei database cloud

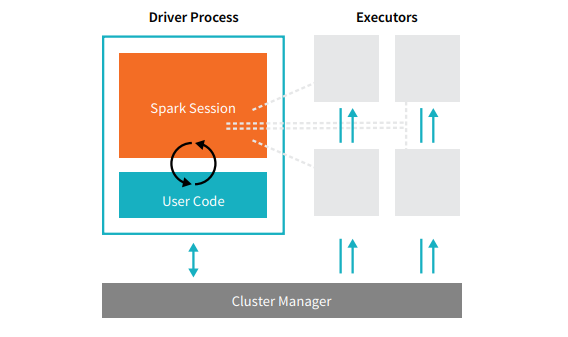
Il gestore del cluster controlla le macchine fisiche e alloca risorse alle applicazioni Spark. Esistono diversi gestori di cluster: il cluster manager di Spark, YARN o Mesos. Ciò significa che ci possono essere più applicazioni Spark che girano sullo stesso cluster contemporaneamente. Parleremo dei gestori di cluster più in dettaglio nella Parte IV: Applicazioni di produzione, di questo manuale. La precedente illustrazione mostra il driver a sinistra e quattro esecutori a destra. In questo diagramma abbiamo eliminato il concetto di nodi del cluster. L'utente può specificare quanti esecutori devono cadere su ogni nodo attraverso le configurazioni. [glossary-cta]