
Approfondisci la data science su Databricks
L'intero flusso di lavoro di data science — dalla preparazione dei dati, passando per la modellazione, fino alla condivisione delle informazioni — può essere snellito con un ambiente di data science unificato e collaborativo, basato su una piattaforma lakehouse aperta. In questo modo si potrà accedere velocemente a dati puliti e affidabili, risorse di calcolo preconfigurate, integrazione IDE, assistenza multilingua e strumenti integrati di visualizzazione avanzata per offrire la massima flessibilità ai team di analisi dei dati.

Collaborazione lungo l'intero flusso di lavoro di data science
Scrivi codice in Python, R, Scala e SQL, esplora i dati con visualizzazioni interattive e scopri nuove informazioni con i notebook di Databricks. È possibile condividere codice in modo affidabile e sicuro con co-creazione, commenti, gestione automatica delle versioni, integrazioni Git e controllo degli accessi per ruoli.

Focalizzazione sulla data science, non sull'infrastruttura
Non ci sono limiti imposti dalla quantità di dati conservabili nel proprio laptop o dalla capacità di calcolo disponibile. Migra rapidamente sul cloud il tuo ambiente locale e collega i notebook ai tuoi cluster personali di calcolo e autogestiti.

Utilizzare l'ambiente di sviluppo IDE preferito con capacità di calcolo scalabile
La scelta dell'ambiente di sviluppo IDE (Integrated Development Environment) è molto soggettiva e incide fortemente sulla produttività.Collegando il proprio IDE preferito a Databricks si potrà comunque beneficiare di capacità illimitate di stoccaggio dati e calcolo. In alternativa, si possono utilizzare RStudio o JupyterLab direttamente dall'interno di Databricks per ottenere un'esperienza fluida.
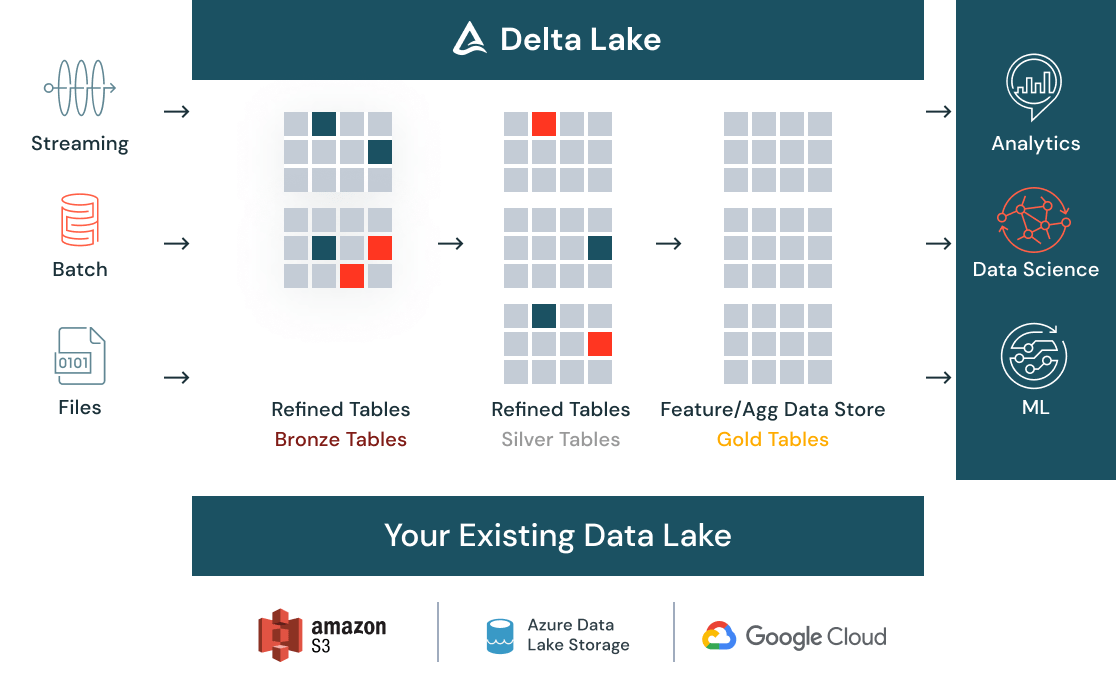
Preparare i dati per la data science
Tutti i dati (in batch o in streaming, strutturati o non strutturati) possono essere puliti e catalogati in un unico punto con Delta Lake ed essere accessibili all'intera organizzazione attraverso un data store centralizzato. Man mano che i dati affluiscono, i controlli di qualità automatici garantiscono che i dati siano conformi alle aspettative e pronti per l'analisi. Quando i dati si evolvono con l'acquisizione di nuovi dati e ulteriori elaborazioni, la gestione delle versioni assicura il rispetto delle esigenze di conformità.

Strumenti visivi low-code per l'esplorazione dei dati
Usa gli strumenti visivi in modo nativo dai notebook Databricks per preparare, trasformare e analizzare i tuoi dati, permettendo ai team con vari livelli di esperienza di lavorare con i dati. Una volta concluse le trasformazioni e le visualizzazioni dei dati, potrai generare il codice in esecuzione in background, risparmiando tempo nella scrittura del codice boilerplate per poter dedicare più tempo ai compiti di alto valore.
Scoprire e condividere nuove informazioni
I risultati possono ora essere facilmente condivisi ed esportati trasformando velocemente l'analisi in un dashboard dinamico. I dashboard sono sempre aggiornati e possono anche effettuare interrogazioni interattive. Celle, visualizzazioni o notebook possono essere condivisi con il controllo degli accessi per ruoli ed esportati in diversi formati, fra cui HTML e IPython Notebook.
