a easyJet aposta na Databricks e na IA Generativa para ser uma Líder de Inovação na Aviação

Este blog é de autoria de Ben Dias, Diretor de Ciência de Dados e Análise e Ioannis Mesionis, Cientista de Dados Sênior na easyJet
Introdução à easyJet
A easyJet voa em mais rotas populares da Europa do que qualquer outra companhia aérea e transportou mais de 69 milhões de passageiros em 2022 - com 9,5 milhões viajando a negócios. A companhia aérea possui mais de 300 aeronaves em quase 1000 rotas para mais de 150 aeroportos em 36 países. Mais de 300 milhões de europeus vivem a uma hora de carro de um aeroporto easyJet.
Como muitas empresas do setor aéreo, a easyJet atualmente enfrenta desafios em relação à experiência do cliente e à digitalização. No cenário competitivo de hoje, os clientes estão mudando suas preferências rapidamente, e suas expectativas em relação ao atendimento ao cliente nunca foram tão altas. Ter uma estratégia adequada de dados e IA pode desbloquear muitas oportunidades de negócios relacionadas ao atendimento digital ao cliente, personalização e otimização de processos operacionais.
Desafios Enfrentados pela easyJet
Quando iniciamos este projeto, a easyJet já era cliente da Databricks há quase um ano. Nesse ponto, estávamos aproveitando totalmente o Databricks para engenharia e armazenamento de dados e acabamos de migrar todas as nossas cargas de trabalho de ciência de dados e começamos a migrar nossas cargas de trabalho de análise para o Databricks. Também estamos ativamente desativando nossa antiga pilha de tecnologia, à medida que migramos nossas cargas de trabalho para nossa nova Plataforma de Inteligência de Dados Databricks.
Ao migrar as cargas de trabalho de engenharia de dados para uma arquitetura de lakehouse no Databricks, conseguimos colher benefícios em termos de racionalização de plataforma, menor custo, menos complexidade e a capacidade de implementar casos de uso de dados em tempo real. No entanto, o fato de ainda haver uma parte significativa do patrimônio rodando em nosso antigo hub de dados significava que a idealização e a produção de novos casos de uso de ciência de dados e IA permaneciam complexos e demorados.
Uma arquitetura baseada em data lake tem benefícios em termos de volumes de dados que os clientes são capazes de ingerir, processar e armazenar. No entanto, a falta de governança e capacidades de colaboração impactam a habilidade das empresas de executar experimentos de ciência de dados e IA e iterar rapidamente.
Também vimos o surgimento de aplicações de IA generativa, o que apresenta um desafio em termos de implementação e implantação quando estamos falando de propriedades de data lake. Aqui, experimentar e idealizar requer constantemente copiar e mover dados entre diferentes silos, sem a devida governança e linhagem. Na etapa de implantação, com uma arquitetura de data lake, os clientes geralmente se veem tendo que adicionar várias plataformas de fornecedores de nuvem ou desenvolver MLOps, soluções de implantação e atendimento por conta própria - o que é conhecido como a abordagem faça você mesmo.
Ambos os cenários apresentam diferentes desafios. Ao adicionar vários produtos de fornecedores de nuvem à arquitetura de uma empresa, os clientes mais frequentemente do que não incorrem em altos custos, altos encargos e uma necessidade aumentada de pessoal especializado - resultando em altos custos de OPEX. Quando se trata de DIY, existem custos significativos tanto do ponto de vista de CAPEX quanto de OPEX. Você precisa primeiro construir suas próprias capacidades de MLOps e Serving - o que já pode ser bastante assustador - e uma vez que você construa, você precisa manter essas plataformas funcionando, não apenas do ponto de vista da evolução da plataforma, mas também dos pontos de vista operacional, de infraestrutura e de segurança.
Quando trazemos esses desafios para o domínio da IA gerativa e dos Grandes Modelos de Linguagem (LLMs), seu impacto se torna ainda mais pronunciado devido aos requisitos de hardware. As placas de Unidade de Processamento Gráfico (GPUs) têm custos significativamente mais altos em comparação com o hardware de CPU comoditizado. Portanto, é fundamental pensar em uma maneira otimizada de incluir esses recursos em sua arquitetura de dados. Falhar em fazer isso representa um enorme risco de custo para as empresas que desejam colher todos os benefícios da IA gerativa e dos LLMs; ter capacidades Serverless mitiga muito esses riscos, ao mesmo tempo que reduz o overhead operacional associado à manutenção de tal infraestrutura especializada.
Por que IA de lakehouse?
Escolhemos a Databricks principalmente porque a arquitetura lakehouse nos permitiu separar o processamento do armazenamento. A plataforma unificada da Databricks também permitiu que as equipes multifuncionais da easyJet colaborassem de maneira integrada em uma única plataforma, levando a um aumento na produtividade.
Por meio de nossa parceria com a Databricks, também temos acesso às mais recentes inovações em IA - lakehouse AI - e somos capazes de prototipar e experimentar rapidamente nossas ideias junto com sua equipe de especialistas. “Quando se tratou de nossa jornada com LLM, trabalhar com a Databricks parecia que éramos uma grande equipe e não parecia que eles eram apenas um fornecedor e nós éramos um cliente”, diz Ben Dias, Diretor de Ciência de Dados e Análise na easyJet.
Aprofundamento na Solução
O objetivo deste projeto era fornecer uma ferramenta para nossos usuários não técnicos fazerem suas perguntas em linguagem natural e obterem insights de nossos ricos conjuntos de dados. Este insight seria de grande valor no processo de tomada de decisão.
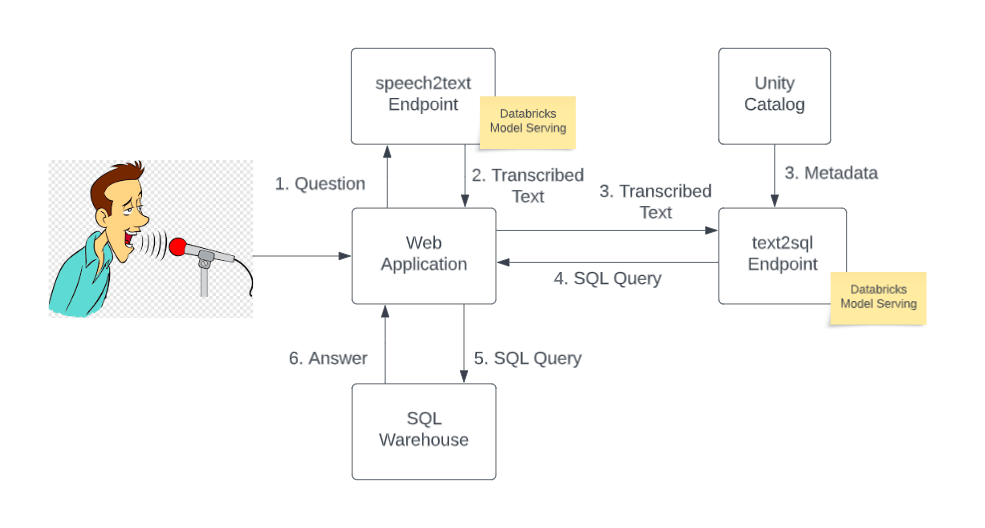
O ponto de entrada para o aplicativo é uma interface de usuário na web. A interface do usuário na web permite que os usuários façam perguntas em linguagem natural usando um microfone (por exemplo, o microfone embutido em seu laptop). A fala é então enviada para um LLM de código aberto (Whisper) para transcrição. Uma vez transcrita, a pergunta e os metadados das tabelas relevantes no Catálogo Unity são reunidos para criar um prompt e então submetidos a outro LLM de código aberto para conversão de texto para SQL. O modelo text2sql retorna uma consulta SQL sintaticamente correta que é então enviada para um armazém SQL e a resposta é retornada e exibida na interface do usuário na web.
Para resolver a tarefa text2sql, experimentamos com vários LLMs de código aberto. Graças às ferramentas LLMOps disponíveis na Databricks, em particular sua integração com Hugging Face e diferentes sabores de LLM no MLflow, encontramos uma barreira de entrada baixa para começar a trabalhar com LLMs. Poderíamos trocar sem problemas os modelos subjacentes para esta tarefa à medida que melhores modelos de código aberto fossem lançados.
Ambos os modelos de transcrição e text2sql são servidos em um endpoint de API REST usando o Databricks Model Serving com suporte para GPU Nvidia A10G. Como um dos primeiros clientes da Databricks a aproveitar o serviço de GPU, conseguimos servir nossos modelos em GPU com alguns cliques, passando do desenvolvimento para a produção em poucos minutos. Sendo serverless, o Model Serving eliminou a necessidade de gerenciar infraestrutura complicada e permitiu que nossa equipe se concentrasse no problema de negócios e reduzisse massivamente o tempo de entrada no mercado.
“Com a IA de lakehouse, poderíamos hospedar modelos de IA generativa de código aberto em nosso próprio ambiente, com total controle. Além disso, o Databricks Model Serving automatizou a implantação e inferência desses LLMs, eliminando qualquer necessidade de lidar com infraestrutura complicada. Nossas equipes poderiam apenas se concentrar na construção da solução - na verdade, levou apenas algumas semanas para chegarmos a um MVP." diz Ioannis Mesionis, Lead Data Scientist na easyJet.
Resultados de Negócios Alcançados como Resultado da Escolha da Databricks
Este projeto é um dos primeiros passos em nosso roteiro GenAI e com a Databricks conseguimos chegar a um MVP em algumas semanas. Conseguimos transformar uma ideia em algo tangível com o qual nossos clientes internos podem interagir. Esta aplicação abre o caminho para a easyJet ser um negócio verdadeiramente orientado a dados. Nossos usuários de negócios têm acesso mais fácil aos nossos dados agora. Eles podem interagir com os dados usando linguagem natural e podem basear suas decisões nos insights fornecidos pelos LLMs.
O que vem a seguir para a easyJet?
Esta iniciativa permitiu à easyJet experimentar facilmente e quantificar o benefício de um caso de uso de IA gerativa de ponta. A solução foi apresentada a mais de 300 pessoas do departamento de TI, Dados & Mudança da easyJet, e o entusiasmo ajudou a gerar novas ideias em torno de casos de uso inovadores de Gen AI, como assistentes pessoais para recomendações de viagens, chatbots para processos operacionais e conformidade, bem como otimização de recursos.
Uma vez apresentada com a solução, o conselho de executivos da easyJet rapidamente concordou que há um potencial significativo em incluir a IA gerativa em seu roadmap. Como resultado, agora há uma parte específica do orçamento dedicada a explorar e trazer esses casos de uso à vida para aumentar as capacidades dos funcionários e clientes da easyJet, ao mesmo tempo que proporciona a eles uma experiência de usuário melhor e mais orientada a dados.
Nunca perca uma postagem da Databricks
O que vem a seguir?

Notícias
December 23, 2024/8 min de leitura
