Melhorando a Recuperação e o RAG com o Ajuste Fino do Modelo de Incorporação
Summary
- Como o ajuste fino dos modelos de embedding aumenta a precisão de recuperação e RAG
- Ganhos de desempenho chave em benchmarks
- Começando com o ajuste fino de embedding no Databricks
Ajuste Fino de Modelos de Incorporação para Melhor Recuperação e RAG
Resumo: O ajuste fino de um modelo de incorporação em dados do domínio pode melhorar significativamente a busca e a precisão da geração aumentada por recuperação (RAG). Com o Databricks, é fácil ajustar, implantar e avaliar modelos de incorporação para otimizar a recuperação para o seu caso de uso específico—aproveitando dados sintéticos sem rotulagem manual.
Por que isso é importante: Se a sua busca por vetores ou sistema RAG não está trazendo os melhores resultados, o ajuste fino de um modelo de incorporação é uma maneira simples, porém poderosa, de melhorar o desempenho. Seja lidando com documentos financeiros, bases de conhecimento ou documentação de código interno, o ajuste fino pode fornecer resultados de pesquisa mais relevantes e melhores respostas de LLM downstream.
O que descobrimos: Ajustamos e testamos dois modelos de incorporação em três conjuntos de dados empresariais e vimos melhorias significativas nas métricas de recuperação (Recall@10) e no desempenho downstream do RAG. Isso significa que o ajuste fino pode ser um divisor de águas para a precisão sem exigir rotulagem manual, aproveitando apenas seus dados existentes.
Quer experimentar o aprimoramento de incorporação? Nós fornecemos uma solução de referência para ajudá-lo a começar. Databricks facilita a busca por vetores, RAG, reranking e o ajuste fino de incorporações. Entre em contato com o seu Executivo de Contas Databricks ou Arquiteto de Soluções para mais informações.
Por que Ajustar os Embeddings?
Modelos de incorporação potencializam a busca vetorial moderna e os sistemas RAG. Um modelo de incorporação transforma texto em vetores, tornando possível encontrar conteúdo relevante com base no significado, e não apenas em palavras-chave. No entanto, os modelos prontos nem sempre são otimizados para o seu domínio específico—é aí que entra o ajuste fino.
Ajustar um modelo de incorporação em dados específicos do domínio ajuda de várias maneiras:
- Melhore a precisão da recuperação: As incorporações personalizadas melhoram os resultados da pesquisa, alinhando-se com seus dados.
- Melhore o desempenho do RAG: Uma melhor recuperação reduz as alucinações e permite respostas de IA gerativas mais fundamentadas.
- Melhore o custo e a latência: Um modelo ajustado menor pode às vezes superar alternativas maiores e mais caras.
Neste post, mostramos que o ajuste fino de um modelo de incorporação é uma maneira eficaz de melhorar a recuperação e o desempenho do RAG para casos de uso específicos da empresa.
Resultados: O Ajuste Fino Funciona
Nós ajustamos dois modelos de incorporação (gte-large-en-v1.5 e e5-mistral-7b-instruct) em dados sintéticos e os avaliamos em três conjuntos de dados de nossa Suite de Benchmark de Inteligência de Domínio (DIBS) (FinanceBench, ManufactQA e Databricks DocsQA). Em seguida, os comparamos com o text-embedding-3-large da OpenAI.
Principais Conclusões:
- O ajuste fino melhorou a precisão da recuperação em todos os conjuntos de dados, muitas vezes superando significativamente os modelos de base.
- As incorporações ajustadas tiveram um desempenho tão bom ou melhor do que a reclassificação em muitos casos, mostrando que podem ser uma solução autônoma forte.
- Uma melhor recuperação levou a um melhor desempenho do RAG no FinanceBench, demonstrando benefícios de ponta a ponta.
Desempenho de Recuperação
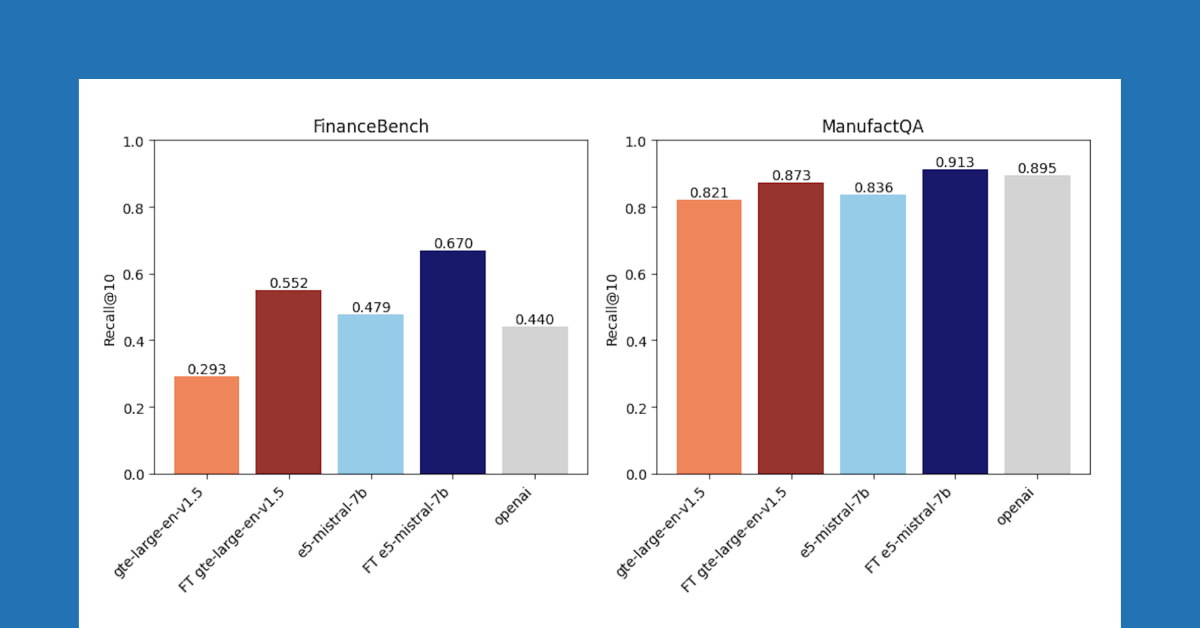
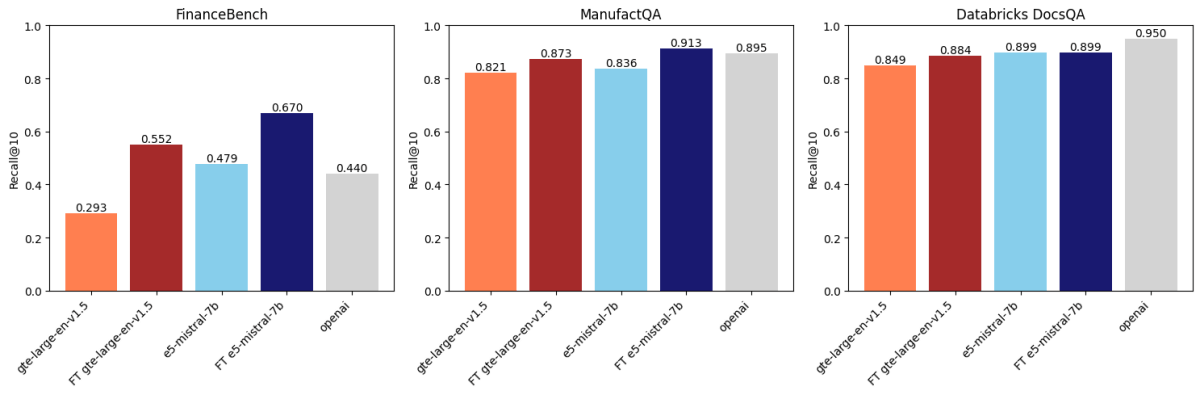
Após comparar três conjuntos de dados, descobrimos que o ajuste fino de incorporação melhora a precisão em dois desses conjuntos de dados. A Figura 1 mostra que para FinanceBench e ManufactQA, as incorporações ajustadas superaram suas versões base, às vezes até superando o modelo API da OpenAI (cinza claro). Para o Databricks DocsQA, no entanto, a precisão do text-embedding-3-large da OpenAI supera todos os modelos ajustados. É possível que isso ocorra porque o modelo foi treinado na documentação pública do Databricks. Isso mostra que, embora o ajuste possa ser eficaz, ele depende fortemente do conjunto de dados de treinamento e da tarefa de avaliação.
Ajuste Fino vs. Reordenamento
Em seguida, comparamos os resultados acima com a reclassificação baseada em API usando voyageai/rerank-1 (Figura 2). Um reclassificador normalmente pega os k resultados principais recuperados por um modelo de incorporação, reclassifica esses resultados por relevância para a consulta de pesquisa e, em seguida, retorna os k principais reclassificados (no nosso caso k=30 seguido por k=10). Isso funciona porque os reclassificadores geralmente são modelos maiores e mais poderosos do que os modelos de incorporação e também modelam a interação entre a consulta e o documento de uma maneira mais expressiva.
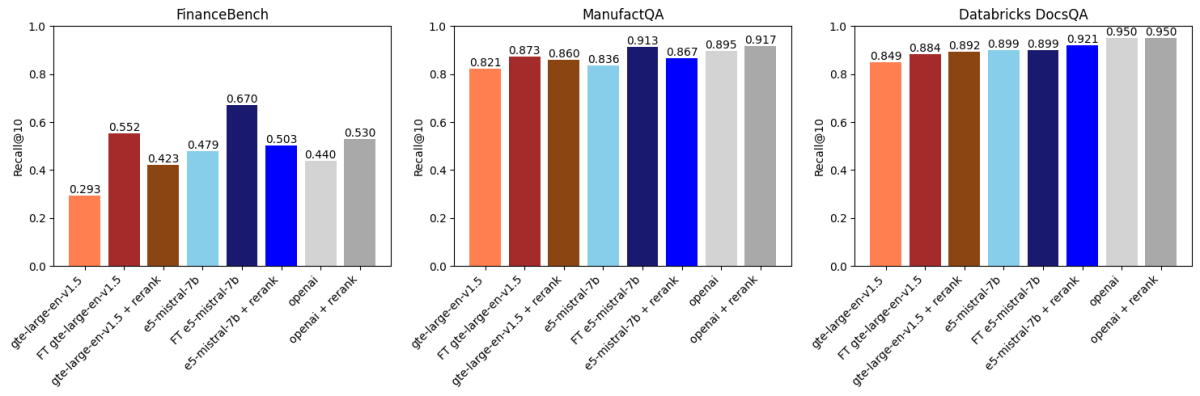
O que descobrimos foi:
- O ajuste fino do gte-large-en-v1.5 superou o reordenamento no FinanceBench e ManufactQA.
- O text-embedding-3-large da OpenAI se beneficiou da reclassificação, mas as melhorias foram marginais em alguns conjuntos de dados.
- Para o Databricks DocsQA, a reclassificação teve um impacto menor, mas o ajuste fino ainda trouxe melhorias, mostrando a natureza dependente do conjunto de dados desses métodos.
Os reclassificadores geralmente incorrem em latência adicional de inferência por consulta e custo em relação aos modelos de incorporação. No entanto, eles podem ser usados com bancos de dados de vetores existentes e, em alguns casos, podem ser mais econômicos do que a re-incorporação de dados com um modelo de incorporação mais recente. A escolha de usar um reclassificador depende do seu domínio e das suas necessidades de latência/custo.
O Ajuste Fino Ajuda o Desempenho do RAG
Para o FinanceBench, uma melhor recuperação se traduziu diretamente em melhor precisão do RAG quando combinado com o GPT-4o (veja o Apêndice). No entanto, em domínios onde a recuperação já era forte, como o Databricks DocsQA, o ajuste fino não adicionou muito - destacando que o ajuste fino funciona melhor quando a recuperação é um gargalo claro.
Como Ajustamos e Avaliamos Modelos de Incorporação
Aqui estão alguns dos detalhes mais técnicos da nossa geração de dados sintéticos, ajuste fino e avaliação.
Modelo de incorporação
Nós ajustamos dois modelos de incorporação de código aberto:
- gte-large-en-v1.5 é um modelo de embedding popular baseado no BERT Large (434M parâmetros, 1.75 GB). Escolhemos executar experimentos neste modelo por causa de seu tamanho modesto e licenciamento aberto. Este modelo de incorporação também é atualmente suportado na API do Modelo de Fundação Databricks.
- e5-mistral-7b-instruct pertence a uma nova classe de modelos de incorporação construídos em cima de fortes LLMs (neste caso Mistral-7b-instruct-v0.1). Embora o e5-mistral-7b-instruct seja melhor nos benchmarks de embedding padrão, como MTEB, e seja capaz de lidar com prompts mais longos e nuances, ele é muito maior que o gte-large-en-v1.5 (já que possui 7 bilhões de parâmetros) e é um pouco mais lento e mais caro para servir.
Em seguida, os comparamos com o text-embedding-3-large da OpenAI.
Conjuntos de Dados de Avaliação
Avaliamos todos os modelos nos seguintes conjuntos de dados da nossa Suíte de Benchmark de Inteligência de Domínio (DIBS): FinanceBench, ManufactQA e Databricks DocsQA.
| Conjunto de dados | Descrição | # Consultas | # Corpus |
|---|---|---|---|
| FinanceBench | Perguntas sobre documentos SEC 10-K gerados por especialistas humanos. A recuperação é feita em páginas individuais de um superconjunto de 360 arquivos SEC 10-K. | 150 | 53,399 |
| ManufactQA | Perguntas e respostas coletadas de fóruns públicos de um fabricante de dispositivos eletrônicos. | 6,787 | 6,787 |
| Databricks DocsQA | Perguntas baseadas na documentação publicamente disponível do Databricks gerada por especialistas do Databricks. | 139 | 7,561 |
Reportamos recall@10 como nossa principal métrica de recuperação; isso mede se o documento correto está entre os 10 principais documentos recuperados.
O padrão ouro para a qualidade do modelo de incorporação é o benchmark MTEB, que incorpora tarefas de recuperação como BEIR, bem como muitas outras tarefas não de recuperação. Embora modelos como gte-large-en-v1.5 e e5-mistral-7b-instruct se saiam bem no MTEB, estávamos curiosos para ver como eles se saíam em nossas tarefas internas de empresa.
Dados de treinamento
Treinamos modelos separados em dados sintéticos adaptados para cada um dos benchmarks acima:
| Conjunto de Treinamento | Descrição | # Amostras Únicas |
| FinanceBench Sintético | Consultas geradas a partir de 2.400 documentos SEC 10-K | ~6,000 |
| Documentos Sintéticos de QA do Databricks | Consultas geradas a partir da documentação pública do Databricks. | 8.727 |
| ManufactQA | Consultas geradas a partir de PDFs de fabricação de eletrônicos | 14,220 |
Para gerar o conjunto de treinamento para cada domínio, pegamos documentos existentes e geramos consultas de amostra baseadas no conteúdo de cada documento usando LLMs como Llama 3 405B. As consultas sintéticas foram então filtradas por qualidade por um LLM-como-juiz (GPT4o). As consultas filtradas e seus documentos associados foram então usados como pares contrastantes para o ajuste fino. Usamos negativos em lote para treinamento contrastivo, mas adicionar negativos difíceis poderia melhorar ainda mais o desempenho (veja o Apêndice).
Ajuste de Hiperparâmetros
Realizamos varreduras em:
- Taxa de aprendizado, tamanho do lote, temperatura softmax
- Contagem de épocas (1-3 épocas testadas)
- Variações de prompt de consulta (por exemplo, "Consulta:" vs. prompts baseados em instruções)
- Estratégia de agrupamento (agrupamento médio vs. agrupamento do último token)
Todo o ajuste fino foi feito usando as bibliotecas de código aberto mosaicml/composer, mosaicml/llm-foundry, e mosaicml/streaming na plataforma Databricks.
Como Melhorar a Busca de Vetores e RAG no Databricks
O ajuste fino é apenas uma abordagem para melhorar a busca de vetores e o desempenho do RAG; listamos algumas abordagens adicionais abaixo.
Para Melhor Recuperação:
- Use um modelo de incorporação melhor: Muitos usuários trabalham sem saber com incorporações desatualizadas. Simplesmente trocar por um modelo de melhor desempenho pode trazer ganhos imediatos. Verifique a classificação MTEB para os melhores modelos.
- Experimente a busca híbrida: Combine embeddings densos com busca baseada em palavras-chave para melhorar a precisão. Databricks Vector Search facilita isso com uma solução de um clique.
- Use um reranker: Um reranker pode refinar os resultados reordenando-os com base na relevância. A Databricks oferece isso como um recurso integrado (atualmente em Visualização Privada). Entre em contato com o seu Executivo de Contas para experimentar.
Para um Melhor RAG:
- Otimize suas solicitações: Pequenos ajustes nas solicitações de LLM podem melhorar drasticamente as respostas. DSPy pode ajudar a automatizar este processo (veja Construa aplicativos genAI usando DSPy no Databricks).
- Atualize seu LLM: Se a recuperação é forte, mas as respostas são fracas, considere usar um modelo gerativo melhor.
- Ajuste fino de um LLM: Se o seu domínio é único e você tem dados suficientes, o ajuste fino de um modelo como Llama 3 pode melhorar ainda mais a qualidade do RAG. Veja Treinamento de Modelo de IA Mosaic: Ajuste Fino do Seu LLM no Databricks para Tarefas e Conhecimentos Especializados para mais detalhes.
Comece com o Ajuste Fino no Databricks
O ajuste fino dos embeddings pode ser uma vitória fácil para melhorar a recuperação e o RAG em seus sistemas de IA. No Databricks, você pode:
- Ajuste e sirva modelos de incorporação em uma infraestrutura escalável.
- Use ferramentas integradas para busca de vetores, reclassificação e RAG.
- Teste rapidamente diferentes modelos para encontrar o que funciona melhor para o seu caso de uso.
Pronto para experimentar? Nós construímos uma solução de referência para facilitar o ajuste fino - entre em contato com o seu Executivo de Contas Databricks ou Arquiteto de Soluções para obter acesso.
Apêndice
|
|
|
|
|
||||
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabela 1: Comparação de gte-large-en-v1.5, e5-mistral-7b-instruct e text-embedding-3-large. Mesmos dados da Figura 1.
Gerando Dados de Treinamento Sintéticos
Para todos os conjuntos de dados, as consultas no conjunto de treinamento não eram as mesmas que as consultas no conjunto de teste. No entanto, no caso do Databricks DocsQA (mas não do FinanceBench ou ManufactQA), os documentos usados para gerar consultas sintéticas foram os mesmos documentos usados no conjunto de avaliação. O foco do nosso estudo é melhorar a recuperação em tarefas e domínios específicos (em oposição a um modelo de incorporação generalizável de zero-shot); portanto, vemos isso como uma abordagem válida para certos casos de uso de produção. Para o FinanceBench e ManufactQA, os documentos usados para gerar dados sintéticos não se sobrepunham ao corpus usado para avaliação.
Existem várias maneiras de selecionar passagens negativas para treinamento contrastivo. Eles podem ser selecionados aleatoriamente, ou podem ser pré-definidos. No primeiro caso, as passagens negativas são selecionadas dentro do lote de treinamento; estas são frequentemente referidas como "negativas em lote" ou "negativas suaves". No segundo caso, o usuário pré-seleciona exemplos de texto que são semanticamente difíceis, ou seja, eles são potencialmente relacionados à consulta, mas ligeiramente incorretos ou irrelevantes. Este segundo caso é às vezes chamado de "negativos difíceis". Neste trabalho, simplesmente usamos negativos em lote; a literatura indica que o uso de negativos difíceis provavelmente levaria a resultados ainda melhores.
Detalhes do Ajuste
Para todos os experimentos de ajuste, o comprimento máximo da sequência é definido como 2048. Em seguida, avaliamos todos os pontos de verificação. Para todas as referências, os documentos do corpus foram truncados para 2048 tokens (não divididos), o que era uma restrição razoável para nossos conjuntos de dados específicos. Escolhemos as melhores linhas de base em cada referência após varrer os prompts de consulta e a estratégia de agrupamento.
Melhorando o Desempenho do RAG
Um sistema RAG consiste em um recuperador e um modelo gerativo. O recuperador seleciona um conjunto de documentos relevantes para uma determinada consulta e, em seguida, os alimenta para o modelo gerativo. Selecionamos os melhores modelos gte-large-en-v1.5 ajustados e os usamos para a primeira etapa de recuperação de um sistema RAG simples (seguindo a abordagem geral descrita em Desempenho do RAG de LLMs em Contexto Longo e As Capacidades do RAG de Contexto Longo do OpenAI o1 e Google Gemini). Em particular, recuperamos k=10 documentos cada um com um comprimento máximo de 512 tokens e usamos o GPT4o como o LLM gerativo. A precisão final foi avaliada usando um LLM-como-juiz (GPT4o).
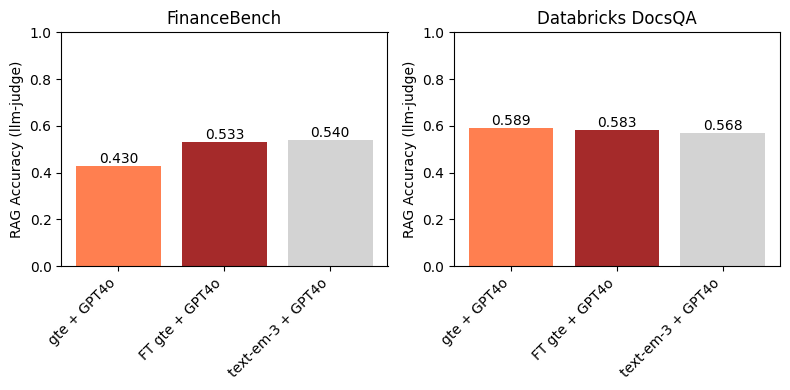
No FinanceBench, a Figura 3 mostra que o uso de um modelo de incorporação ajustado leva a uma melhoria na precisão downstream do RAG. Além disso, é competitivo com o text-embedding-3-large. Isso é esperado, uma vez que o ajuste do gte levou a uma grande melhoria no Recall@10 em relação ao gte de base (Figura 1). Este exemplo destaca a eficácia do ajuste fino do modelo de incorporação em domínios e conjuntos de dados específicos.
No conjunto de dados DocsQA do Databricks, não encontramos melhorias ao usar o modelo gte ajustado acima do gte de linha de base. Isso é um pouco esperado, já que as margens entre os modelos de linha de base e ajustados nas Figuras 1 e 2 são pequenas. Curiosamente, embora o text-embedding-3-large tenha um Recall@10 (ligeiramente) maior do que qualquer um dos modelos gte, ele não leva a uma maior precisão do RAG downstream. Como mostrado na Figura 1, todos os modelos de incorporação tiveram um Recall@10 relativamente alto no conjunto de dados Databricks DocsQA; isso indica que a recuperação provavelmente não é o gargalo para o RAG, e que ajustar um modelo de incorporação neste conjunto de dados não é necessariamente a abordagem mais frutífera.
Gostaríamos de agradecer a Quinn Leng e Matei Zaharia pelo feedback sobre este post do blog.
(This blog post has been translated using AI-powered tools) Original Post
Nunca perca uma postagem da Databricks
O que vem a seguir?

Produto
June 12, 2024/11 min de leitura
Apresentando o AI/BI: analítica inteligente para dados do mundo real

IA generativa
January 7, 2025/8 min de leitura