
É difícil adaptar grandes modelos de linguagem a novas tarefas corporativas. A inserção de prompts é propensa a erros e atinge ganhos de qualidade limitados, enquanto o ajuste fino exige grandes quantidades de dados rotulados por humanos que não estão disponíveis para a maioria das tarefas corporativas. Hoje, estamos introduzindo um novo método de ajuste de modelos que requer apenas dados de uso não rotulados, permitindo que as empresas melhorem a qualidade e o custo da AI usando apenas os dados que já possuem. Nosso método, Otimização Adaptativa em Tempo de Teste (TAO), aproveita o compute em tempo de teste (conforme popularizado por o1 e R1) e o aprendizado por reforço (RL) para ensinar um modelo a realizar uma tarefa melhor com base apenas em exemplos de entrada anteriores, o que significa que ele escala com um orçamento de compute de ajuste flexível, e não com o esforço de rotulagem humana. Fundamentalmente, embora use o compute em tempo de teste, a TAO o usa como parte do processo para treinar um modelo; esse modelo então executa a tarefa diretamente com baixos custos de inferência (ou seja, não requer compute adicional no momento da inferência). Surpreendentemente, mesmo sem dados rotulados, a TAO pode alcançar uma qualidade de modelo melhor do que o ajuste fino tradicional e pode colocar modelos de código aberto de baixo custo, como o Llama, na qualidade de modelos proprietários de alto custo, como GPT-4o e o3-mini.
A TAO faz parte do programa da nossa equipe de pesquisa sobre inteligência de dados, que estuda o problema de tornar a AI excelente em domínios específicos usando os dados que as empresas já possuem. Com a TAO, obtivemos três resultados interessantes:
- Em tarefas corporativas especializadas, como resposta a perguntas sobre documentos e geração de SQL, a TAO supera o ajuste fino tradicional em milhares de exemplos com rótulos. Ele traz modelos de código aberto eficientes, como Llama 8B e 70B, com uma qualidade semelhante a modelos de alto custo, como GPT-4o e o3-mini1, sem a necessidade de rótulos.
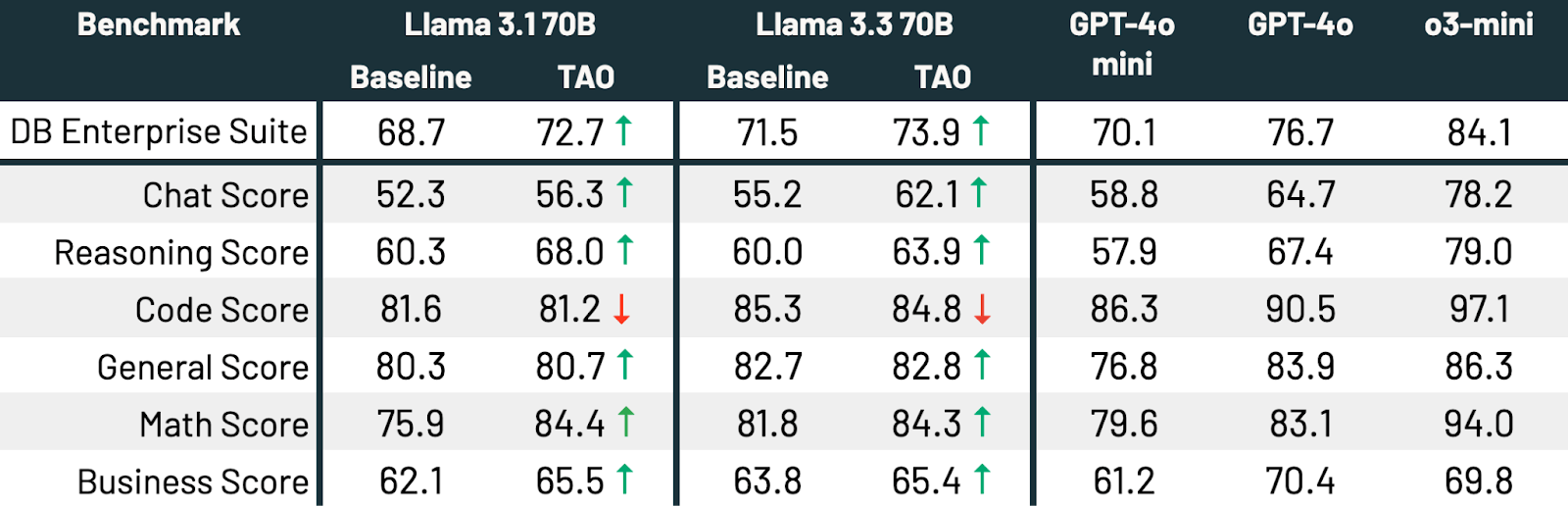
- Também podemos usar a TAO multitarefa para aprimorar um LLM de forma ampla em várias tarefas. Sem rótulos, a TAO melhora o desempenho do Llama 3.3 70B em 2,4% em um amplo benchmark corporativo.
- Aumentar o orçamento de compute da TAO no momento do ajuste produz melhor qualidade do modelo com os mesmos dados, enquanto os custos de inferência do modelo ajustado permanecem os mesmos.
A Figura 1 mostra como a TAO aprimora os modelos Llama em três tarefas corporativas: FinanceBench, DB Enterprise Arena e BIRD-SQL (usando o dialeto Databricks SQL)². Apesar de ter acesso apenas às entradas LLM, a TAO supera o ajuste fino tradicional (FT) com milhares de exemplos rotulados e coloca o Llama na mesma faixa dos modelos proprietários caros.
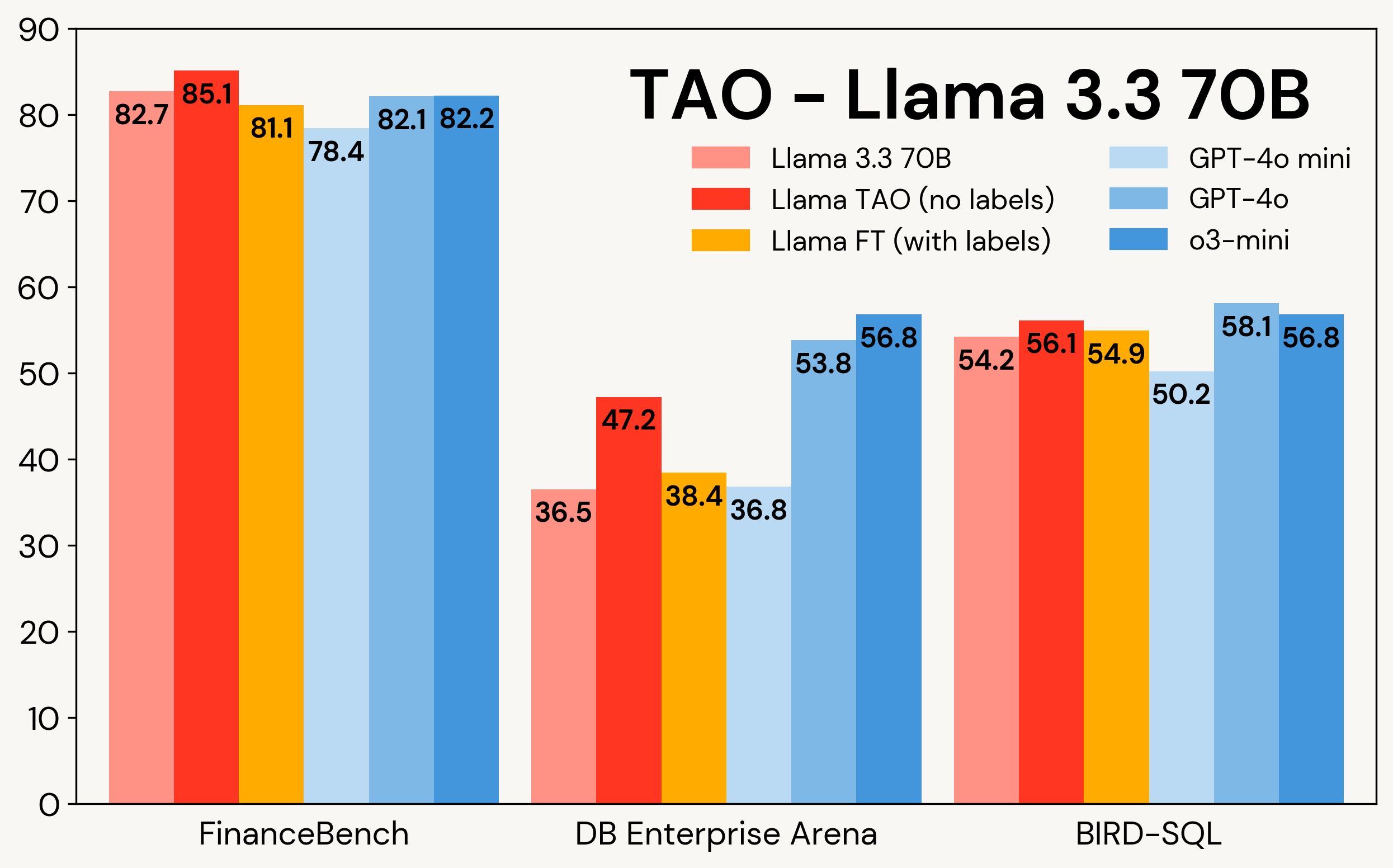
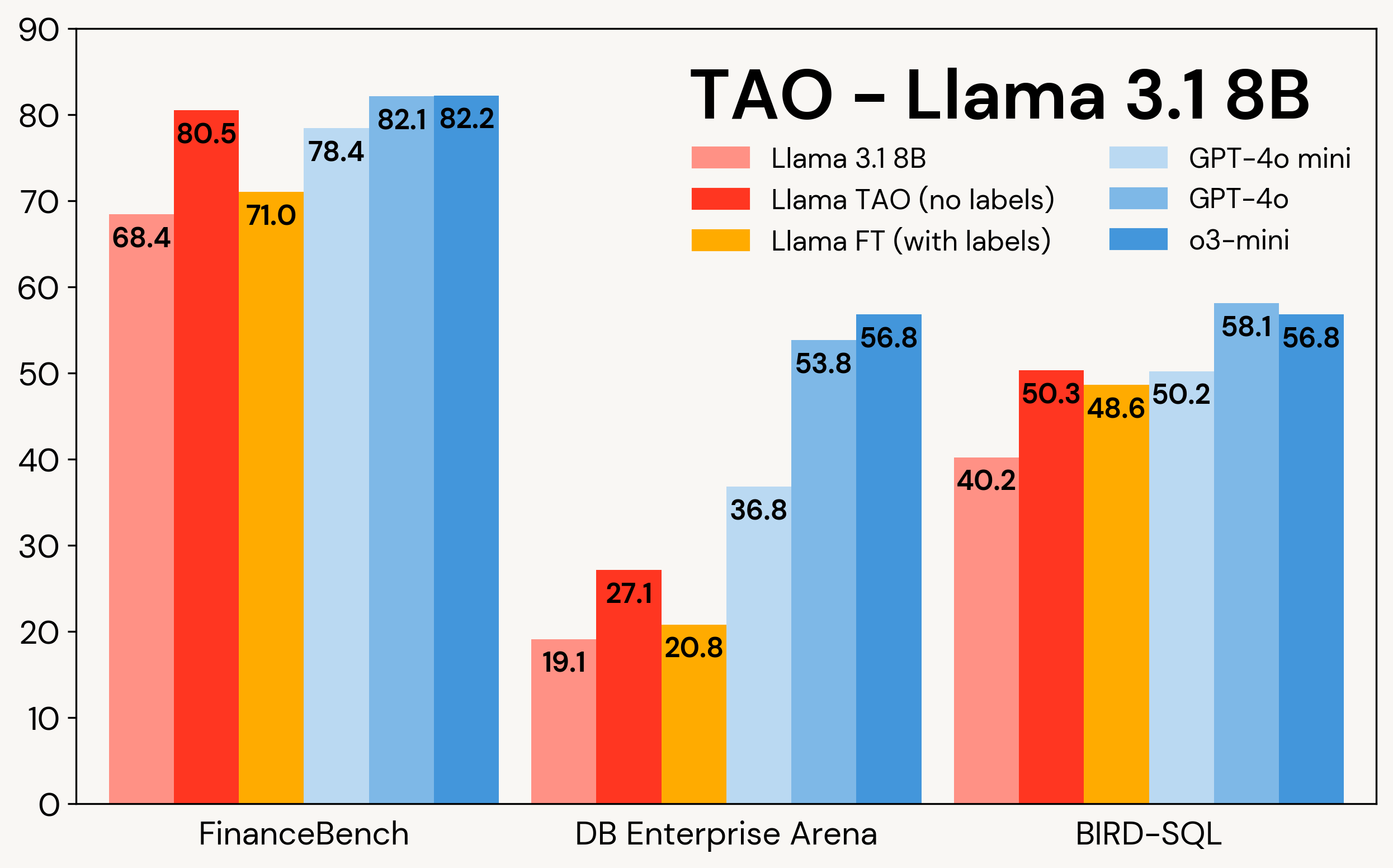
Figura 1: TAO no Llama 3.1 8B e no Llama 3.3 70B em três benchmarks empresariais. A TAO leva a melhorias substanciais na qualidade, superando o ajuste fino e desafiando LLMs proprietários de alto custo.
A TAO agora está disponível em versão prévia para clientes Databricks que queiram ajustar o Llama e servirá de base para vários produtos futuros. Preencha este formulário para demonstrar interesse em testá-la em suas tarefas como parte da pré-visualização privada. Neste post, descrevemos mais sobre como a TAO funciona e os resultados que obtivemos com ele.
Como funciona a TAO? Usando compute em tempo de teste e aprendizado por reforço para ajustar modelos
Em vez de exigir dados de saída anotados por humanos, a ideia central na TAO é usar o compute em tempo de teste para que um modelo explore respostas plausíveis para uma tarefa e, depois, usar o aprendizado por reforço para atualizar um LLM com base na avaliação dessas respostas. Esse pipeline pode ser dimensionado usando o compute em tempo de teste, em vez de um esforço humano dispendioso, para aumentar a qualidade. Além disso, ele pode ser facilmente personalizado usando percepções específicas da tarefa (por exemplo, regras personalizadas). Surpreendentemente, a aplicação desse dimensionamento com modelos de código aberto de alta qualidade leva a melhores resultados do que os rótulos humanos em muitos casos.

Especificamente, a TAO compreende quatro etapas:
- Geração de respostas: essa etapa começa com a coleta de exemplos de prompts de entrada ou queries para uma tarefa. No Databricks, esses prompts podem ser coletados automaticamente de qualquer aplicativo de AI usando nosso AI Gateway. Cada prompt é então usado para gerar um conjunto diversificado de respostas candidatas. Pode-se aplicar um rico espectro de estratégias de geração, de simples encadeamento de pensamento até raciocínio sofisticado e técnicas de estímulo estruturado.
- Pontuação das respostas: nessa etapa, as respostas geradas são avaliadas sistematicamente. As metodologias de pontuação incluem uma variedade de estratégias, como modelagem de recompensas, pontuação baseada em preferências ou verificação específica de tarefas usando juízes do LLM ou regras personalizadas. Essa etapa garante que cada resposta gerada seja avaliada quantitativamente quanto à qualidade e ao alinhamento com os critérios.
- Treinamento de aprendizado por reforço (RL): na etapa final, aplica-se uma abordagem baseada em RL para atualizar o LLM, orientando o modelo a produzir resultados estreitamente alinhados com as respostas de alta pontuação identificadas na etapa anterior. Por meio desse processo de aprendizado adaptativo, o modelo refina suas previsões para melhorar a qualidade.
- Melhoria contínua: os únicos dados de que a TAO precisa são exemplos de entradas do LLM. Os usuários criam esses dados naturalmente ao interagir com um LLM. Assim que seu LLM for implantado, você começará a gerar dados de treinamento para a próxima rodada da TAO. No Databricks, seu LLM pode ficar melhor quanto mais você o usar, graças à TAO.
Fundamentalmente, embora use compute em tempo de teste, a TAO o usa para treinar um modelo que, depois, executa uma tarefa diretamente com baixos custos de inferência. Isso significa que os modelos produzidos pela TAO têm o mesmo custo e velocidade de inferência do modelo original, significativamente menos do que os modelos de compute em tempo de teste, como o1, o3 e R1. Como mostram nossos resultados, modelos eficientes de código aberto treinados com TAO podem desafiar os principais modelos proprietários em termos de qualidade.
A TAO oferece um novo método avançado no kit de ferramentas para ajustar modelos de AI. Ao contrário da engenharia de prompt, que é lenta e propensa a erros, e do ajuste fino, que requer a produção de rótulos humanos caros e de alta qualidade, a TAO permite que os engenheiros de AI obtenham ótimos resultados simplesmente fornecendo exemplos representativos de sua tarefa.
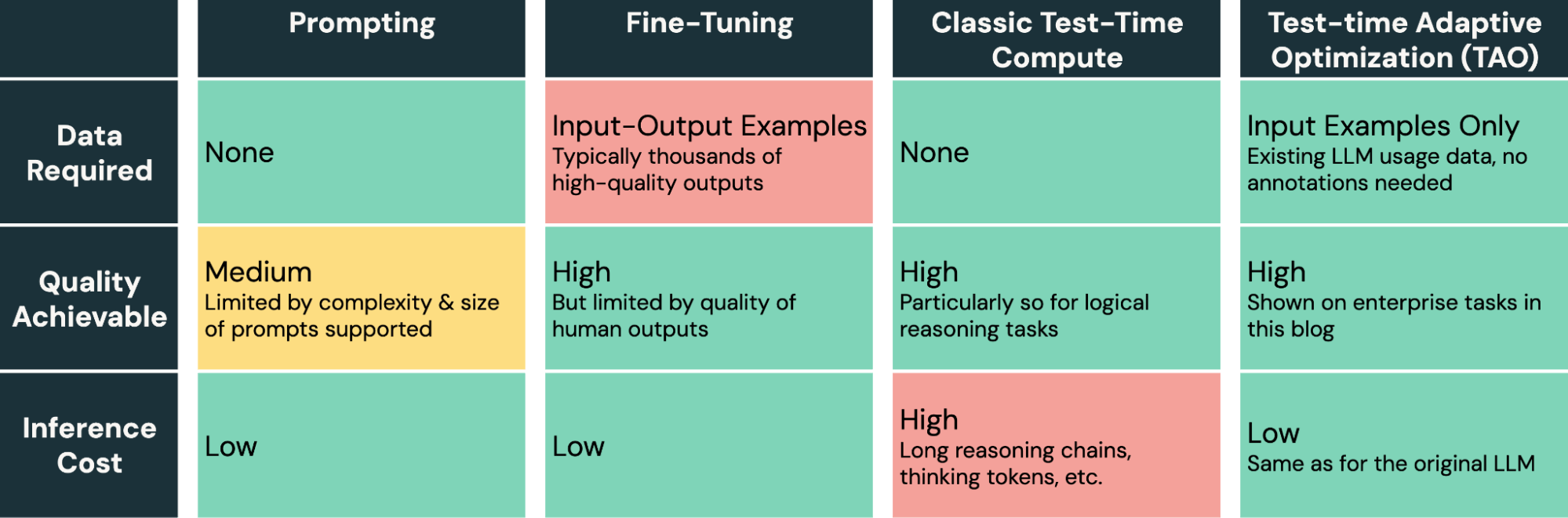
A TAO é um método altamente flexível que pode ser personalizado se necessário, mas nossa implementação default no Databricks funciona bem imediatamente em diversas tarefas corporativas. No centro da implementação estão novas técnicas de aprendizado por reforço e modelagem de recompensas que nossa equipe desenvolveu para permitir que a TAO aprenda por meio da exploração e, em seguida, ajuste o modelo subjacente usando RL. Por exemplo, um dos ingredientes que alimentam a TAO é um modelo de recompensa personalizado que treinamos para tarefas corporativas, o DBRM, que pode produzir sinais de pontuação precisos em uma ampla gama de tarefas.
Melhorando o desempenho de tarefas com TAO
Nesta seção, vamos nos aprofundar em como usamos a TAO para ajustar os LLMs em tarefas corporativas especializadas. Selecionamos três benchmarks representativos, incluindo benchmarks populares de código aberto e benchmarks internos que desenvolvemos como parte do nosso Domain Intelligence Benchmark Suite (DIBS).

Para cada tarefa, avaliamos várias abordagens:
- Usando um modelo Llama de código aberto (Llama 3.1-8B ou Llama 3.3-70B) pronto para uso.
- Ajuste fino no Llama. Para fazer isso, usamos ou criamos grandes datasets de entrada-saída realistas com milhares de exemplos, o que geralmente é necessário para obter um bom desempenho com o ajuste fino. Isso inclui:
- 7.200 perguntas sintéticas sobre documentos da SEC para o FinanceBench.
- 4.800 entradas escritas por humanos para o DB Enterprise Arena.
- 8137 exemplos do conjunto de treinamento BIRD-SQL, modificados para corresponder ao dialeto Databricks SQL.
- TAO em Llama, usando apenas os exemplos de entradas dos nossos datasets de ajuste fino, mas não as saídas, e usando nosso modelo de recompensa DBRM com foco corporativo. O DBRM em si não é treinado nesses benchmarks.
- LLMs proprietários de alta qualidade: GPT-4o-mini, GPT-4o e o3-mini.
Conforme mostrado na Tabela 3, em todos os três benchmarks e em ambos os modelos Llama, a TAO melhora significativamente o desempenho básico do Llama, mesmo além do ajuste fino.

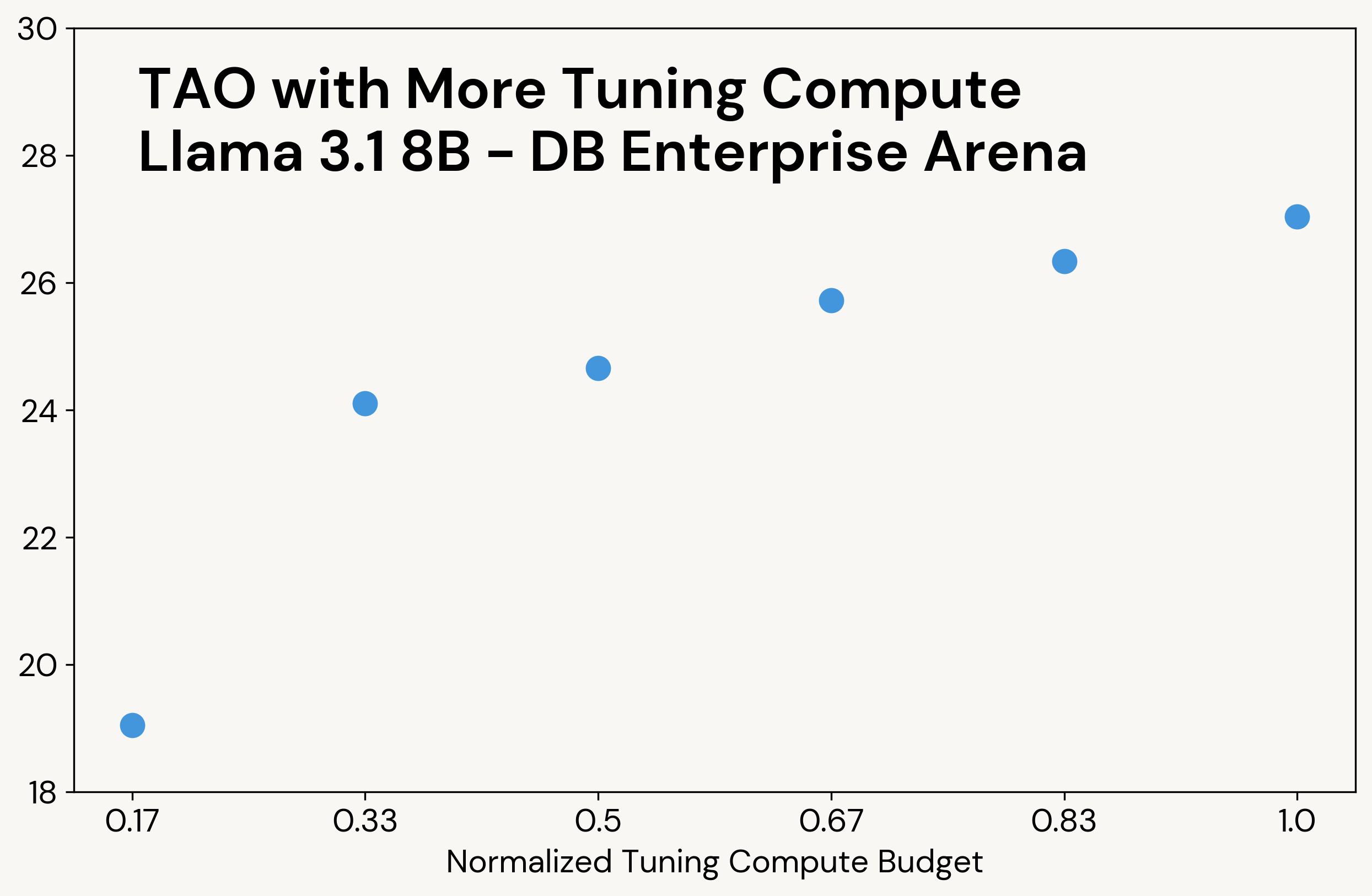
Como o compute clássico em tempo de teste, a TAO produz resultados de maior qualidade quando recebe acesso a mais compute (consulte a Figura 3 para ver um exemplo). No entanto, ao contrário do compute em tempo de teste, esse compute adicional é usado apenas durante a fase de ajuste. O LLM final tem o mesmo custo de inferência que o LLM original. Por exemplo, o o3-mini produz 5 a 10 vezes mais tokens de saída do que os outros modelos em nossas tarefas, resultando em um custo de inferência proporcionalmente maior, enquanto a TAO tem o mesmo custo de inferência do modelo Llama original.
Melhorando a inteligência multitarefa com TAO
Até agora, usamos a TAO para melhorar os LLMs em tarefas restritas individuais, como a geração de SQL. No entanto, à medida que os agentes se tornam mais complexos, as empresas precisam cada vez mais de LLMs que possam executar mais de uma tarefa. Nesta seção, mostramos como a TAO pode melhorar amplamente o desempenho do modelo em uma variedade de tarefas corporativas.
Nesse experimento, reunimos 175.000 prompts que refletem um conjunto diversificado de tarefas corporativas, incluindo programação, matemática, respostas a perguntas, compreensão de documentos e bate-papo. Em seguida, executamos a TAO no Llama 3.1 70B e no Llama 3.3 70B. Por fim, testamos um conjunto de tarefas relevantes para a empresa, que inclui benchmarks LLM populares (por exemplo, Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) e benchmarks internos em diversas áreas relevantes para empresas.
A TAO melhora significativamente o desempenho de ambos os modelos[t][u]. O Llama 3.3 70B e o Llama 3.1 70B melhoram em 2,4 e 4,0 pontos percentuais, respectivamente. A TAO aproxima significativamente o Llama 3.3 70B do GPT-4o em tarefas corporativas[v][w]. Tudo isso é alcançado sem custo de rotulagem humana, apenas dados representativos de uso do LLM e nossa implementação de produção da TAO. A qualidade melhora em todas as subpontuações, exceto na programação, em que o desempenho é estático.
Uso da TAO na prática
A TAO é um método de ajuste poderoso que funciona surpreendentemente bem em muitas tarefas, aproveitando o compute em tempo de teste. Para usá-lo com sucesso em suas próprias tarefas, você precisará:
- Exemplos suficientes de entradas para sua tarefa (na casa dos milhares), coletadas de um aplicativo de AI implantado (por exemplo, perguntas enviadas a um agente) ou geradas sinteticamente.
- Um método de pontuação suficientemente preciso: para clientes Databricks, uma ferramenta poderosa aqui é nosso modelo de recompensa personalizado, o DBRM, que impulsiona nossa implementação da TAO, mas você pode aumentar o DBRM com regras ou verificadores de pontuação personalizados, se eles forem aplicáveis à sua tarefa.
Uma prática recomendada que habilitará a TAO e outros métodos de aprimoramento de modelos é criar um volante de dados para seus aplicativos de AI. Assim que você implanta um aplicativo de AI, pode coletar entradas, saídas de modelos e outros eventos por meio de serviços como as tabelas de inferência do Databricks. Você pode então usar apenas as entradas para executar a TAO. Quanto mais pessoas usarem seu aplicativo, mais dados você terá para ajustá-lo e, graças à TAO, melhor será seu LLM.
Conclusão e introdução ao Databricks
Neste blog, apresentamos a Otimização Adaptativa em Tempo de Teste (TAO), uma nova técnica de ajuste de modelo que alcança resultados de alta qualidade sem a necessidade de dados rotulados. Desenvolvemos a TAO para enfrentar um dos principais desafios que percebemos em clientes corporativos: eles não tinham os dados rotulados necessários para o ajuste fino padrão. A TAO usa compute em tempo de teste e aprendizado por reforço para melhorar os modelos usando dados que as empresas já têm, como exemplos de entrada, facilitando a melhoria da qualidade de qualquer aplicativo de AI implantado e a redução de custos usando modelos menores. A TAO é um método altamente flexível que mostra o poder do compute em tempo de teste para o desenvolvimento especializado de AI, e acreditamos que ela fornecerá aos desenvolvedores uma nova ferramenta poderosa e simples para usar com a solicitação e o ajuste fino.
Os clientes Databricks já estão usando a TAO no Llama em uma pré-visualização privada. Preencha este formulário para demonstrar interesse em testá-la em suas tarefas como parte da pré-visualização privada. A TAO também está sendo incorporada em muitas de nossas próximas atualizações e lançamentos de produtos AI. Fique ligado!
¹ Autores: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, José Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² Usamos o3-mini-medium em todo este blog.
³ Este é o benchmark BIRD-SQL modificado para o dialeto e os produtos SQL da Databricks.