data warehouse

Che cos'è un data warehouse?
Un data warehouse è un sistema di gestione dei dati pensato per le aziende che archivia dati attuali e storici provenienti da più fonti in modo semplice e intuitivo, facilitando la generazione di report e insight. I data warehouse sono solitamente utilizzati per la Business Intelligence (BI), le analitiche, la reportistica, le applicazioni di dati e la preparazione dei dati per il machine learning (ML) e l'analisi.
Consentono di analizzare in modo rapido e semplice dati aziendali caricati da sistemi operazionali quali i sistemi POS, i sistemi di gestione dell'inventario o i database di marketing o vendita. I dati possono passare attraverso un ODS (archivio dati operazionale) ed essere sottoposti a un processo di pulizia per garantirne la qualità prima di essere utilizzati per la generazione di report nel data warehouse.
Here’s more to explore


A cosa servono i data warehouse?
I data warehouse sono utilizzati nella BI, nella reportistica e nell'analisi dei dati per estrarre e riassumere informazioni dai database operazionali. Consentono di ricavare anche informazioni difficili da ottenere direttamente dai database transazionali. Immaginiamo, ad esempio, che la direzione voglia conoscere il fatturato totale generato da ciascun venditore su base mensile per ogni categoria di prodotto. Un database transazionale potrebbe non riuscire a estrarre questa informazione, che è invece accessibile in un data warehouse.
Quanti tipi di data warehouse esistono?
- Data warehouse tradizionale: questo tipo di data warehouse memorizza solo dati strutturati. La struttura di un data warehouse consente agli utenti di accedere rapidamente e facilmente ai dati per la reportistica e l'analisi.
- Data warehouse intelligente: si tratta di un tipo nuovo di data warehouse basato su un'architettura lakehouse e dotato di una piattaforma intelligente in grado di ottimizzarsi automaticamente. Un data warehouse intelligente non solo fornisce l'accesso ai modelli di AI e ML, ma utilizza l'AI anche per facilitare le query, creare dashboard e ottimizzare le prestazioni e le dimensioni.
Architettura del data warehouse
Un modello comune per l'architettura di data warehousing è quello a più livelli. Questa architettura è stata creata da Bill Inmon, l'informatico da molti considerato il padre del data warehouse.
Livello inferiore
Il livello inferiore di un'architettura di data warehouse è costituito da sorgenti e archivi di dati. Questo livello include metodi di accesso ai dati, come esempio API, gateway, ODBC, JDBC e OLE-DB, e anche l'acquisizione dei dati o l'ETL.
Livello intermedio
Il livello intermedio è costituito da un server OLAP, che può essere relazionale (ROLAP) o multidimensionale (MOLAP). Questi due tipi possono essere combinati in un OLAP ibrido (HOLAP).
Livello superiore
Il livello superiore di un'architettura di data warehouse è costituito dai client front-end per l'esecuzione di query, la BI, la creazione di dashboard, la reportistica e l'analisi.
Quali sono le tre possibili varianti di data warehouse?
- Data warehouse aziendale (EDW): un data warehouse centralizzato utilizzato da vari team all'interno di un'organizzazione. Spesso è l'unica fonte di verità per la BI, le analitiche e la reportistica.
- Archivio dati operazionale (ODS): un tipo di data warehouse che si concentra sui dati operativi o sulle transazionali più recenti.
- Data mart: una versione semplificata del data warehouse al servizio di una singola linea di business (LOB) o di un singolo progetto. Un data mart è più piccolo di un data warehouse aziendale, ma il numero di data mart in genere aumenta via via che l'organizzazione si espande e le varie linee di business vogliono operare autonomamente sui dati.
Differenze tra data lake, database e data warehouse
Qual è la differenza tra un data lake e un data warehouse?
Data lake e data warehouse riflettono due approcci diversi alla gestione e all'archiviazione dei dati.
Un data lake è un repository di dati non strutturati o semi-strutturati che consente di archiviare grandi quantità di dati grezzi nel loro formato originale. I data lake sono progettati per acquisire e memorizzare tutti i tipi di dati, strutturati, semi-strutturati o non strutturati, senza alcuno schema predefinito. I dati sono spesso archiviati nel loro formato nativo e non vengono puliti, trasformati o integrati, il che semplifica l'archiviazione e l'accesso a grandi quantità di dati.
Un data warehouse tradizionale, invece, è un repository strutturato che memorizza dati provenienti da varie fonti in modo ben organizzato, con l'obiettivo di fornire un'unica fonte di verità per Business Intelligence e analisi. I dati vengono puliti, trasformati e integrati in uno schema ottimizzato per l'interrogazione e l'analisi.
Anche un data warehouse intelligente, che utilizza l'architettura lakehouse, fornisce un'unica fonte di verità per Business Intelligence e le analitiche. A differenza di un data warehouse tradizionale, però, oltre ai dati strutturati può memorizzare anche quelli semi-strutturati o non strutturati. Include inoltre funzionalità di gestione, ad esempio della qualità dei dati e degli avvisi di soglia.
Qual è la differenza tra un data warehouse e un database?
Un database è una raccolta di dati strutturati, che include testi e numeri ma anche immagini, video e altro. Molti si riferiscono a questo sistema di gestione di basi di dati con il suo acronimo, "DBMS". Un DBMS è il sistema di archiviazione dei dati che alimenta applicazioni e analisi.
Un data warehouse tradizionale, invece, è un repository strutturato che fornisce dati per la Business Intelligence e le analitiche. I dati vengono puliti, trasformati e integrati in uno schema ottimizzato per l'interrogazione e l'analisi, con l'aggiunta di aggregazioni comuni.
Qual è la differenza tra un data lake, un data warehouse e un data lakehouse?
Un data lakehouse è un approccio ibrido che combina il meglio delle due soluzioni. Si tratta di una moderna architettura di dati che integra le funzionalità di un data warehouse tradizionale e di un data lake in una piattaforma unificata. Consente l'archiviazione di dati grezzi nel loro formato originale, come un data lake, e fornisce al contempo funzionalità di elaborazione e analisi, come un data warehouse.
In sintesi, la differenza principale tra un data lake, un data warehouse tradizionale e un data lakehouse è l'approccio alla gestione e all'archiviazione dei dati. Un data warehouse tradizionale archivia i dati strutturati in uno schema predefinito, un data lake archivia i dati grezzi nel loro formato originale, mentre un data lakehouse è un approccio ibrido che combina le funzionalità di entrambi.
Data lake | Data lakehouse | Data warehouse tradizionale | |
|---|---|---|---|
Tipi di dati | Tutti i tipi: dati strutturati, semi-strutturati, non strutturati (grezzi) | Tutti i tipi: dati strutturati, semi-strutturati, non strutturati (grezzi) | Solo dati strutturati |
Costo | $ | $ | $$$ |
Formato | Formato aperto | Formato aperto | Formato chiuso e proprietario |
Scalabilità | Può espandersi per contenere, a basso costo, qualsiasi quantità di dati, indipendentemente dalla tipologia | Può espandersi per contenere, a basso costo, qualsiasi quantità di dati, indipendentemente dalla tipologia | L'espansione diventa esponenzialmente più costosa a causa dei costi dei fornitori |
Utenza prevista | Limitata: data scientist | Unificata: analisti di dati, data scientist, ingegneri di machine learning | Limitata: analisti di dati |
Affidabilità | Qualità bassa, paludi di dati | Qualità elevata, dati affidabili | Qualità elevata, dati affidabili |
Facilità d'uso | Difficile: l'esplorazione di grandi quantità di dati grezzi può risultare difficile in assenza di strumenti per organizzarli e catalogarli. | Semplice: combina la semplicità e la struttura di un data warehouse con la casistica d'uso più ampia di un data lake. | Semplice: la struttura di un data warehouse consente agli utenti di accedere rapidamente e facilmente ai dati per la reportistica e l'analisi. |
Prestazioni | Basse | Elevate | Elevate |
Un data lake può sostituire un data warehouse?
Non proprio. Data lake e data warehouse sono due approcci diversi alla gestione e all'archiviazione dei dati, ciascuno con i propri punti di forza e le proprie debolezze. Sebbene un data lake possa integrare un data warehouse fornendo dati grezzi per analitiche avanzate, non può sostituirlo completamente nelle sue funzioni tradizionali. Un data lake e un data warehouse possono invece completarsi a vicenda: in questo caso, il data lake fungerà da fonte di dati grezzi per analitiche avanzate, mentre il data warehouse fornirà una fonte strutturata, organizzata e affidabile di dati aziendali per il reporting e l'analisi.
Un data lake costituisce la base di un data lakehouse, che può sostituire un data warehouse tradizionale garantendo affidabilità e prestazioni elevate su formati di dati aperti, come Delta Lake e Apache Iceberg™.
Un data lakehouse può sostituire un data warehouse tradizionale?
Sì. Un data lakehouse è una moderna architettura di dati che combina i vantaggi di un data warehouse e di un data lake in una piattaforma unificata. Un data lakehouse è costruito su un open data lake e può sostituire un data warehouse tradizionale perché combina in una singola piattaforma le funzionalità di un data lake e di un data warehouse.
Un data lakehouse consente l'archiviazione di dati grezzi nel loro formato originale, come un data lake, e fornisce al contempo funzionalità di elaborazione e analisi dei dati, come un data warehouse. Inoltre, opera secondo un approccio di tipo "schema-on-read", che consente una certa flessibilità nell'elaborazione e nell'interrogazione dei dati. La combinazione di un data lake e di un data warehouse in un'unica piattaforma rappresenta una soluzione più flessibile, scalabile ed economicamente vantaggiosa.
Che cosa si intende per data warehouse moderno?
Il data warehousing si evolve continuamente. Un data warehouse moderno è definito anche "intelligente" perché utilizza tecnologie più avanzate, come l'AI. Un data warehouse intelligente sfrutta l'architettura open data del lakehouse anziché quella del data warehouse tradizionale. Un data warehouse intelligente comprende l'unicità dei dati e ottimizza automaticamente la piattaforma, scalando in modo da garantire bassa latenza e alta concorrenza. Necessita anche di una governance unificata per la sicurezza, i controlli e il flusso di lavoro. Un data warehouse intelligente utilizza l'AI per generare query, correggere errori, suggerire visualizzazioni e altro.
Che cos'è l'ETL in un data warehouse?
Un data warehouse richiede dati che devono essere caricati nel data warehouse (o referenziati, con un concetto chiamato Lakehouse Federation). Il processo per estrarre i dati dai sistemi sorgente, trasformarli e caricarli nel data warehouse è chiamato ETL (Extract, Transform, Load). L'ETL viene in genere utilizzato per integrare in uno schema predefinito dati strutturati provenienti da più sorgenti.
La federazione delle query è uno stile di ETL utilizzato per eseguire query su sorgenti di dati provenienti da più origini e distribuite su più cloud. È possibile visualizzare e interrogare tutti i dati da un'unica posizione, senza doverli migrare in un sistema unificato. Questo approccio è noto anche come "virtualizzazione dei dati".
Cosa si intende per dimensione in un data warehouse?
In un data warehouse, le dimensioni vengono utilizzate per descrivere i dati con informazioni di etichettatura strutturata. Una dimensione utilizza le informazioni per filtrare, raggruppare ed etichettare: ad esempio essere costituita da entità aziendali come cliente o prodotto.
Cosa si intende per fatto in un data warehouse?
In un data warehouse, un fatto viene utilizzato per quantificare i dati con valori numerici: ad esempio può essere costituito dagli ordini dei clienti o da dati finanziari.
Cosa si intende per modellazione dimensionale in un data warehouse?
La modellazione dimensionale è una tecnica di data warehousing che organizza i dati in dimensioni e fatti: identifica i processi aziendali importanti e quindi modella il data warehouse per supportarli.
Cosa si intende per schema a stella in un data warehouse?
Uno schema a stella è un modello di dati multidimensionale utilizzato per organizzare i dati in un database in modo che siano facili da capire e da analizzare. Gli schemi a stella possono essere applicati a data warehouse, database, data mart e altri strumenti e il loro design è ottimizzato per l'interrogazione di grandi dataset.
Introdotti da Ralph Kimball negli anni Novanta, gli schemi a stella sono efficienti nel memorizzare i dati, mantenere la cronologia e aggiornare i dati riducendo la duplicazione di definizioni aziendali ripetitive, velocizzando così l'aggregazione e il filtraggio dei dati nel data warehouse.
Quali vantaggi apporta alle aziende un data warehouse?
- Consolidamento dei dati ottenuti da molte fonti diverse. Fungendo da unico punto di accesso per tutti i dati, un data warehouse elimina la necessità di collegarsi a decine o addirittura centinaia di singoli archivi di dati.
- Intelligenza storica. Un data warehouse integra dati provenienti da molte fonti per mostrare i trend nel tempo.
- Separazione dell'elaborazione analitica dai database transazionali, migliorando le prestazioni di entrambi i sistemi.
- Qualità, coerenza e accuratezza dei dati. Un data warehouse ben formato utilizza un set di semantiche standard per i dati, tra cui coerenza nelle convenzioni di denominazione, codici per i vari tipi di prodotto, lingue, valute e così via.
- Chiunque può ottenere risposte dai dati, compresi gli utenti senza competenze di SQL.
Problemi dei data warehouse
Indipendentemente dal tipo di data warehouse utilizzato, alcune criticità permangono:
- Strumenti disgiunti tra più risorse di dati e AI creano un approccio frammentato, che compromette la governance dei dati.
- Gli utenti hanno bisogno di competenze specialistiche e di formazione per scrivere query, comprendere le strutture di dati, trovare le sorgenti di dati migliori e connettersi a esse.
- Man mano che il data warehouse cresce, rallenta. Nel cloud, questo fa lievitare rapidamente le spese, aumentando i costi per il cloud computing.
Scalabilità e prestazioni
Con l'aumento dei volumi di dati, un'architettura lakehouse distribuisce le funzionalità di elaborazione, indipendentemente dall'archiviazione, con l'obiettivo di mantenere prestazioni costanti a costi ottimali. Serve una piattaforma progettata per l'elasticità, che consenta di scalare le operazioni sui dati secondo le esigenze. La scalabilità si estende a varie dimensioni:
- Serverless: la piattaforma dovrebbe consentire ai carichi di lavoro di adattarsi e ridimensionarsi in modo elastico in base alla capacità di calcolo richiesta. Questa allocazione dinamica delle risorse garantisce rapidità nell'elaborazione e l'analisi dei dati, anche durante i picchi di domanda.
- Concorrenza: la piattaforma dovrebbe sfruttare le ottimizzazioni rese possibili dall'uso di serverless compute e AI per facilitare l'elaborazione e l'interrogazione concorrenti dei dati. Ciò garantisce che più utenti e team possano svolgere attività analitiche contemporaneamente, senza vincoli di prestazioni.
- Archiviazione: la piattaforma dovrebbe integrarsi perfettamente con i data lake, facilitando l'archiviazione economica di ampi volumi di dati e garantendo al contempo la loro disponibilità e affidabilità. Dovrebbe inoltre ottimizzare l'archiviazione dei dati per migliorare le prestazioni, riducendo le spese di storage.
La scalabilità, sebbene essenziale, non può essere disgiunta dalle prestazioni. La piattaforma dovrebbe utilizzare una varietà di ottimizzazioni basate sull'AI per ottimizzare le prestazioni.
- Interrogazione ottimizzata: la piattaforma dovrebbe utilizzare tecniche di ottimizzazione basate sul machine learning per accelerare l'esecuzione delle query. Dovrebbe sfruttare l'indicizzazione automatica, la memorizzazione nella cache e il pushdown dei predicati per garantire che le query vengano elaborate in modo efficiente e restituiscano rapidamente informazioni.
- Scalabilità automatica: la piattaforma dovrebbe scalare le risorse serverless in modo intelligente, in base ai carichi di lavoro, assicurando che si paghi solo per la capacità di calcolo effettivamente usata, mantenendo al contempo prestazioni ottimali nelle query.
- Prestazioni rapide delle query: la piattaforma dovrebbe fornire prestazioni di query estremamente veloci a basso costo, tra cui acquisizione dei dati, ETL, streaming, data science e query interattive, direttamente sul data lake.
- Delta Lake: la piattaforma dovrebbe utilizzare modelli AI per risolvere le difficoltà comunemente associate all'archiviazione dei dati, consentendo di ottenere prestazioni più veloci senza dover gestire manualmente le tabelle, anche quando esse cambiano nel tempo.
- Ottimizzazione predittiva: ottimizzazione automatica dei dati per ottenere il miglior rapporto tra prestazioni e prezzo. Questa funzione apprende dai modelli di utilizzo dei dati, pianifica le ottimizzazioni più appropriate e le esegue su un'infrastruttura serverless iper-ottimizzata.
Limiti dei data warehouse tradizionali
I data warehouse tradizionali presentano un'ulteriore serie di problemi.
- Supporto limitato o assente per dati non strutturati come immagini, testo, dati IoT o framework di messaggistica come HL7, JSON e XML. I data warehouse tradizionali sono in grado di archiviare solo dati puliti e altamente strutturati, anche se, secondo le stime di Gartner, fino all'80% dei dati di un'organizzazione sono non strutturati. Le organizzazioni che vogliono utilizzare i propri dati non strutturati per sbloccare la potenza dell'AI devono trovare altre soluzioni.
- Nessun supporto per AI e machine learning: i data warehouse sono progettati e ottimizzati per i carichi di lavoro data warehouse più comuni, come reportistica storica, BI e interrogazioni; non sono mai stati progettati per supportare carichi di lavoro di machine learning.
- Solo SQL: i data warehouse non offrono in genere alcun supporto per Python o R, i linguaggi preferiti da sviluppatori di app, data scientist e ingegneri di machine learning.
- Dati duplicati: molte imprese hanno, oltre a un data lake, dei data warehouse e dei data mart strutturati per aree tematiche o unità aziendali. Ciò comporta la duplicazione dei dati, molti processi ETL ridondanti e l'assenza di una singola fonte di verità.
- Sincronizzazione difficile: la necessità di mantenere sincronizzate due copie dei dati tra il data lake e il data warehouse aggiunge complessità e fragilità difficili da gestire. La deriva dei dati può causare report incoerenti e analisi errate.
- Formati chiusi e proprietari che aumentano la dipendenza dal fornitore: la maggior parte dei data warehouse aziendali utilizza un formato di dati proprietario, piuttosto che formati basati su standard aperti e open-source. Questo aumenta la dipendenza dal fornitore, rende difficile o impossibile l'analisi dei dati con altri strumenti e complica la migrazione.
- Costi: i data warehouse commerciali richiedono il pagamento di un corrispettivo sia per l'archiviazione dei dati, sia per la loro analisi. I costi di archiviazione e di elaborazione restano quindi strettamente collegati. Separare l'elaborazione dallo stoccaggio con un data lakehouse permette di scalare entrambe le attività in modo indipendente, in base alle proprie necessità.
- Soluzioni di reportistica separate: spesso si ha la necessità di porre domande semplici ai propri dati (ad esempio: "Quali sono i ricavi delle vendite per il Q3?") senza utilizzare tutte le funzionalità di una soluzione di reporting separata.
- Formati di tabella vincolanti: serve flessibilità a livello di linee di business e casi d'uso, ma i data warehouse a volte vincolano a un particolare formato di tabella (ad esempio, Apache Iceberg).
Formati di tabella proprietari
Il formato di tabella è la tecnologia principale che porta i vantaggi dei data warehouse ai data lake, organizzando dati e metadati in modo da rappresentare lo stato di una tabella nel tempo.
I formati di tabella proprietari sono solitamente utilizzati negli ambienti cloud, in cui l'accesso efficiente a grandi set di dati è fondamentale per attività come analisi, reportistica e machine learning. Ciascun fornitore creerà formati o strutture di file per risolvere problemi specifici, come ridurre le dimensioni di archiviazione, diminuire la velocità di lettura/scrittura o aggiungere il controllo della versione.
Il formato proprietario di Databricks, Delta Lake, è un livello di gestione dei dati e di governance open source e open format che combina i vantaggi di data lake e data warehouse. Le sue caratteristiche principali includono:
- Transazioni ACID: Delta Lake consente di disporre di dati coerenti anche durante l'esecuzione di operazioni simultanee come aggiornamenti, cancellazioni e inserimenti. In questo modo i dati sono sempre aggiornati e coerenti.
- Metadati scalabili: man mano che i dataset crescono, Delta Lake scala insieme a essi e consente agli utenti di archiviare i metadati in tabelle. Diventa così più facile monitorare e condividere le modifiche.
- Applicazione di uno schema: Delta Lake garantisce che tutti i dati aderiscano a un formato specifico in una tabella.
- Compatibilità con Apache Spark™: essendo open-source, Delta Lake è compatibile con le API di Apache Spark. È possibile usare Delta Lake nelle applicazioni Spark esistenti senza modificare il codice.
Per evitare di essere vincolati all'OTF (Open Table Format) o di dover scegliere tra Delta Lake e Apache Iceberg, è possibile utilizzare un formato universale come Delta Lake UniForm.
Multicloud
Un'organizzazione può avere dati distribuiti tra due o più provider di servizi cloud per ottimizzare i costi o per soddisfare le esigenze specifiche del dataset. Ciò può creare problemi se i dati vengono gestiti su reti diverse e con schemi di archiviazione differenti.
Una moderna architettura lakehouse è in grado di gestire i dati tra più provider di servizi cloud invece di essere vincolata a un singolo sistema cloud. Ciò consente all'organizzazione di:
- Distribuire i dati: con i dati su diverse piattaforme cloud, l'azienda può trovare la gamma di servizi più adatta alle sue esigenze di budget o di conformità.
- Migliorare la resilienza: gli ambienti multicloud migliorano la disponibilità dei dati distribuendo i carichi di lavoro e i backup tra diversi provider. Questo è fondamentale nel caso in cui un servizio cloud subisse un'interruzione o un tempo di inattività imprevisto.
- Integrare i dati: un data warehouse che supporta il multicloud può anche integrare i dati provenienti da queste sorgenti in tempo reale, dando accesso a dati di qualità e a decisioni migliori.
- Soddisfare la conformità: l'architettura multicloud aiuta a soddisfare specifici requisiti legali e normativi che determinano dove debbano essere geograficamente conservati i dati o come vadano archiviati su più servizi cloud.
I problemi dei data warehouse intelligenti
I data warehouse intelligenti presentano altri tipi di sfide.
- Questo approccio moderno è ancora in evoluzione, quindi è necessario che l'organizzazione sia a sua volta disposta a far evolvere la propria strategia.
- Policy AI: l'organizzazione deve stabilire delle policy per disciplinare quali persone e sistemi possano utilizzare le funzionalità AI di un data warehouse intelligente.
Quali soluzioni offre Databricks per il data warehousing?
Databricks offre un data warehouse intelligente, Databricks SQL, basato sull'architettura open data lakehouse. Databricks SQL fa parte di una piattaforma integrata, la Data Intelligence Platform, che comprende ML, governance dei dati, flussi di lavoro e altro. Utilizzando una base aperta e unificata per tutti i tuoi dati, potrai avere sulla stessa piattaforma ML/AI, streaming, orchestrazione, ETL e analitiche in tempo reale, data warehousing, sicurezza, governance e catalogazione unificate, nonché un'archiviazione unificata dei dati che ne garantisce affidabilità e facilità di condivisione. Inoltre, dal momento che la Databricks Data Intelligence Platform si basa su un'architettura open data lakehouse, potrai archiviare tutti i dati grezzi come registri, testi, audio, video e immagini.
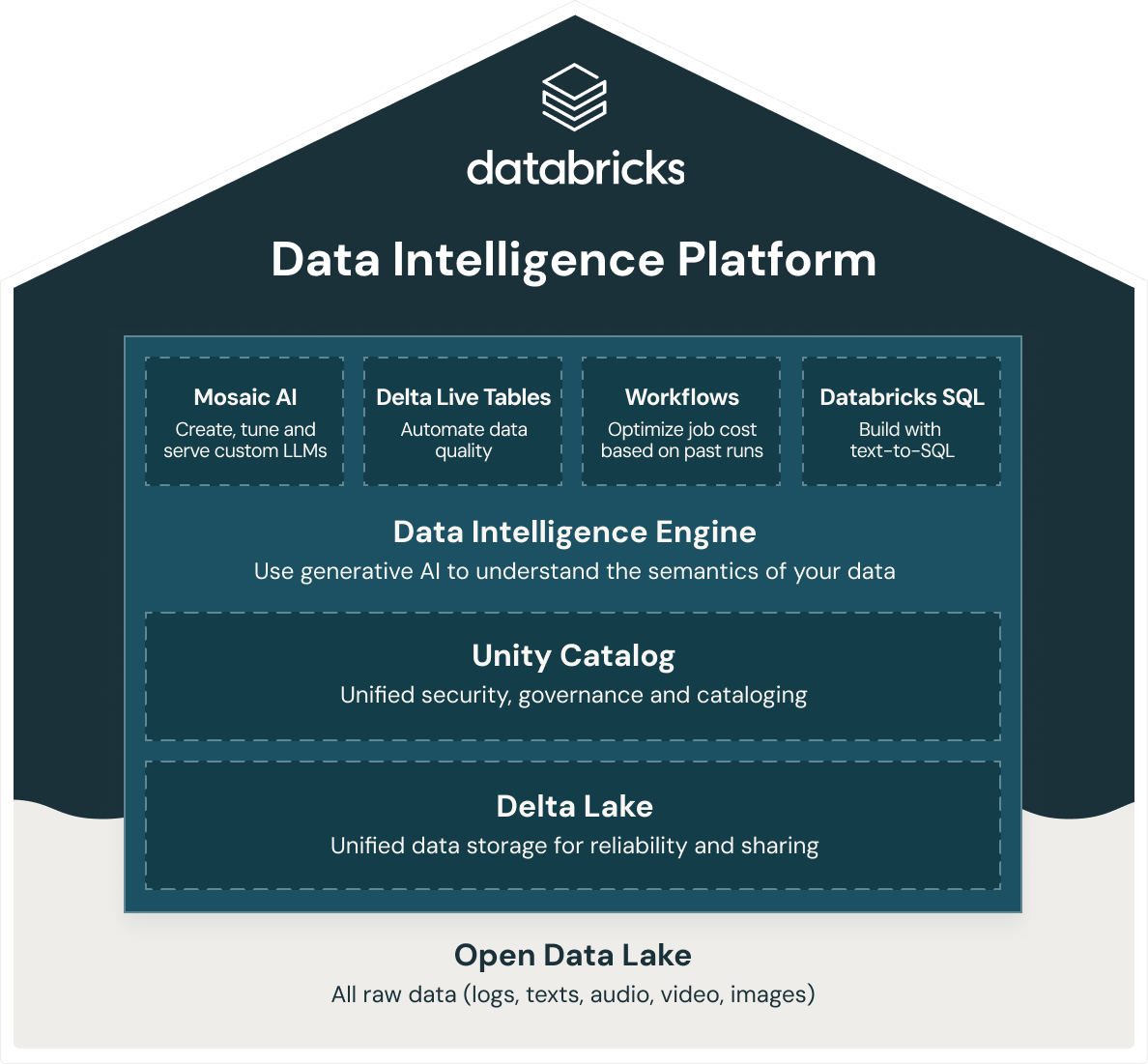
Per costruire un data lakehouse di successo, le organizzazioni si sono rivolte a Delta Lake, un layer di gestione e governance dei dati open-source e in formato aperto che combina il meglio di data lake e data warehouse. La Databricks Data Intelligence Platform utilizza Delta Lake per offrirti:
- Prestazioni di data warehouse da record al costo di un data lake.
- Elaborazione SQL serverless che elimina le necessità di gestione dell'infrastruttura.
- Integrazione perfetta con moderni stack di dati come dbt, Tableau, PowerBI e Fivetran per acquisire, interrogare e trasformare i dati in loco.
- Un'esperienza di sviluppo SQL di prim'ordine per tutti i professionisti dei dati della tua organizzazione con supporto ANSI-SQL.
- Governance granulare con provenienza dei dati, tag a livello di tabella/fila, controllo degli accessi per ruoli e tanto altro.
- Un motore di data intelligence alimentato dall'AI per comprendere la semantica dei dati.