Pregiudizio dell'automazione
Che cos'è il pregiudizio dell'automazione?
Il pregiudizio dell'automazione è un'eccessiva dipendenza dagli ausili automatizzati e dai sistemi di supporto alle decisioni. Con l'aumento della disponibilità di ausili decisionali automatizzati, si sta sempre più diffondendo il loro utilizzo in contesti decisionali critici, come le unità di terapia intensiva o le cabine di pilotaggio degli aerei. È una tendenza umana quella che porta a percorrere la strada del minor sforzo cognitivo e a propendere per il "pregiudizio dell'automazione". Lo stesso concetto può essere traslato al modo in cui funzionano AI e automazione, che si basano principalmente sull'apprendimento da grandi set di dati. Questo tipo di calcolo fa presupporre che non vi saranno radicali cambiamenti in futuro. Un altro aspetto da tenere in conto è il rischio di utilizzare dati di addestramento fallaci, che produrranno un apprendimento altrettanto fallace.
Che cos'è il pregiudizio delle macchine?
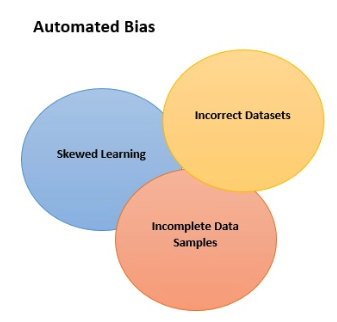
Il pregiudizio delle macchine si riferisce ai modi in cui gli algoritmi evidenziano una distorsione nell'algoritmo utilizzato per il ML o nei dati in ingresso. Oggi l'intelligenza artificiale (AI) ci aiuta a estrarre nuove, importanti informazioni dai dati e a migliorare i processi decisionali umani. Si pensi, ad esempio, alla funzione di riconoscimento facciale che utilizziamo per accedere ai nostri smartphone. I pregiudizi involontari possono derivare da molte cause (Wikipedia ne elenca 184), ma le tre principali sono:
- campioni di dati incompleti
- set di dati non corretti
- distorsione dell'apprendimento dovuta alle interazioni con gli utenti nel corso del tempo, nota anche come pregiudizio di interazione
 Possiamo evitare il data bias utilizzando un set di dati ampio e completo, che rifletta tutti i possibili casi d'uso limite; più completo è il set di dati, più precise saranno le previsioni dell'AI. Vediamo alcuni punti da considerare quando si lavora con l'intelligenza artificiale. Scegliere il modello di apprendimento più adatto al problema. Non esiste un modello unico da seguire per evitare completamente le distorsioni, ma ci sono parametri che il team può prendere in considerazione durante la sua costruzione. Occorrerà identificare il modello migliore per una determinata situazione e valutare e risolvere i potenziali problemi di un'idea prima di metterla in pratica. Scegliere un set di dati rappresentativo per l'addestramento. Bisogna assicurarsi di utilizzare dati di addestramento diversificati e che includano gruppi diversi. Monitorare le prestazioni utilizzando dati reali. Quando si costruiscono degli algoritmi, è necessario simulare il più possibile le applicazioni nel mondo reale.
Possiamo evitare il data bias utilizzando un set di dati ampio e completo, che rifletta tutti i possibili casi d'uso limite; più completo è il set di dati, più precise saranno le previsioni dell'AI. Vediamo alcuni punti da considerare quando si lavora con l'intelligenza artificiale. Scegliere il modello di apprendimento più adatto al problema. Non esiste un modello unico da seguire per evitare completamente le distorsioni, ma ci sono parametri che il team può prendere in considerazione durante la sua costruzione. Occorrerà identificare il modello migliore per una determinata situazione e valutare e risolvere i potenziali problemi di un'idea prima di metterla in pratica. Scegliere un set di dati rappresentativo per l'addestramento. Bisogna assicurarsi di utilizzare dati di addestramento diversificati e che includano gruppi diversi. Monitorare le prestazioni utilizzando dati reali. Quando si costruiscono degli algoritmi, è necessario simulare il più possibile le applicazioni nel mondo reale.