Modelli linguistici di grandi dimensioni (LLM)
Cosa sono i modelli linguistici di grandi dimensioni (LLM)?
I modelli linguistici sono un tipo di AI generativa (GenAI) che utilizzano l'elaborazione del linguaggio naturale (NLP) per comprendere e generare il linguaggio umano. I modelli linguistici di grandi dimensioni (LLM) sono i più potenti tra questi. Gli LLM vengono addestrati a partire da enormi set di dati utilizzando algoritmi avanzati di machine learning (ML) per apprendere i pattern e le strutture del linguaggio umano e generare risposte testuali a prompt scritti. Esempi di LLM includono BERT, Claude, Gemini, Llama e la famiglia di LLM Generative Pretrained Transformer (GPT).
Gli LLM hanno superato notevolmente i loro predecessori in termini di prestazioni e capacità in un'ampia gamma di attività linguistiche. La loro capacità di generare contenuti complessi e sfumati e di automatizzare le attività per ottenere risultati simili a quelli umani sta promuovendo i progressi in vari campi. Gli LLM vengono ampiamente integrati nel mondo del business per avere un impatto in svariati ambienti e per diversi usi aziendali, tra cui l'automazione dell'assistenza, l'individuazione di approfondimenti e la generazione di contenuti personalizzati.
Le funzionalità principali di AI e linguistiche degli LLM includono:
- Comprensione del linguaggio naturale: gli LLM sono in grado di comprendere le sfumature del linguaggio umano, inclusi contesto, semantica e intento.
- Generazione di contenuti multimodale: gli LLM possono produrre testo simile a quello umano per vari scopi, dalla programmazione alla scrittura creativa, così come immagini, parlato e altro ancora.
- Risposta alle domande: gli LLM possono rispondere in modo intelligente a domande aperte.
- Scalabilità: gli LLM possono sfruttare le capacità delle unità di elaborazione grafica (GPU) per svolgere in modo efficiente task linguistici su larga scala e adattarsi alle crescenti esigenze aziendali.
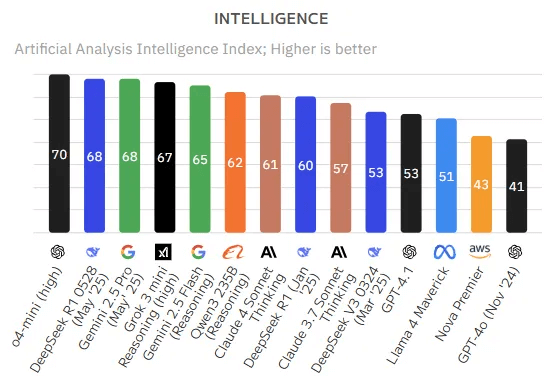
Come funzionano i LLM?
La maggior parte degli LLM utilizza un'architettura transformer. Funzionano scomponendo il testo di input in token (unità sub-parola), eseguendo l'embedding di tali token in vettori numerici e utilizzando meccanismi di attenzione per comprendere le relazioni all'interno dell'input. Prevedono quindi il token successivo in una sequenza per generare output coerenti.
Cosa significa pre-addestrare gli LLM?
Il pre-addestramento di un modello LLM si riferisce al processo di addestramento su un vasto corpus di dati, come testo o codice, senza utilizzare conoscenze pregresse o pesi di un modello esistente. Il risultato del preaddestramento completo è un modello di base che può essere utilizzato direttamente o ulteriormente ottimizzato per le attività a valle.
Il pre-addestramento garantisce che le conoscenze di base del modello siano su misura per il tuo dominio specifico. Il risultato è un modello personalizzato che si distingue per i dati esclusivi della tua organizzazione. Tuttavia, il pre-addestramento è in genere il tipo di addestramento più esteso e costoso e non è una pratica comune per la maggior parte delle organizzazioni.
Cosa significa eseguire il fine-tuning degli LLM?
L'ottimizzazione è il processo che consiste nell'adattare un LLM preaddestrato a un insieme di dati relativamente più piccolo, specifico di un settore o di un'attività. Durante il processo di ottimizzazione, l'addestramento continua per un breve periodo di tempo, eventualmente tramite la regolazione di un numero relativamente inferiore di pesi rispetto all'intero modello.
Le due forme più comuni di fine-tuning sono:
Ottimizzazione supervisionata delle istruzioni: questo approccio prevede la prosecuzione dell'addestramento di un LLM con un data set di esempi input e output, solitamente si usano migliaia di esempi.
Pre-addestramento continuo: questo metodo di fine-tuning non si basa su esempi di input e output, ma utilizza invece testo non strutturato specifico del dominio per continuare lo stesso processo di pre-addestramento (come la previsione del token successivo e il masked language modeling).
Il fine-tuning è importante perché consente a un'organizzazione di usare un LLM di base e addestrarlo con i propri dati per una maggiore accuratezza e personalizzazione per il dominio e i carichi di lavoro aziendali. Questo approccio consente inoltre di controllare i dati utilizzati per l'addestramento, assicurandosi di utilizzare l'AI in modo responsabile.
Reti neurali e architettura transformer
Gli LLM si basano sul deep learning, una forma di AI in cui grandi quantità di dati vengono fornite a un programma per addestrarlo, in base alla probabilità. Grazie all'esposizione a set di dati massicci, gli LLM possono addestrarsi a riconoscere pattern e relazioni linguistiche senza una programmazione esplicita, con meccanismi di autoapprendimento per migliorare continuamente la precisione.
La base degli LLM sono le reti neurali artificiali, ispirate alla struttura del cervello umano. Queste reti sono composte da nodi interconnessi disposti in strati, che includono uno strato di input, uno strato di output e uno o più strati intermedi. Ogni nodo elabora e trasmette le informazioni allo strato successivo in base a pattern appresi.
Gli LLM utilizzano un tipo di rete neurale chiamato modello transformer. Questi modelli rivoluzionari possono analizzare un'intera frase contemporaneamente, a differenza dei modelli precedenti che elaborano le parole in sequenza. Questo permette loro di comprendere il linguaggio in modo più rapido ed efficiente. I modelli Transformer utilizzano una tecnica matematica chiamata self-attention, che assegna un'importanza variabile alle diverse parole in una frase, consentendo al modello di cogliere le sfumature di significato e di comprendere il contesto. La codifica posizionale aiuta il modello a capire l'importanza dell'ordine delle parole all'interno di una frase, il che è essenziale per comprendere il linguaggio. Il modello Transformer consente agli LLM di elaborare enormi quantità di dati, apprendere informazioni contestualmente pertinenti e generare contenuti coerenti.
Una versione semplificata del processo di addestramento dei LLM
Ulteriori informazioni sui trasformatori, il fondamento di ogni LLM
Ecco altre informazioni utili

Il grande libro dell’AI generativa
Best practice per la creazione di applicazioni di AI generativa di qualità.

Sfrutta il potenziale dei LLM
Come aumentare l'efficienza e ridurre i costi con l'AI.
Databricks prima nelle categorie Esecuzione e Visione
2025 Gartner® Magic Quadrant™ per piattaforme di data science e machine learning
Quali sono i casi d'uso dei LLM?
I LLM possono generare un impatto sul business in numerosi casi d'uso e in diversi settori. I casi d'uso esemplificativi includono:
- Chatbot e assistenti virtuali: i LLM sono utilizzati per alimentare i chatbot e consentire a clienti e dipendenti di avere conversazioni aperte, utili per fornire assistenza ai clienti, effettuare il follow-up dei lead dei siti e offrire i servizi di un assistente personale.
- Creazione di contenuti: gli LLM possono generare diversi tipi di contenuti, come articoli, post su un blog e aggiornamenti per i social media.
- Generazione di codice e debug: i LLM possono generare utili frammenti di codice, identificare e correggere gli errori e completare programmi sulla base delle istruzioni ricevute.
- Analisi del sentiment: gli LLM possono comprendere automaticamente il sentiment di un testo per misurare la soddisfazione del cliente.
- Classificazione e clustering del testo: i LLM sono in grado di organizzare, categorizzare e ordinare grandi volumi di dati per identificare temi e tendenze comuni a supporto di un processo decisionale informato.
- Traduzione linguistica: gli LLM possono tradurre documenti e pagine web in diverse lingue per raggiungere mercati diversi.
- Riassunto e parafrasi: i LLM sono in grado di riassumere documenti, articoli, telefonate con i clienti o riunioni e di far emergere i punti più importanti.
- Sicurezza: gli LLM possono essere utilizzati nella sicurezza informatica per identificare pattern di minacce e automatizzare le risposte.
Quali sono alcuni esempi di clienti che hanno implementato in modo efficace i LLM?
JetBlue
JetBlue si è affidato alla tecnologia Databricks per implementare "BlueBot", un chatbot che utilizza modelli di AI generativa open source integrati da dati aziendali. Il chatbot può essere utilizzato da tutti i team di JetBlue per ottenere accesso ai dati in base al ruolo. Ad esempio, il team finanziario può vedere i dati del sistema SAP e i documenti normativi, mentre il team operativo vede solo le informazioni sulla manutenzione.
Chevron Phillips
Chevron Phillips sfrutta le soluzioni di AI generativa basate su modelli open-source come Dolly di Databricks per ottimizzare l'automazione dei processi documentali. Questi strumenti trasformano i dati non strutturati di PDF e manuali in informazioni dettagliate strutturate, consentendo un'estrazione dei dati più rapida e accurata per le attività operative e la market intelligence. Le policy di governance garantiscono la produttività e la gestione del rischio, mantenendo al contempo la tracciabilità.
Thrivent Financial
Thrivent Financial sta sfruttando l'AI generativa e Databricks per accelerare le ricerche, fornire approfondimenti più chiari e accessibili e aumentare la produttività dell'ingegneria. Riunendo i dati in un'unica piattaforma con una governance basata sui ruoli, l'azienda sta creando uno spazio sicuro in cui i team possono innovare, esplorare e lavorare in modo più efficiente.
Perché gli LLM stanno improvvisamente diventando popolari?
Numerosi recenti progressi tecnologici hanno portato i LLM sotto i riflettori:
- Avanzamento delle tecnologie di machine learning: gli LLM sfruttano molti progressi nelle tecniche di ML. Il più importante è l'architettura a trasformatori, che è alla base della maggior parte dei LLM.
- Maggiore accessibilità: il rilascio di ChatGPT ha aperto le porte a chiunque abbia accesso a Internet per interagire con uno degli LLM più avanzati tramite una semplice interfaccia web, consentendo al mondo di comprendere la potenza degli LLM.
- Maggiore potenza di calcolo: la disponibilità di risorse di calcolo più potenti, come le unità di elaborazione grafica (GPU) e migliori tecniche di elaborazione dei dati, ha permesso ai ricercatori di addestrare modelli molto più grandi.
- Quantità e qualità dei dati di addestramento: la disponibilità di grandi set di dati e la capacità di elaborarli hanno migliorato notevolmente le prestazioni del modello. Ad esempio, GPT-3 è stato addestrato su Big Data (circa 500 miliardi di token) che comprendevano sottoinsiemi di alta qualità, incluso il set di dati WebText2 (17 milioni di documenti) che contiene pagine web accessibili pubblicamente estratte da un crawler con un'attenzione particolare alla qualità.
Come posso personalizzare un LLM con i dati della mia organizzazione?
Ci sono quattro pattern architettonici da considerare quando si personalizza un'applicazione LLM con i dati della propria organizzazione. Le tecniche descritte di seguito non si escludono a vicenda. Al contrario, possono (e devono) essere combinate per sfruttare i punti di forza di ciascuna.
| Metodo | Definizione | Caso d'uso primario | Requisiti dei dati | Vantaggi | Considerazioni |
|---|---|---|---|---|---|
| Creazione di prompt specializzati per guidare il comportamento dei LLM | Guida rapida, in tempo reale del modello | Nessuno | Veloce, economico, non richiede addestramento | Meno controllo rispetto all'ottimizzazione | |
| Combinazione tra un LLM e il recupero di conoscenze esterne | Set di dati dinamici e conoscenze esterne | Base di conoscenza o database esterno (ad esempio, database vettoriale) | Contesto aggiornato dinamicamente, maggiore precisione | Aumenta la lunghezza dei prompt e la computazione inferenziale | |
| Adattamento di un LLM preaddestrato a set di dati o settori specifici | Specializzazione del settore o del compito | Migliaia di esempi specifici del settore o di esempi di istruzioni | Controllo granulare, alta specializzazione | Richiede dati etichettati, costo computazionale | |
| Addestramento di un LLM da zero | Compiti unici o corpora specifici del settore | Grandi set di dati (da miliardi a migliaia di miliardi di token) | Massimo controllo, adatto a esigenze specifiche | Estremamente oneroso dal punto di vista delle risorse |

Indipendentemente dalla tecnica scelta, costruire una soluzione in modo ben strutturato e modulare garantisce alle organizzazioni di essere pronte a iterare e adattarsi. Scopri di più su questo approccio e altro ancora in The Big Book of Generative AI.
Cosa si intende per ingegneria dei prompt in relazione agli LLM?
L'ingegneria dei prompt è la pratica di adattare i prompt di testo forniti a un LLM per ottenere risposte più accurate o pertinenti. Non tutti i LLM produrranno la stessa qualità, dal momento che l'ingegneria dei prompt è specifica del modello. Di seguito sono riportati alcuni consigli di carattere generale validi per una varietà di modelli:
- Utilizzare messaggi chiari e concisi, che possono includere un'istruzione, il contesto (se necessario), una domanda o un input dell'utente e una descrizione del tipo o del formato di output desiderato.
- Fornire degli esempi nel prompt (strategia del "few-shot learning") per aiutare il LLM a capire cosa si vuole.
- Istruire il modello su come comportarsi, ad esempio dicendogli di ammettere se non è in grado di rispondere a una domanda.
- Dire al modello di pensare passo dopo passo o di spiegare il suo ragionamento.
- Se il prompt include l'input dell'utente, utilizzare tecniche per prevenire l'hacking del prompt, ad esempio rendendo molto chiaro quali parti del prompt corrispondono alle tue istruzioni e quali all'input dell'utente.
Cosa significa retrieval augmented generation (RAG) in relazione agli LLM?
Generazione aumentata dal recupero, o RAG, è un approccio architetturale che può migliorare l'efficacia delle applicazioni LLM sfruttando dati personalizzati. Ciò avviene recuperando dati/documenti pertinenti a una domanda o a un compito e fornendoli come contesto per il LLM. La RAG ha dimostrato di avere successo nel supportare i chatbot e i sistemi Q&A che devono mantenere informazioni aggiornate o accedere a conoscenze specifiche del settore.
Per saperne di più sulla RAG, fai clic qui.
Quali sono i LLM più comuni e in cosa si differenziano?
Il campo degli LLM è ricco di opzioni tra cui scegliere. In generale, è possibile raggruppare i LLM in due categorie: servizi proprietari e modelli open source.
Modelli proprietari
I modelli LLM proprietari sono sviluppati e di proprietà di aziende private e in genere richiedono licenze per l'accesso. Forse l'LLM proprietario più noto è GPT-4o, che alimenta ChatGPT, rilasciato nel 2022 con grande clamore. ChatGPT offre un'interfaccia di ricerca intuitiva in cui gli utenti possono inserire prompt e ricevere una risposta rapida e pertinente. Gli sviluppatori possono accedere all'API ChatGPT per integrare questo LLM nelle proprie applicazioni, prodotti o servizi. Altri modelli proprietari includono Gemini di Google e Claude di Anthropic.
Modelli open source
Un'altra opzione è quella di implementare un LLM autonomo, in genere utilizzando un modello open source disponibile per uso commerciale. La community open source ha recuperato rapidamente terreno, raggiungendo le prestazioni dei modelli proprietari. I modelli LLM open source più diffusi includono Llama 4 di Meta e Mixtral 8x22B.
Come valutare la scelta migliore
Le considerazioni più importanti e le differenze di approccio tra l'utilizzo di un'API chiusa di un fornitore terzo e l'hosting interno del proprio LLM open source (o ottimizzato) sono la predisposizione per il futuro, la gestione dei costi e lo sfruttamento dei dati come vantaggio competitivo. I modelli proprietari possono diventare obsoleti e venire rimossi, interrompendo le pipeline e gli indici vettoriali esistenti; i modelli open source, al contrario, saranno accessibili per sempre. I modelli open source ottimizzati offrono maggiori opzioni di personalizzazione, consentendo un migliore compromesso tra prestazioni e costi. Pianificare l'ottimizzazione futura dei propri modelli permette di sfruttare i dati dell'organizzazione come vantaggio competitivo per costruire modelli migliori di quelli disponibili pubblicamente. Infine, i modelli proprietari possono sollevare problemi di governance, in quanto questi LLM "black box" consentono una minore supervisione dei processi di addestramento e dei pesi.
L'hosting dei propri LLM open source richiede più lavoro rispetto all'utilizzo di LLM proprietari. MLflow di Databricks rende più semplice, per chi ha esperienza con Python, estrarre qualsiasi modello di trasformatore e usarlo come oggetto Python.
Come faccio a scegliere quale LLM usare?
La valutazione dei LLM è una scelta impegnativa e in continua evoluzione, soprattutto perché i LLM spesso dimostrano capacità disomogenee che variano in base al task. Un LLM potrebbe eccellere in un benchmark, ma basteranno piccole variazioni nel prompt o nel problema per influenzare drasticamente le sue prestazioni.
Tra i principali strumenti e benchmark utilizzati per valutare le prestazioni di un LLM si possono ricordare:
- MLFLOW
- Fornisce una serie di strumenti LLMOps per la valutazione dei modelli.
- Mosaic Model Gauntlet
- Un approccio di valutazione aggregato, che categorizza le competenze del modello in sei vasti ambiti (illustrati di seguito) anziché estrapolare un'unica metrica monolitica.
- Hugging Face raccoglie centinaia di migliaia di modelli da contributori di LLM aperti.
- BIG-bench (Beyond the Imitation Game Benchmark)
- Un framework di benchmarking dinamico, che attualmente ospita oltre 200 task, con l'obiettivo di adattarsi alle future capacità dei LLM.
- EleutherAI LM Evaluation Harness
- Un framework olistico che valuta i modelli su oltre 200 task, combinando valutazioni come BIG-bench e MMLU e promuovendo riproducibilità e comparabilità.
Leggi anche le Best practice per la valutazione tramite LLM di applicazioni RAG.
Come si operazionalizza la gestione degli LLM tramite le large language model ops?
Large Language Model Ops (LLMOps) riguarda le pratiche, le tecniche e gli strumenti utilizzati per la gestione operativa di modelli linguistici di grandi dimensioni in ambienti di produzione.
LLMOps consente il deployment, il monitoraggio e la manutenzione efficienti degli LLM. LLMOps, come il tradizionale Machine Learning Ops (MLOps), richiede la collaborazione fra data scientist, ingegneri DevOps e informatici. Per maggiori dettagli su LLMOps, vedi qui.
Dove posso trovare maggiori informazioni sui modelli linguistici di grandi dimensioni (LLM)?
Ci sono molte risorse disponibili in cui trovare maggiori informazioni sui LLM, tra cui:
Formazione
- LLMs: Foundation Models From the Ground Up (EDX e Databricks Training) — Corso di formazione gratuito di Databricks che entra nei dettagli dei modelli di base nei LLM
- LLMs: Application Through Production (EDX e Databricks Training) — Corso di formazione gratuito di Databricks incentrato sulla costruzione di applicazioni incentrate sui LLM con i framework più recenti e più noti
eBook
- Il grande libro dell’AI generativa
- Guida compatta all'ottimizzazione e alla creazione di LLM personalizzati
- Guida sintetica ai modelli linguistici di grandi dimensioni
Blog tecnici
- Presentazione di Llama 4 di Meta sulla Databricks Data Intelligence Platform | Blog di Databricks
- Serving dei modelli Qwen su Databricks | Blog di Databricks
- Best practice per la valutazione tramite LLM di applicazioni RAG
- Using MLflow AI Gateway and Llama 2 to Build Generative AI Apps
- Crea app RAG di alta qualità con Mosaic AI Agent Framework, Agent Evaluation, Model Serving e Vector Search
- LLMOps: Everything You Need to Know to Manage LLMs
Passaggi successivi
- Contatta Databricks per programmare una demo e parlarci dei tuoi progetti di modelli linguistici di grandi dimensioni (LLM).
- Scopri le offerte di Databricks per i LLM
- Ulteriori informazioni sui casi d'uso della Retrieval Augmented Generation (RAG), l'architettura LLM più comune