LLMOps
Che cos'è LLMOps?
Large Language Model Ops (LLMOps) riguarda le pratiche, le tecniche e gli strumenti utilizzati per la gestione operativa di modelli linguistici di grandi dimensioni in ambienti di produzione.
I progressi più recenti nel campo dei modelli LLM, testimoniati da release come GPT di OpenAI, Bard di Google e Dolly di Databricks, stanno favorendo la costruzione e l'adozione di modelli LLM da parte delle imprese. È nata così la necessità di sviluppare best practice per l'operazionalizzazione di questi modelli. LLMOps consente l'implementazione, il monitoraggio e la manutenzione efficienti di modelli linguistici di grandi dimensioni. LLMOps, come il tradizionale Machine Learning Ops (MLOps), richiede la collaborazione fra data scientist, ingegneri DevOps e informatici. Per scoprire come costruire un tuo modello LLM insieme a noi, fai clic qui.
I modelli linguistici di grandi dimensioni (LLM) sono una nuova categoria di modelli di elaborazione del linguaggio naturale (NLP) che hanno fatto enormi progressi rispetto allo stato dell'arte precedente in molte attività, dalle risposte a domande aperte, ai riassunti di documenti, fino all'esecuzione di istruzioni quasi arbitrarie. I requisiti operativi di MLOps si applicano normalmente anche a LLMOps, ma esistono alcune problematiche nell'addestramento e nell'implementazione di LLM che richiedono un approccio unico a LLMOps.
Quali sono le differenze fra LLMOps e MLOps?
Al fine di adeguare le pratiche MLOps, bisogna considerare come cambiano i flussi di lavoro e i requisiti del machine learning (ML) con i modelli LLM. Le considerazioni principali sono le seguenti:
- Risorse di calcolo: Addestrare e mettere a punto modelli linguistici di grandi dimensioni comporta tipicamente l'esecuzione di calcoli su grandi set di dati con un'ordine di grandezza molto superiore alla norma. Per accelerare questo processo si utilizza hardware specializzato, come le GPU, in grado di elaborare i dati in parallelo molto più velocemente. Avere accesso a queste risorse di calcolo specializzate diventa essenziale sia per l'addestramento, sia per l'implementazione di modelli LLM. In virtù del costo dell'inferenza, sono altrettanto importanti le tecniche di compressione e distillazione dei modelli.
- Apprendimento per trasferimento: A differenza di molti modelli ML tradizionali che vengono creati o addestrati da zero, tanti modelli LLM nascono da un modello base e vengono successivamente perfezionati con nuovi dati per migliorarne le prestazioni in ambiti specifici. Questa messa a punto assicura prestazioni allo stato dell'arte per applicazioni specifiche, utilizzando meno dati e meno risorse di calcolo.
- Feedback umano: I progressi più rilevanti nell'addestramento di modelli linguistici di grandi dimensioni sono stati ottenuti grazie all'apprendimento supportato dal feedback fornito da esseri umani (RLHF). In generale, poiché i modelli LLM devono spesso svolgere compiti "aperti", il riscontro da parte degli utilizzatori finale dell'applicazione è fondamentale per valutare le prestazioni di un LLM. Integrando questo ciclo di feedback nelle pipeline LLMOps, si semplifica la valutazione e si ottengono dati per la futura ottimizzazione del modello LLM.
- Ottimizzazione degli iperparametri: Nel ML classico, la messa a punto degli iperparametri è spesso incentrata sul miglioramento della precisione o altre metriche. Per i modelli LLM, questa ottimizzazione diventa importante anche per ridurre il costo e la potenza di calcolo richiesta per addestramento e inferenza. Ad esempio, piccoli aggiustamenti alle dimensioni dei batch e alle tariffe di apprendimento possono cambiare radicalmente la velocità e i costi dell'addestramento. Quindi, sia il machine learning tradizionale, sia i modelli LLM traggono beneficio dal tracciamento e dall'ottimizzazione del processo di messa a punto, anche se in diversa misura.
- Metriche di prestazioni: I modelli ML tradizionali hanno metriche di prestazioni definite molto chiaramente, come accuratezza, AUC, punteggio F1 ecc. Queste metriche sono piuttosto semplici da calcolare. Quando si tratta di valutare modelli LLM, tuttavia, subentra una serie di metriche standard e punteggi completamente diversa, come gli algoritmi BLEU (Bilingual Evaluation Understudy) e ROGUE (Recall-Oriented Understudy for Gisting Evaluation), che richiedono ulteriori valutazioni in fase di implementazione.
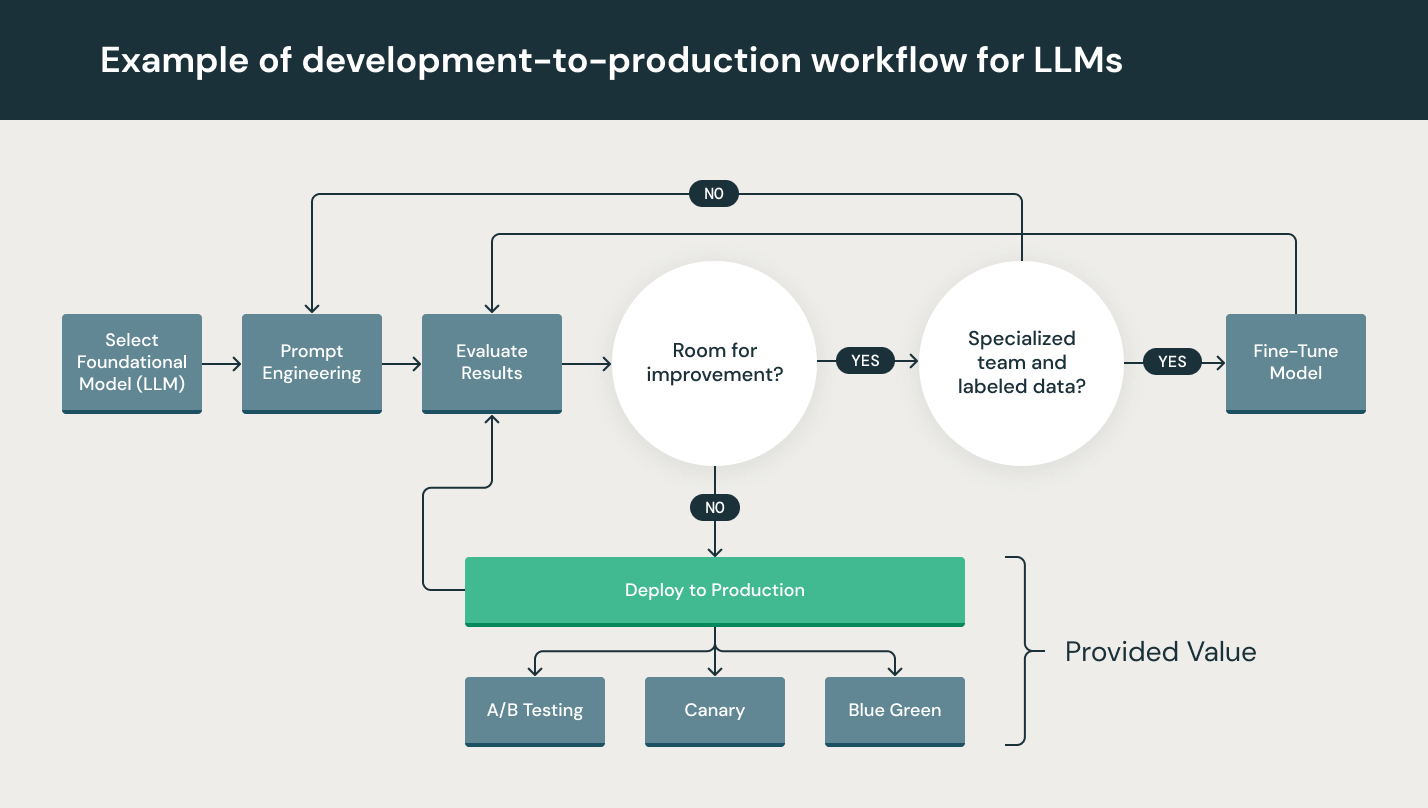
- Prompt engineering: I modelli capaci di eseguire istruzioni possono ricevere set di indicazioni (detti appunto "prompt") complessi. Progettare questi modelli di prompt è fondamentale per ottenere risposte accurate e affidabili dai LLM. Il prompt engineering può ridurre il rischio di allucinazioni dei modelli e hackeraggio delle istruzioni, ad esempio iniezione di istruzioni, perdita di dati sensibili e jailbreaking.
- Costruzione di catene o pipeline LLM: le pipeline LLM, costruite utilizzando strumenti come LangChain o LlamaIndex, legano insieme molteplici chiamate LLM e/o chiamate a sistemi esterni come database vettoriali o ricerche web. Queste pipeline consentono di utilizzare i modelli LLM per attività complesse come Q&A su basi di conoscenza o rispondere a domande degli utenti partendo da una serie di documenti. Lo sviluppo di applicazioni LLM si focalizza spesso sulla costruzione di queste pipeline, piuttosto che sulla costruzione di nuovi LLM.
Perché serve LLMOps?
Sebbene gli LLM siano particolarmente semplici da utilizzare nella prototipazione, l'utilizzo di un LLM in un prodotto commerciale presenta ancora alcune problematiche. Il ciclo di sviluppo di LLM è costituito da numerosi passaggi complessi, come acquisizione e preparazione dei dati, prompt engineering, ottimizzazione, implementazione e monitoraggio del modello, e molto altro. Richiede inoltre collaborazione e passaggi fra team, dall'ingegneria dei dati, alla data science, fino all'ingegneria ML. Serve grande rigore operativo affinché tutti questi processi restino sincronizzati e funzionino insieme. LLMOps comprende la sperimentazione, l'iterazione, l'implementazione e il miglioramento continuo del ciclo di sviluppo del modello LLM.
Quali sono i vantaggi di LLMOps?
I benefici principali di LLMOps sono efficienza, scalabilità e riduzione del rischio.
- Efficienza: LLMOps consente ai team di gestione dei dati di velocizzare lo sviluppo dei modelli e delle pipeline, realizzare modelli di qualità superiore e andare in produzione più velocemente.
- Scalabilità: LLMOps favorisce anche una scalabilità e gestione su larga scala, permettendo di supervisionare, controllare, gestire e monitorare migliaia di modelli per attività di integrazione continua, fornitura continua e implementazione continua (CI/CD). In particolare, LLMOps offre la riproducibilità delle pipeline LLM, favorendo una collaborazione più stretta fra i team di gestione dei dati, riducendo i conflitti con DevOps e IT, e accelerando i tempi di rilascio.
- Riduzione del rischio: i modelli LLM devono spesso essere sottoposti a verifiche regolatorie; LLMOps offre maggiore trasparenza e risposte più rapide a queste richieste, oltre a una maggiore conformità alle politiche di un'organizzazione o di un settore industriale.
Quali sono i componenti di LLMOps?
La portata di LLMOps nei progetti di machine learning può essere più o meno ampia a seconda delle necessità del progetto stesso. In alcuni casi, LLMOps può abbracciare tutto il percorso dalla preparazione dei dati alla produzione della pipeline, mentre altri progetti possono richiedere l'implementazione del solo processo di realizzazione del modello. La maggior parte delle imprese applica i principi LLMOps alle seguenti attività:
- Analisi esplorativa dei dati (EDA)
- Preparazione di dati e prompt engineering
- Ottimizzazione del modello
- Revisione e governance di modelli
- Inferenza di modelli e model serving
- Monitoraggio del modello con feedback umano
Quali sono le best practice per LLMOps?
Le best practice per LLMOps possono essere delineate entro la fase in cui vengono applicati i principi LLMOps.
- Analisi esplorativa dei dati (EDA): Esplora, condividi e prepara i dati in modo iterativo per il ciclo di vita del machine learning, creando set di dati, tabelle e visualizzazioni riproducibili, editabili e condivisibili.
- Preparazione dei dati e prompt engineering: Trasforma, aggrega e de-duplica i dati in modo iterativo e rendi i dati visibili e condivisibili per tutti i team di gestione dei dati. Sviluppa in modo iterativo prompt per query strutturate affidabili su LLM.
- Messa a punto dei modelli: Usa librerie open-source comuni come Hugging Face Transformers, DeepSpeed, PyTorch, TensorFlow e JAX per mettere a punto i modelli e migliorarne le prestazioni.
- Revisione e governance di modelli: Traccia la provenienza e le versioni dei modelli e delle pipeline e gestisci gli artefatti e le transizioni lungo tutto il ciclo di vita. Scopri, condividi e collabora su diversi modelli ML con l'ausilio di una piattaforma MLOps open-source come MLflow.
- Inferenza di modelli e model serving: Gestisci la frequenza di aggiornamento dei modelli, i tempi di richiesta delle inferenze e altri aspetti specifici della produzione in test e controllo di qualità. Usa strumenti CI/CD come repository e orchestratori (che attingono ai principi DevOps) per automatizzare la pipeline pre-produzione. Abilita gli endpoint del modello API REST, con accelerazione GPU.
- Monitoraggio dei modelli con feedback umano: Crea pipeline per il monitoraggio di modelli e dati, con avvisi in caso di deriva dei modelli e comportamenti malevoli degli utenti.
Che cos'è una piattaforma LLMOps?
Una piattaforma LLMOps offre a data scientist e ingegneri software un ambiente collaborativo che favorisce l'esplorazione iterativa dei dati e offre funzionalità di collaborazione in tempo reale per il tracciamento di esperimenti, il prompt engineering e la gestione di modelli e pipeline, oltre a processi controllati per la transizione, l'implementazione e il monitoraggio di modelli LLM. LLMOps automatizza gli aspetti di operatività, sincronizzazione e monitoraggio del ciclo di vita del machine learning.
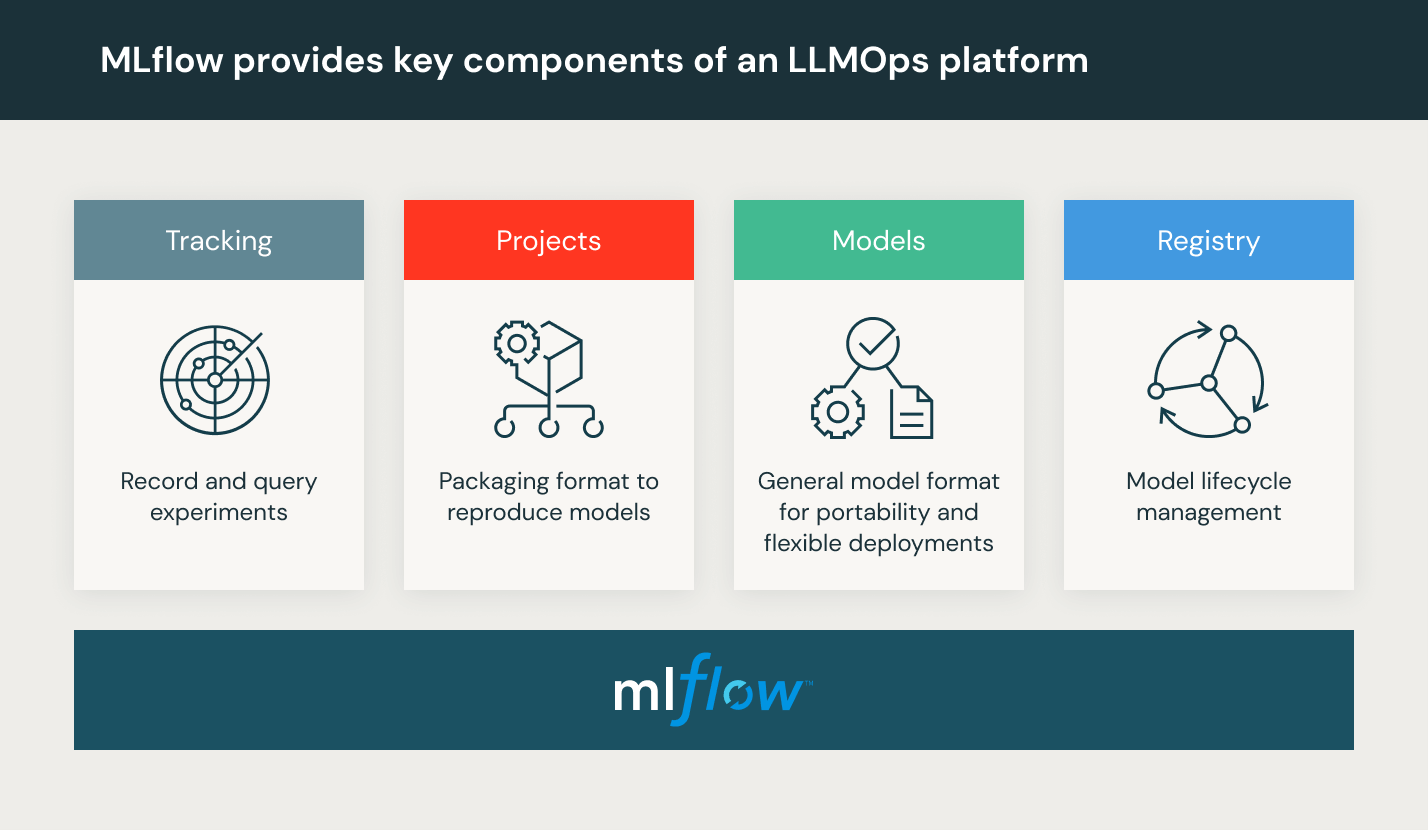
Databricks fornisce un ambiente completamente gestito che comprende MLflow, la principale piattaforma MLOps aperta a livello mondiale. Prova Databricks Machine Learning