Governance unificata e aperta per dati e AI
Elimina i silos, semplifica la governance e accelera l'accesso alle informazioni su larga scala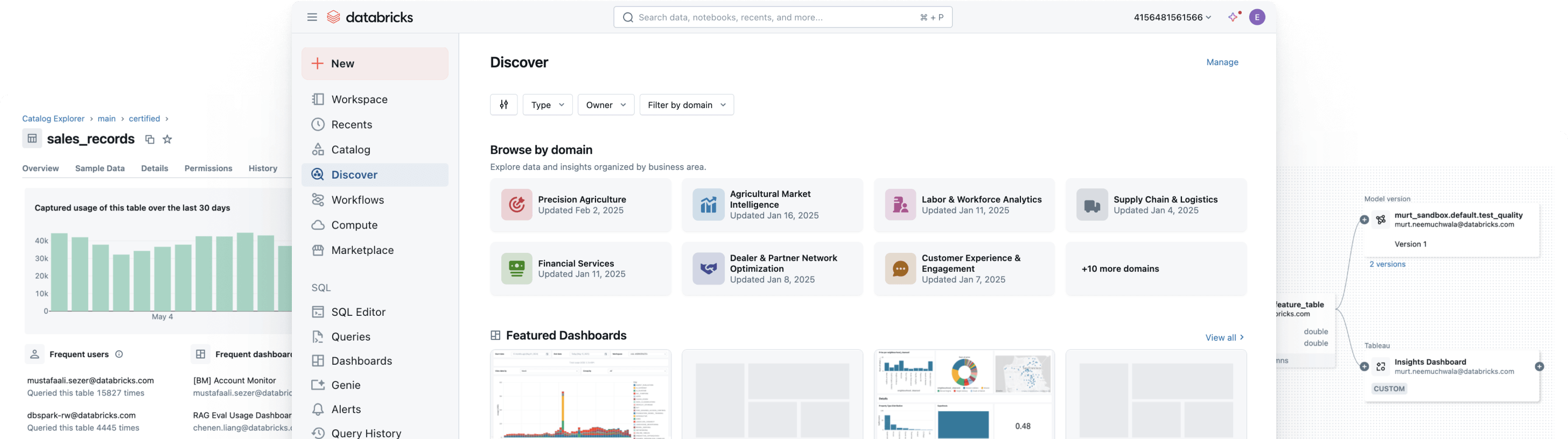
IL SUCCESSO DEI MIGLIORI TEAM POGGIA SU UNA GOVERNANCE UNIFICATA E APERTAGovernance, scoperta, monitoraggio e condivisione in un’unica soluzione
Unifica il tuo panorama di dati, semplifica la conformità e accelera l'accesso a informazioni affidabili grazie a una governance aperta e intelligente per dati e AIGovernance unificata
Applica controlli coerenti per scoperta, accesso, monitoraggio della qualità e conformità su dati strutturati e non strutturati, modelli ML e metriche di business, in qualsiasi cloud. Con una governance unificata puoi ridurre i rischi, semplificare gli audit e accelerare l’accesso ai dati senza rinunciare al controllo.
Aperta
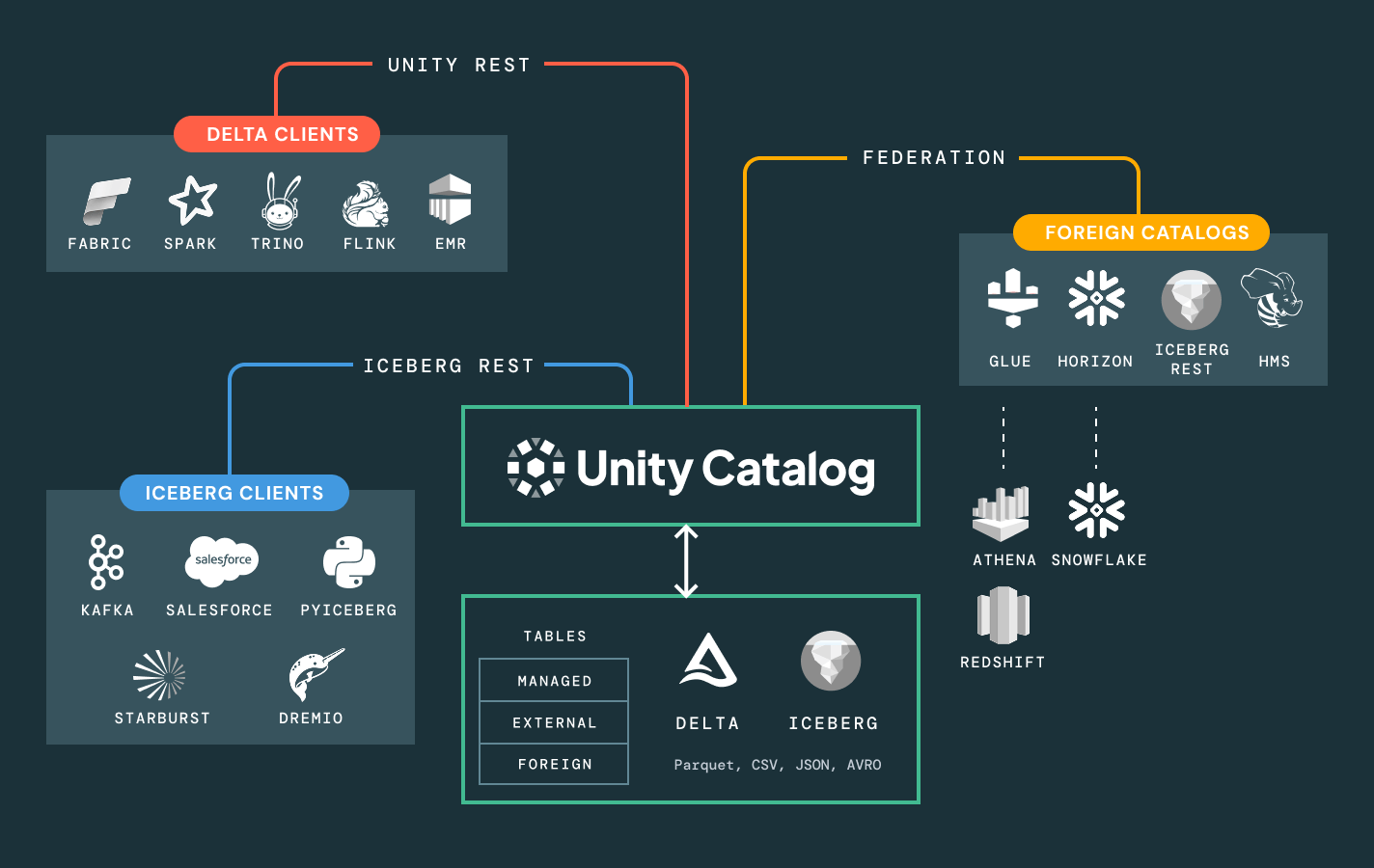
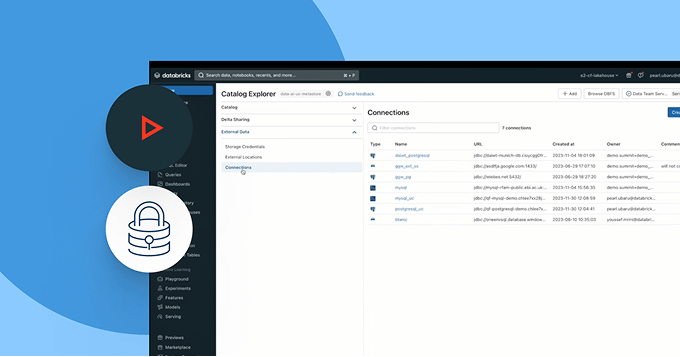
Liberati dalla dipendenza dalla piattaforma. Utilizza i formati open lakehouse di tua scelta (Delta, Apache Iceberg™, Hudi, Parquet), collega sorgenti dati esterne senza necessità di migrazione e integra i tuoi strumenti BI, AI e di catalogazione esistenti tramite API aperte. Che tu stia condividendo dati internamente o con partner esterni, rendi la collaborazione sicura, scalabile e basata su standard aperti.
Intelligenza integrata
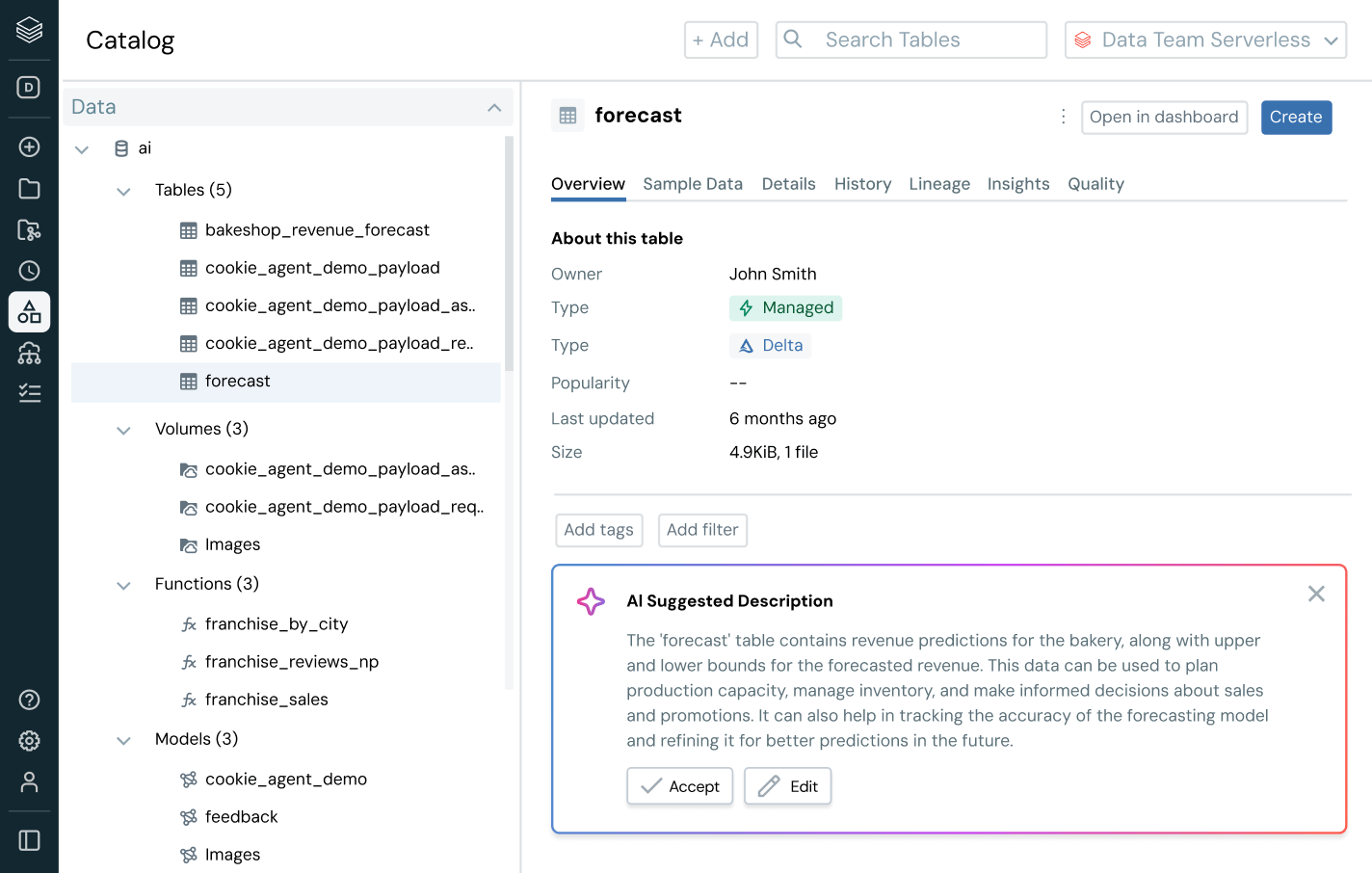
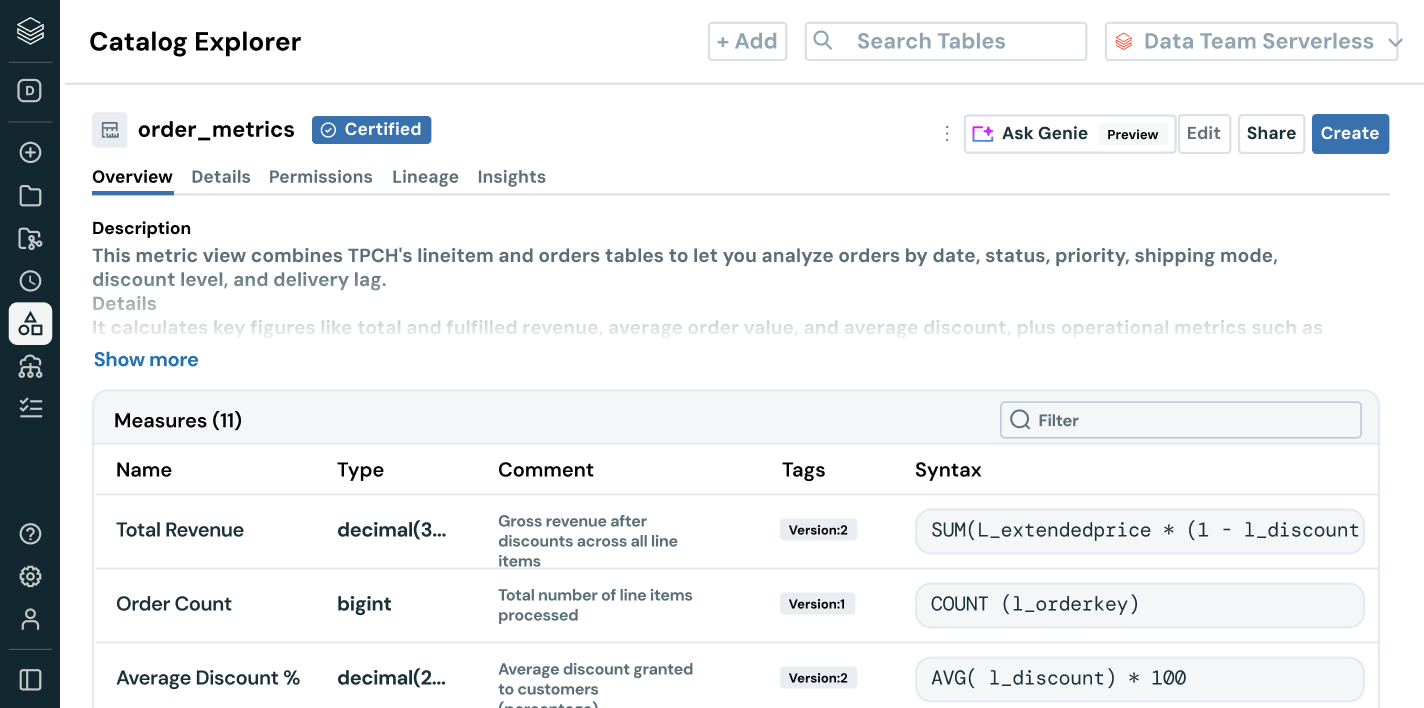
Vai oltre la scoperta dei dati e la gestione degli accessi: fornisci agli utenti il contesto aziendale. Con derivazione integrata, insight sull’utilizzo e semantiche di business, gli utenti possono trovare, comprendere ed esplorare i dati più velocemente. Documentazione basata sull'AI, ricerca in linguaggio naturale e spazi conversazionali aiutano sia gli utenti tecnici che quelli business a passare dai dati alle decisioni in modo più rapido e con un contesto aziendale completo.
Governance intelligente integrata
Semplifica la scoperta, la conformità e il monitoraggio su tutto il tuo patrimonio dati e AI con una governance intelligenteCatalogo unificato per dati strutturati, non strutturati, metriche di business e modelli di AI in formati aperti come Delta Lake, Apache Iceberg, Hudi, Parquet e altri.

Altre funzioni
Sblocca il pieno valore aziendale dei dati con una governance unificata
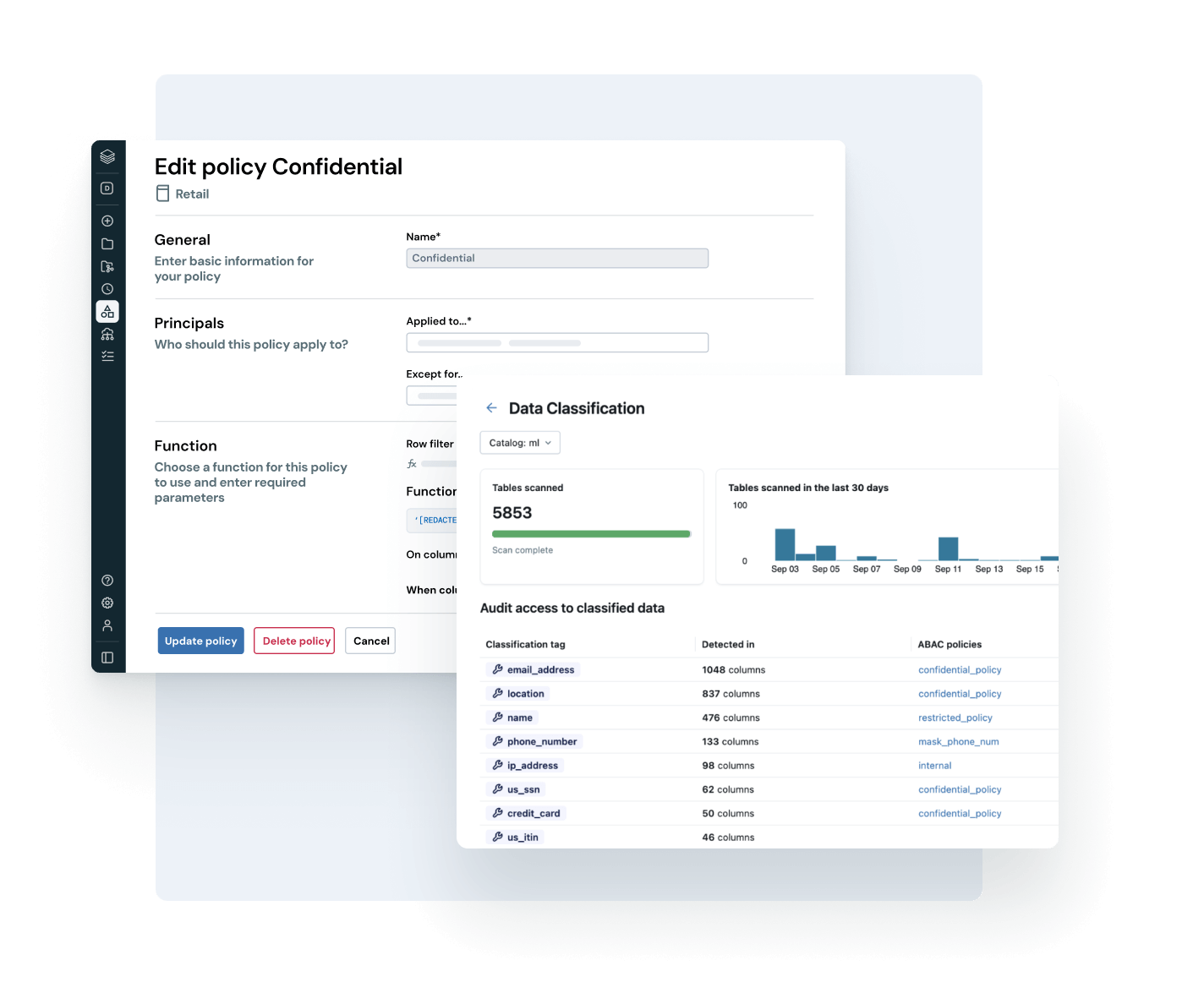
Metti ogni utente in condizione di trovare, comprendere e utilizzare i dati giusti con fiducia.
Rendi i tuoi dati più preziosi facili da trovare e comprendere, in ogni parte dell'azienda.
- La scoperta auto-curata porta in evidenza asset di dati affidabili e ad alto impatto
- Documentazione, tag e informazioni sull'utilizzo basati sull'AI aggiungono un contesto ricco
- Le semantiche di business governate garantiscono metriche coerenti e attendibili tra i diversi team e strumenti
- L'interfaccia conversazionale con AI/BI Genie aiuta gli utenti aziendali a esplorare i dati senza dover usare SQL
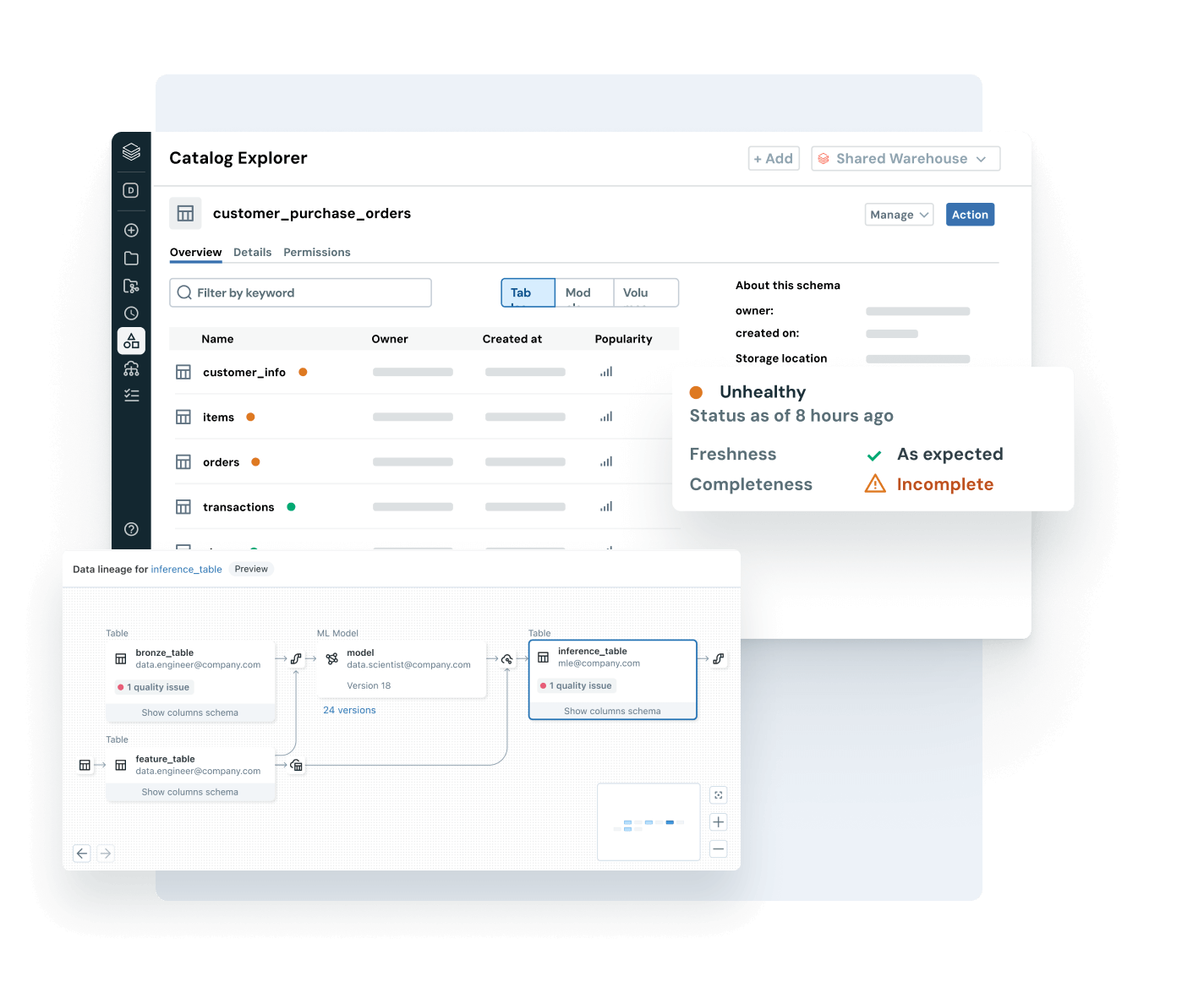
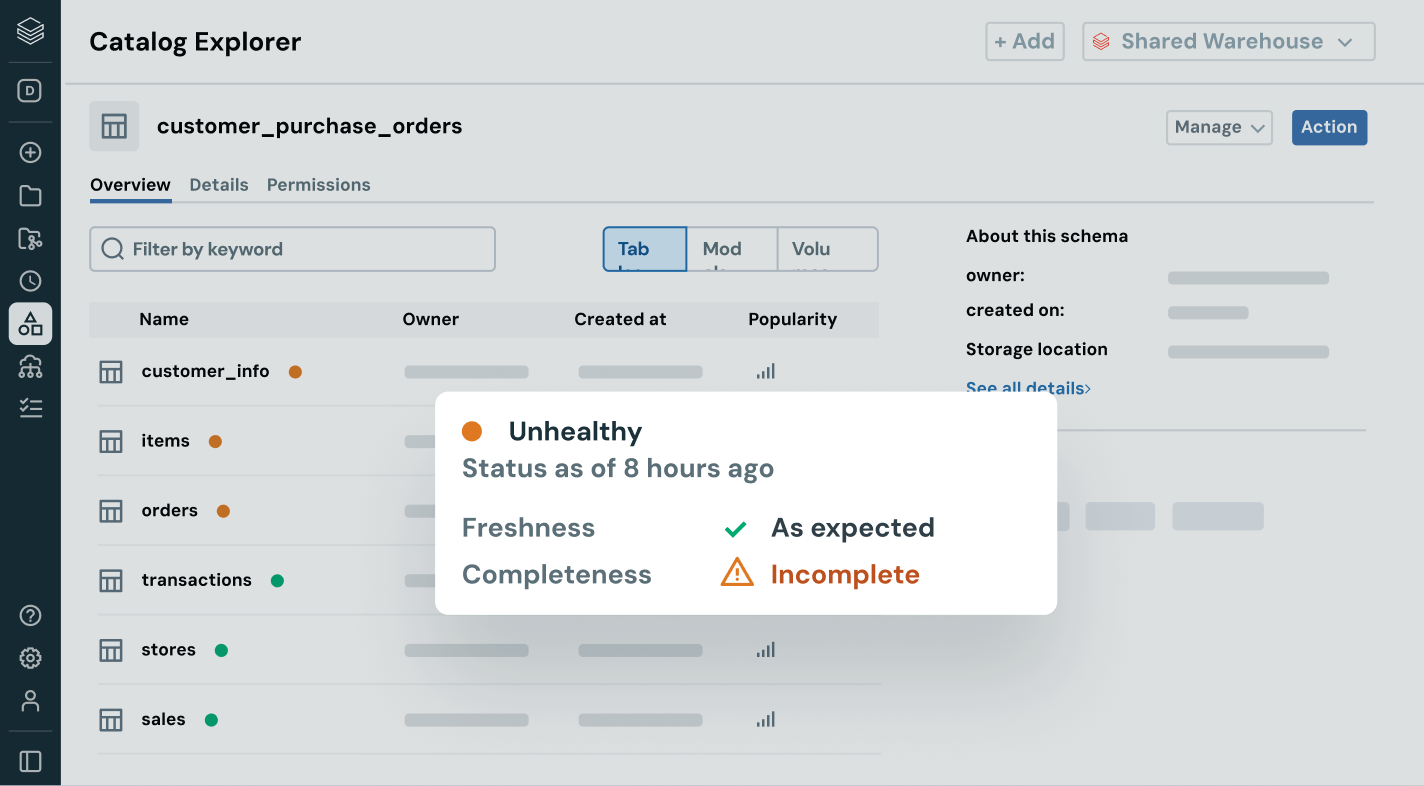
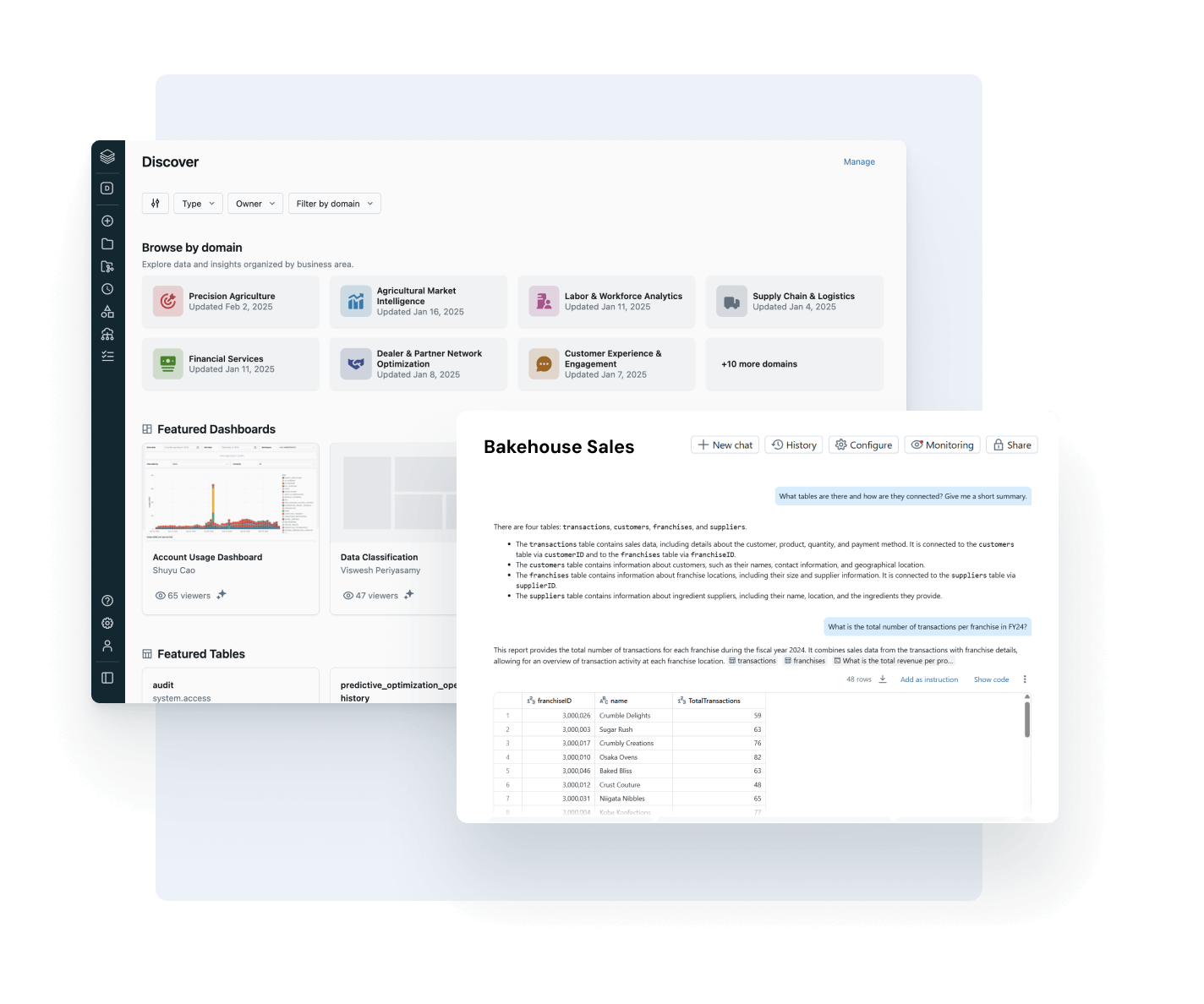
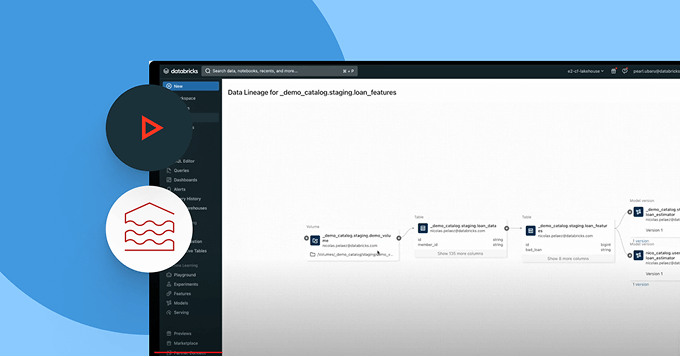
Assicurati che i dati su cui fai affidamento siano aggiornati, completi e affidabili
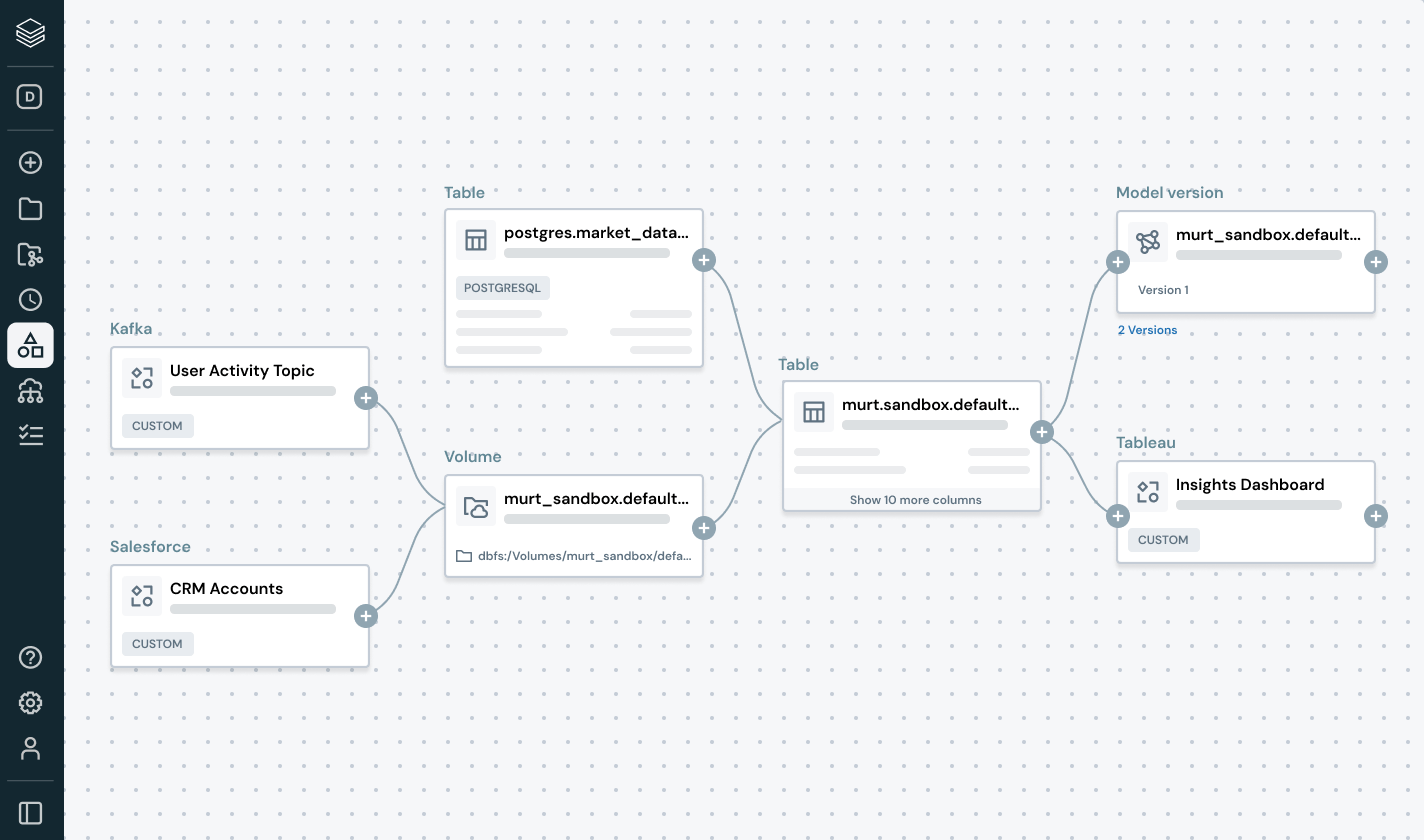
Rileva e risolvi proattivamente i problemi sui dati grazie a una visibilità completa su derivazione e segnali di qualità.
- Monitora lo stato di salute dei dati con controlli su freschezza e completezza e rilevamento di anomalie
- Traccia la derivazione end-to-end attraverso pipeline, modelli e dashboard
- Valuta l’impatto a valle di pipeline dati o AI interrotte
- Rafforza la fiducia mostrando informazioni sulla qualità accanto a ciascun asset
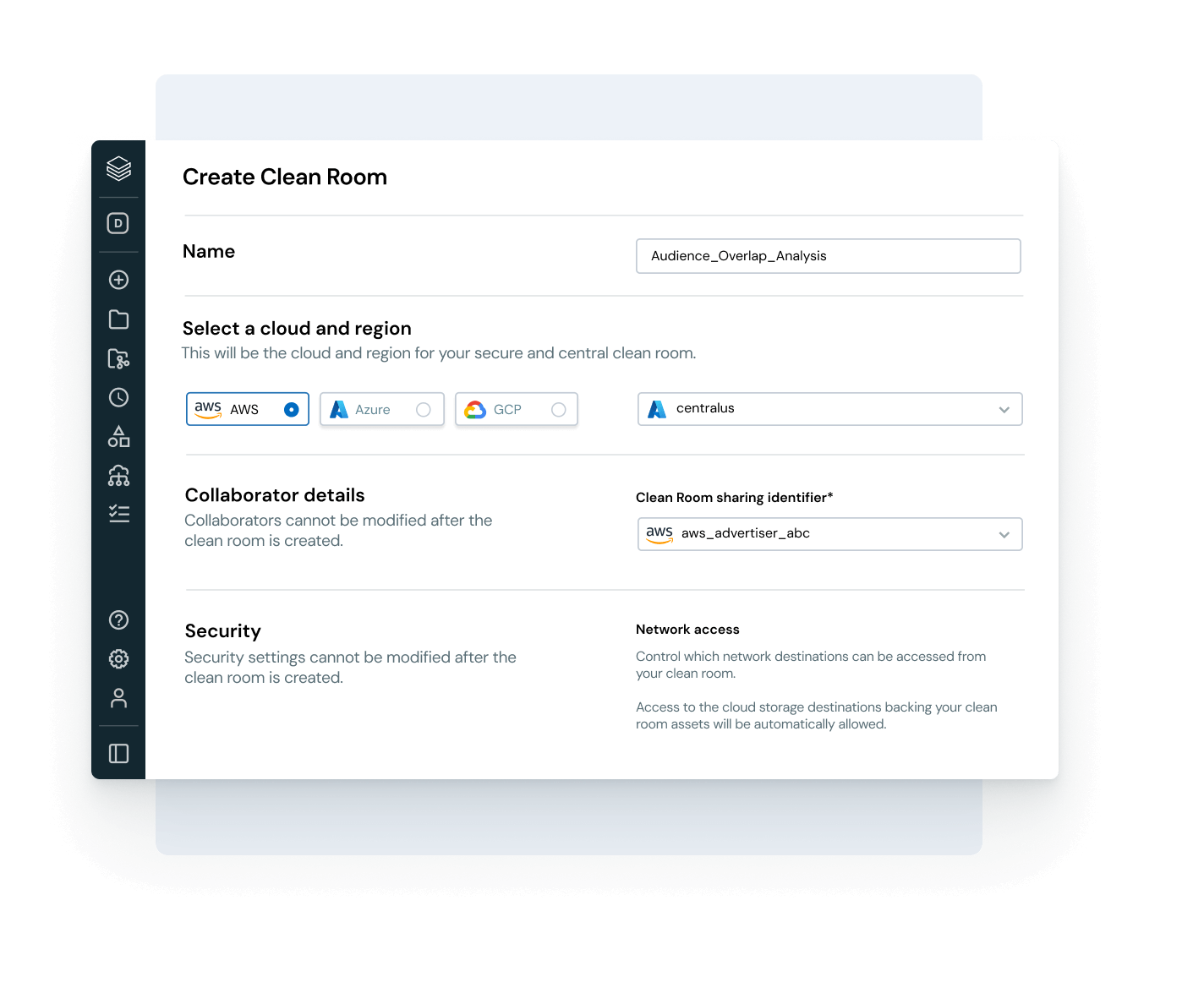
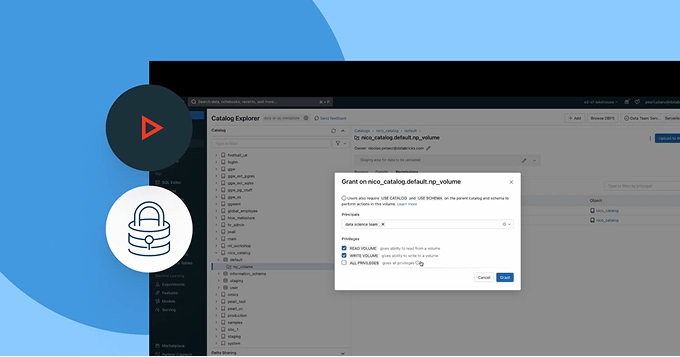
Abilita una collaborazione aperta e sicura tra cloud e partner
Abbatti i silos e scala la condivisione di dati e AI, con un controllo completo della governance.
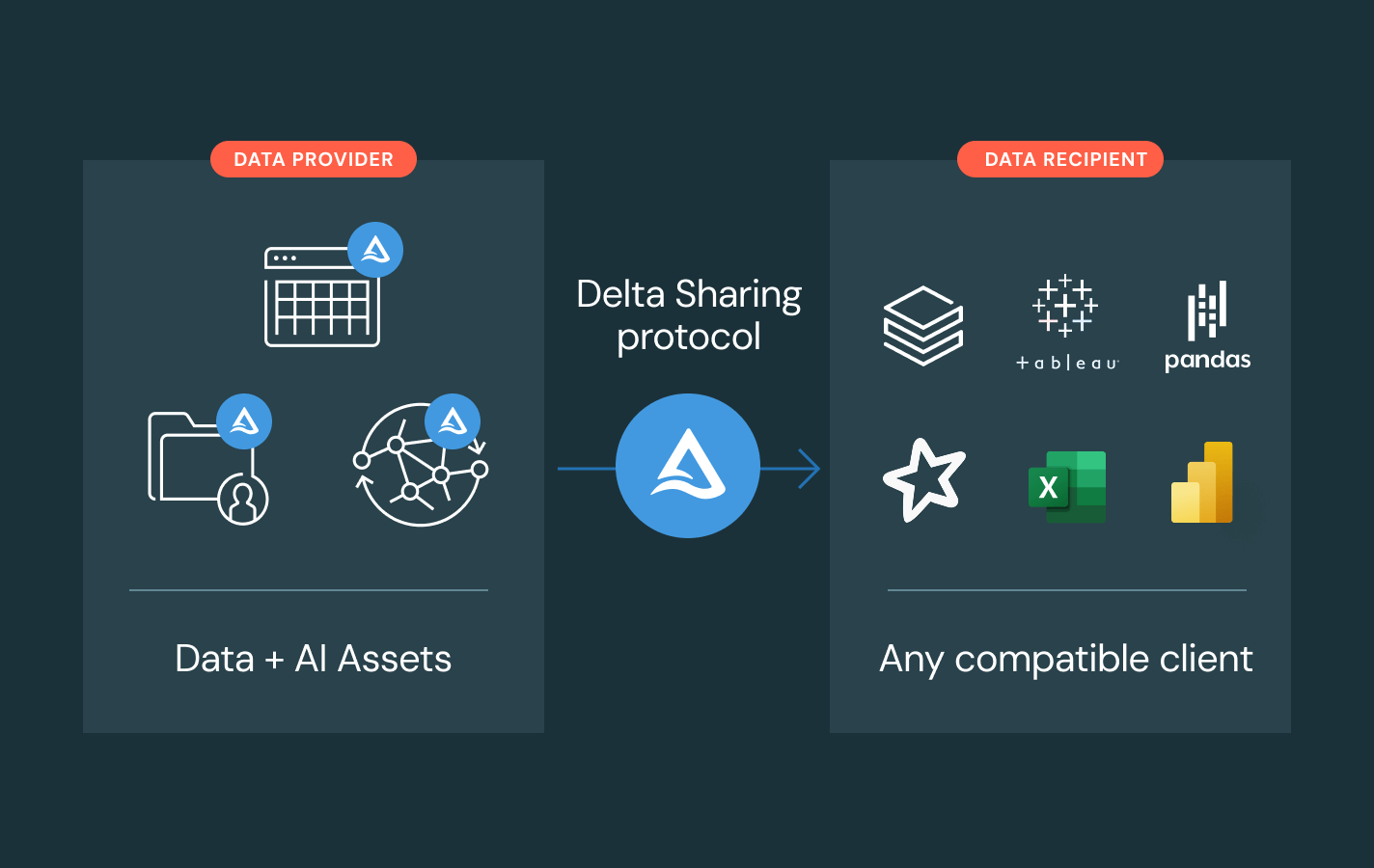
- Condividi asset di dati e AI governati tra team, cloud o partner tramite Delta Sharing
- Usa le clean room per una collaborazione sicura e rispettosa della privacy
- Evita di vincolarti a un unico fornitore grazie a standard di condivisione aperti
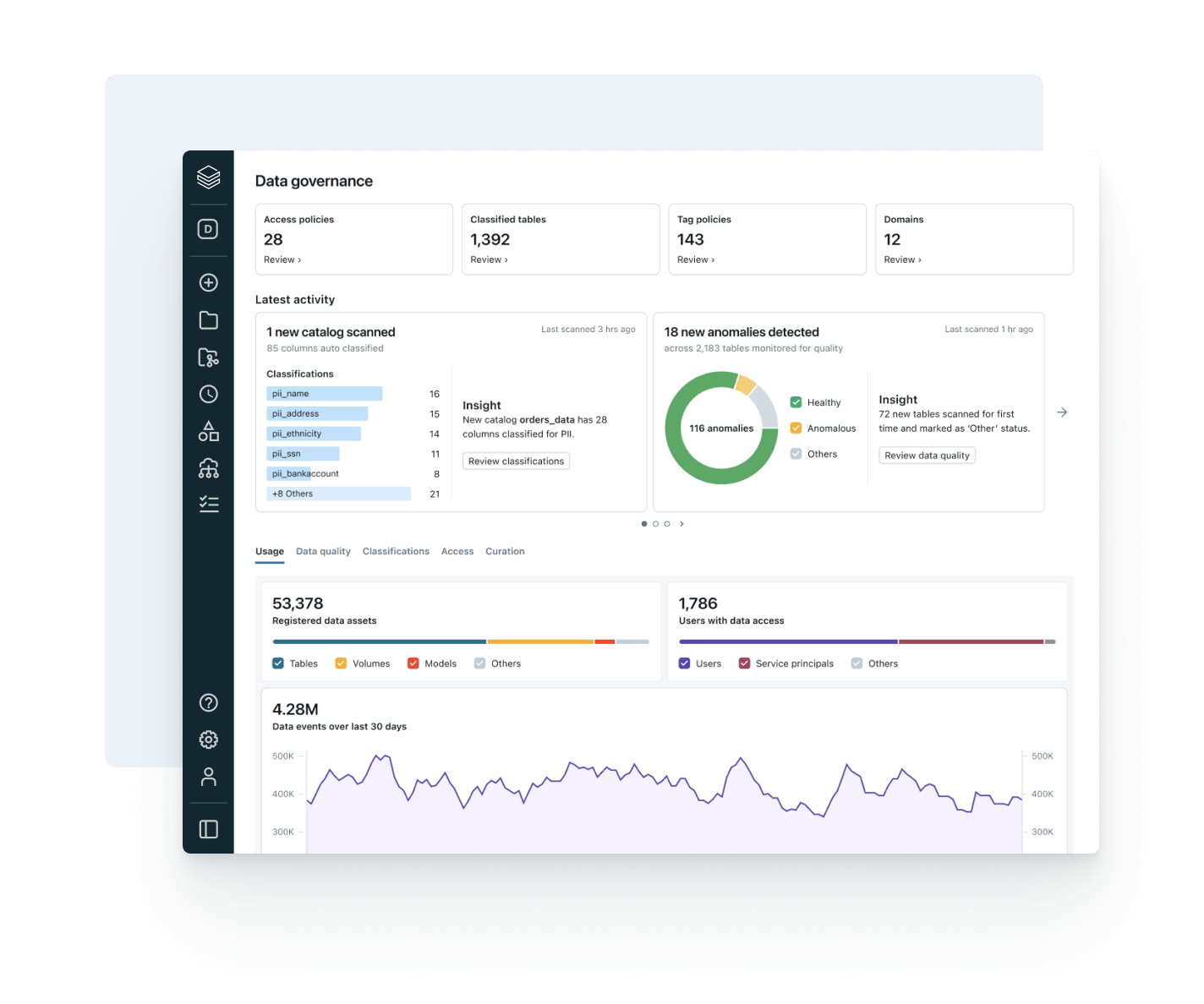
Allinea l'uso dei dati al valore aziendale e al costo operativo
Usa le funzionalità di osservabilità integrate per ottimizzare i costi, favorire l’adozione della governance e aumentare il ROI.
- Tieni traccia delle tendenze di consumo dei dati tra utenti, team e business unit
- Collega la derivazione all’utilizzo di calcolo e storage per individuare opportunità di ottimizzazione
- Monitora l’adozione delle policy e i pattern di accesso ai dati in un’unica interfaccia
- Consenti ai responsabili dei prodotti di dati di misurare e dimostrare il valore dei dati

Scopri di più
Scopri i prodotti che estendono la potenza di Unity Catalog in ambito di governance, collaborazione e data intelligence.
Databricks Clean Rooms
Analizza dati condivisi da più parti senza fornire un accesso diretto ai dati grezzi .

Databricks Marketplace
Un mercato aperto per risorse di dati, AI e analisi, come modelli di ML e notebook.

Delta Sharing
Un approccio open-source alla condivisione di dati e AI tra diverse piattaforme. Condividi dati in tempo reale con una governance centralizzata e senza repliche.

AI/BI Genie
Un'esperienza conversazionale, alimentata dall'AI generativa, che consente ai team aziendali di esplorare i dati e ottenere informazioni in tempo reale usando il linguaggio naturale.

Databricks Assistant
Ti basterà descrivere l'attività in linguaggio naturale e lasciare che l'assistente generi query SQL, spieghi codice complesso e corregga automaticamente gli errori.
Piattaforma di intelligenza dei dati Databricks
Esplora l'intera gamma di strumenti disponibili sulla Databricks Data Intelligence Platform per integrare perfettamente dati e AI in tutta l'organizzazione.
Fai il passo successivo
Esplora la documentazione di Unity Catalog
Consulta la documentazione di Unity Catalog per AWS, Azure e GCP per una guida dettagliata su funzionalità, configurazione e best practice.
Esplora le demo dei prodotti
Guarda le demo di Unity Catalog per scoprire come gestire, scoprire e condividere risorse di dati e AI in tutto il tuo ambiente dati.




FAQ su Unity Catalog
Sei pronto a mettere dati e AI alla base della tua azienda?
Inizia il tuo percorso di trasformazione dei dati