Ricerca vettoriale
Un database vettoriale altamente performante con governance integrata

Libera il potenziale dell'AI generativa con Databricks Vector Search
Vector Search è un database vettoriale serverless
perfettamente integrato nella Data Intelligence Platform
A differenza di altri database, Databricks Vector Search supporta la sincronizzazione automatica dei dati dall'origine all'indicizzazione, eliminando la complessa e costosa manutenzione delle pipeline. Sfrutta gli stessi strumenti di sicurezza e di governance dei dati che le organizzazioni hanno già costruito, per garantire la massima tranquillità. Grazie al suo design serverless, Databricks Vector Search è facilmente scalabile per supportare miliardi di embedding e migliaia di query in tempo reale al secondo.
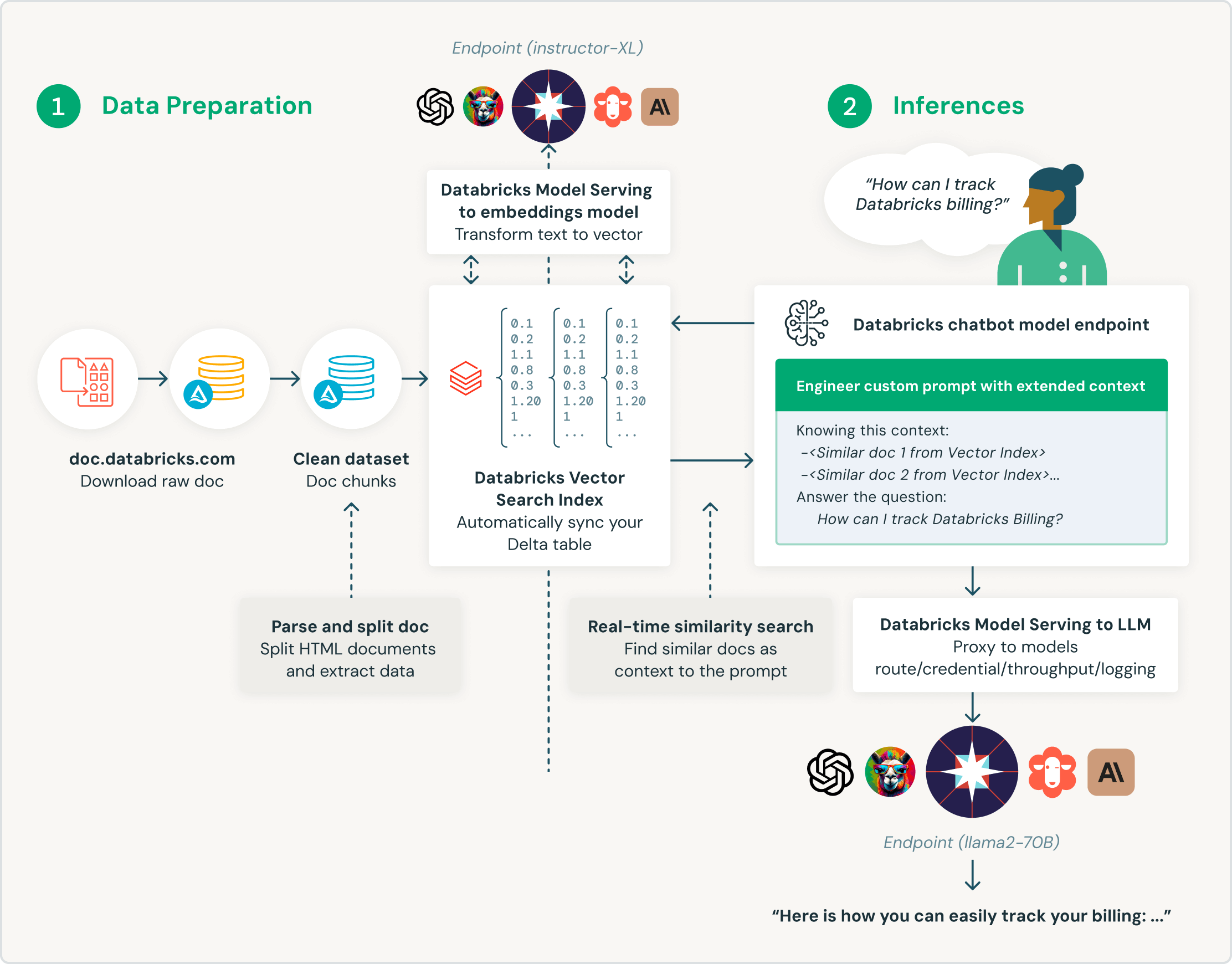
Costruito per la generazione potenziata del recupero (RAG)
Databricks Vector Search è stato creato appositamente per consentire ai clienti di potenziare i loro modelli linguistici di grandi dimensioni (LLM) con i dati aziendali. Specificamente progettato per le applicazioni di generazione potenziata del recupero (RAG ), Databricks Vector Search fornisce risultati di ricerca semanticamente simili, arricchendo le query LLM con il contesto e la conoscenza del settore e migliorando l'accuratezza e la qualità dei risultati.
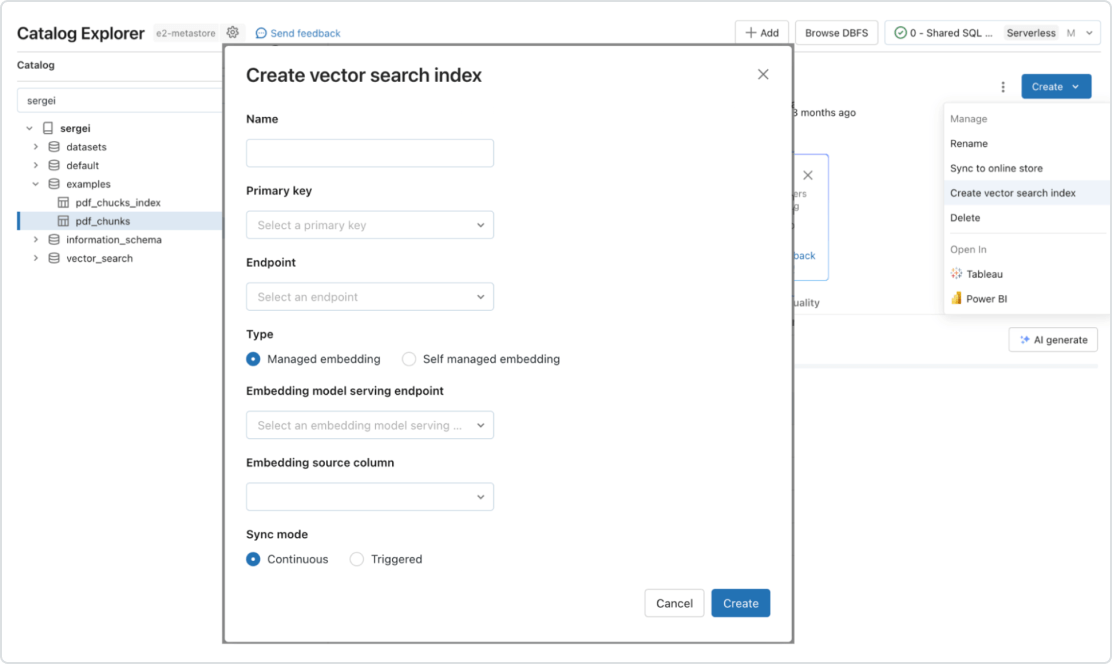
Pipeline automatizzate in tempo reale
Sincronizzazione in tempo reale dei dati sorgente tramite aggiornamento automatico del corrispondente indice vettoriale non appena vengono introdotti, modificati o rimossi nuovi dati. Dietro le quinte, Databricks si occupa della generazione e della gestione dei vettori di embedding, gestisce automaticamente errori e tentativi ripetuti, ottimizza il throughput, regola le dimensioni dei batch e scala senza alcun intervento.
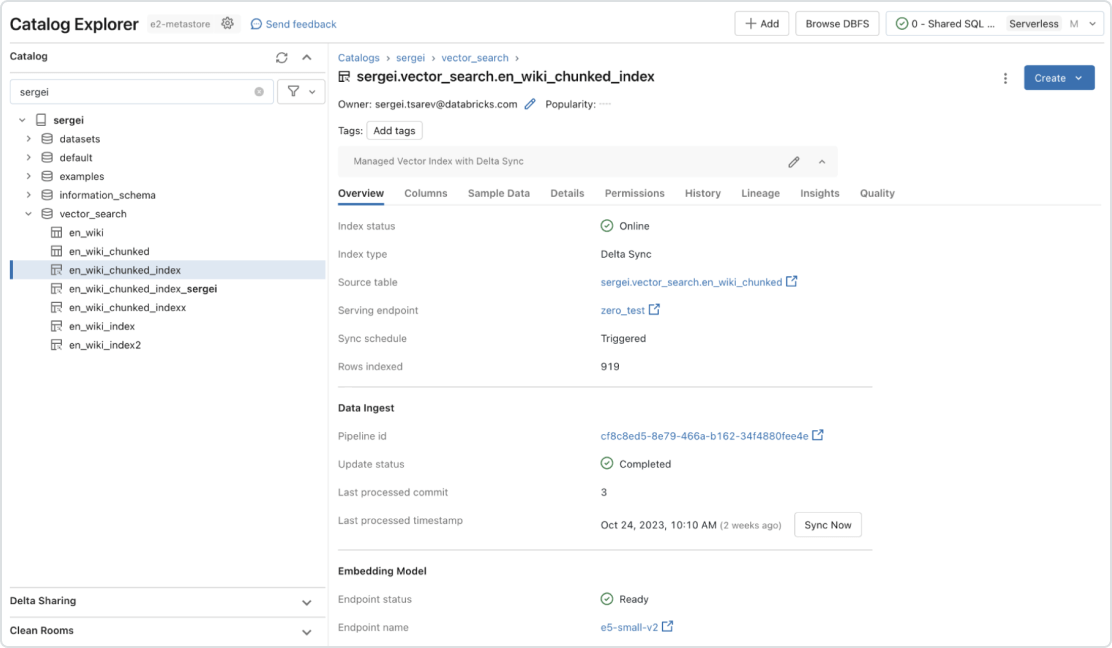
Governance integrata
L'interfaccia unificata definisce le politiche sui dati, con un controllo granulare sull'accesso agli embedding. Grazie all'integrazione con Unity Catalog, Vector Search mostra provenienza e tracciatura dei dati automaticamente, senza bisogno di ulteriori strumenti o politiche di sicurezza. Ciò garantisce che i modelli LLM non espongano dati riservati a utenti non autorizzati.
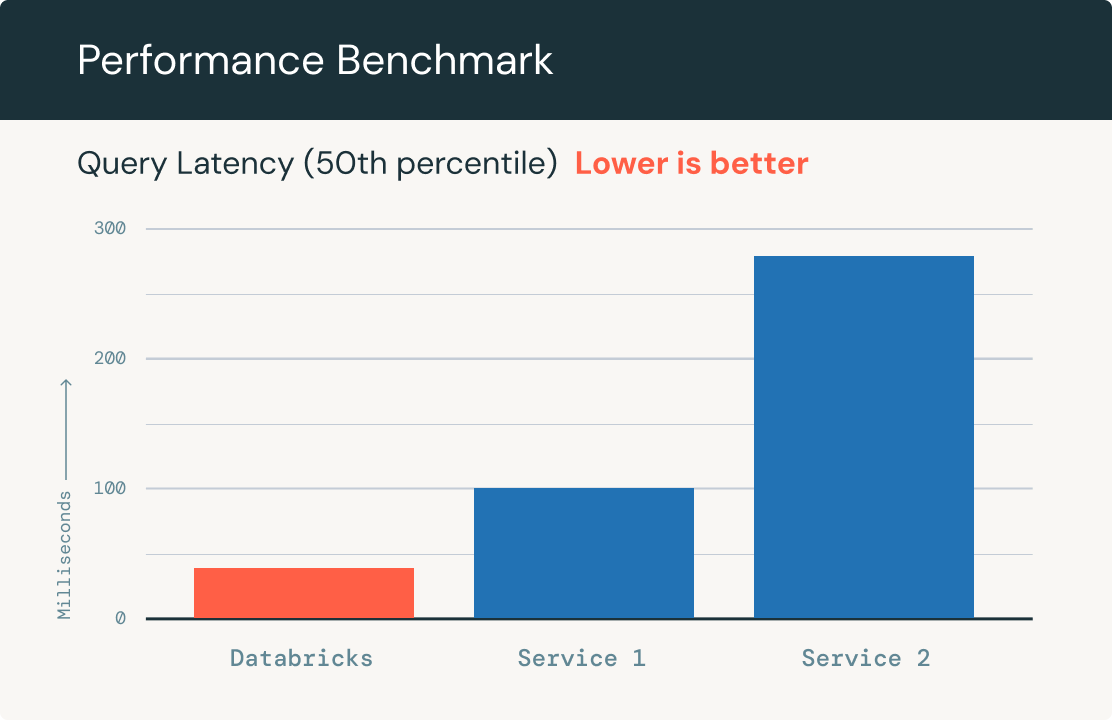
Prestazioni veloci delle query
Scala automaticamente per gestire miliardi di embedding in un indice e migliaia di query al secondo. Mostra prestazioni fino a 5 volte superiori rispetto agli altri principali database vettoriali su fino a 1 milione di set di dati di embedding OpenAI.