Spark su Databricks
La piattaforma migliore per eseguire carichi di lavoro Spark, dai creatori originali di Apache Spark™
Semplicità, eccellenza operativa ai vertici del settore e benefici in termini di prezzo/prestazioni fanno della Databricks Lakehouse Platform l'ambiente migliore su cui eseguire i carichi di lavoro Apache Spark™
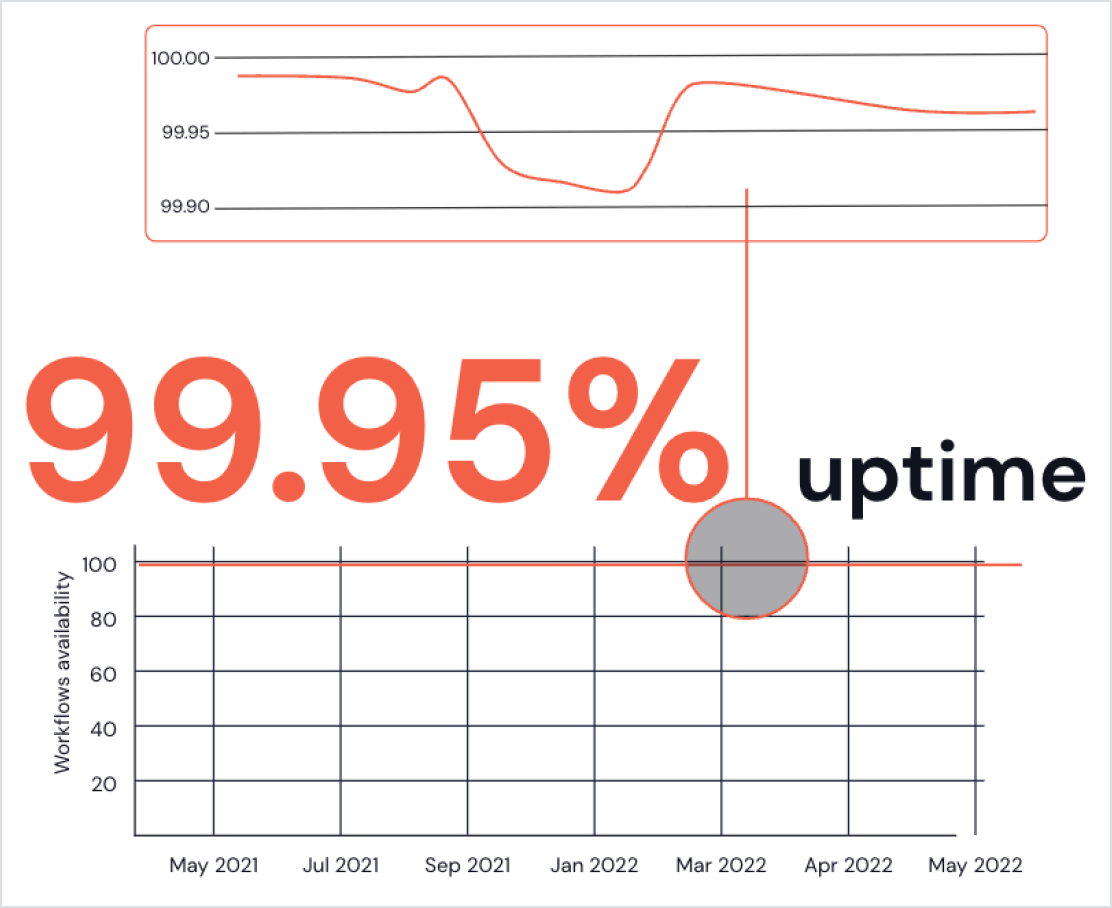
Eccellenza operativa ai vertici del settore
Aiutiamo migliaia di clienti a lanciare milioni di macchine virtuali (VM) ogni giorno per eseguire le loro applicazioni Spark. Inoltre, supportiamo gli strumenti e le guide per sviluppatori più avanzati, consentendo di sviluppare e implementare applicazioni Spark in modo semplice e affidabile.
- Le applicazioni Spark possono essere eseguite singolarmente o implementate facilmente su Databricks Workflows
- I notebook Spark possono essere eseguiti con altri tipi di compiti per pipeline di dati dichiarative su risorse di calcolo completamente gestite
- Il monitoraggio del flusso di lavoro consente di tracciare facilmente le prestazioni delle applicazioni Spark nel tempo e diagnosticare i problemi con pochi clic
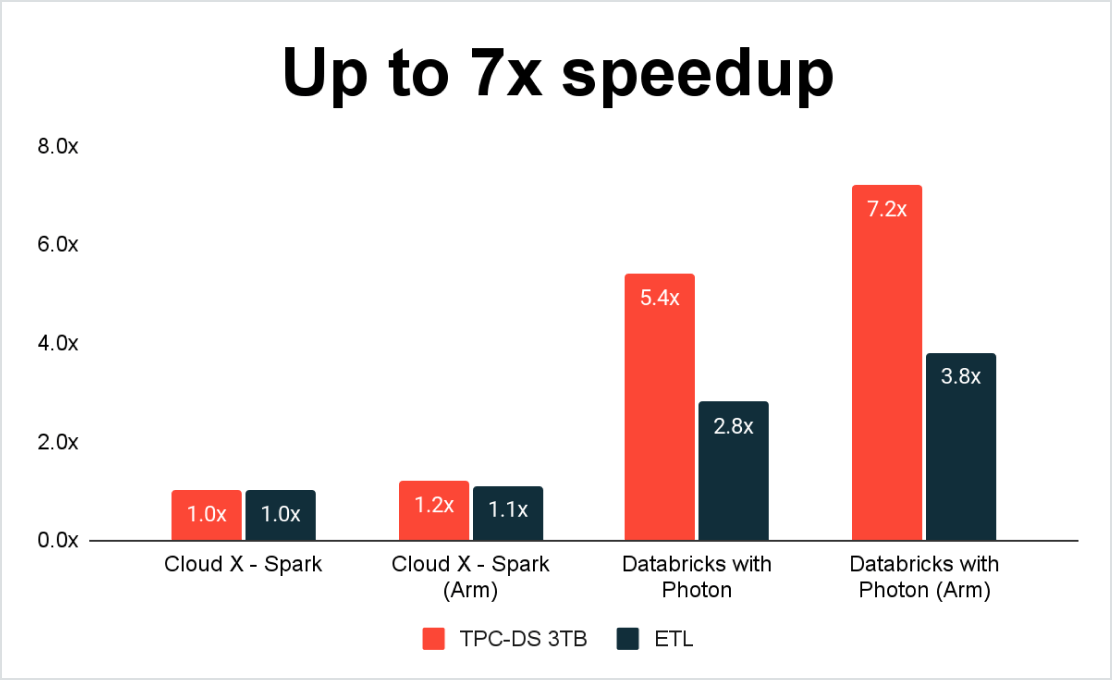
Il miglior rapporto prezzo/prestazioni per carichi di lavoro Spark
Eseguire i carichi di lavoro Spark sulla Databricks Lakehouse Platform significa beneficiare di Photon , un veloce motore di esecuzione vettoriale C++ per carichi di lavoro Spark e SQL che gira dietro le interfacce di programmazione esistenti di Spark. Photon offre prestazioni di query da record a costi bassi, sfruttando al tempo stesso le architetture hardware più moderne come AWS Graviton.
Oltre alle prestazioni ad altissima velocità, Spark su Databricks assicura un TCO complessivo ridotto grazie a funzionalità come l'autodimensionamento dinamico, che consente di pagare "a consumo". Databricks offre inoltre istanze GPU e spot.

Analisi a 360 gradi e governance unificata con la Databricks Lakehouse Platform
Mentre altre piattaforme richiedono di integrare più strumenti e gestire diversi modelli di governance, Databricks unifica data warehouse, data lake e dati in streaming in un'unica, semplice piattaforma lakehouse per gestire tutti i casi d'uso di data engineering, analisi e AI. La soluzione è costruita su una piattaforma aperta e affidabile che gestisce in maniera efficiente tutti i tipi di dati, unifica batch e streaming, e applica un unico modello comune di sicurezza e governance, per tutti i dati e le piattaforme cloud.

Innovazione continua
The 2022 SIGMOD Systems Award ha riconosciuto Spark come sistema open-source per l'elaborazione unificata dei dati innovativo e ampiamente diffuso, che comprende carichi di lavoro relazionali, in streaming e machine learning.
E l'innovazione continua. Recentemente abbiamo introdotto Spark Connect e Project Lightspeed.
Spark Connect disaccoppia il client e il server per aumentare la stabilità e consente di realizzare applicazioni Spark ovunque.
Project Lightspeed, la nuova generazione di Spark Structured Streaming, porta miglioramenti in termini di bassa latenza prevedibile e funzionalità avanzate per l'elaborazione di eventi.
Ready to get started?