Semplifica il ciclo di vita del machine learning
Passa da un'organizzazione e un'infrastruttura tecnologica a compartimenti stagni a una piattaforma aperta e unificata per l'intero ciclo di vita dei dati e del ML

Costruire modelli ML è difficile. Portarli in produzione è ancora più difficile. Mantenere la qualità dei dati e la precisione dei modelli nel tempo è solo una delle tante sfide. Databricks snellisce lo sviluppo del ML con modalità uniche, dalla preparazione dei dati all'addestramento e all'implementazione dei modelli, su larga scala.
La sfida
Le enormi differenze fra le infrastrutture di ML rendono la gestione degli ambienti ML molto complicata.
Passaggi di consegne difficili fra i team a causa di strumenti e processi differenti per la preparazione dei dati la sperimentazione e la produzione.
Difficile tracciabilità di esperimenti, modelli, dipendenze e artefatti, con conseguenti difficoltà nell'ottenere risultati riproducibili.
Rischi di sicurezza e conformità.
La soluzione
Accesso con un clic ad ambienti ML pronti all'uso, ottimizzati e scalabili lungo tutto il ciclo di vita.
Un'unica piattaforma per acquisizione di dati, creazione di funzionalità, costruzione, perfezionamento e produzionalizzazione dei modelli per semplificare i passaggi di consegne.
Tracciamento automatico di esperimenti, codice, risultati e artefatti e gestione dei modelli in un hub centralizzato.
Rispetto delle esigenze di conformità con funzionalità granulari per controllo degli accessi, provenienza dei dati e gestione delle versioni.
Databricks per Machine Learning
Scopri come Databricks aiuta a preparare i dati e a costruire, implementare e gestire modelli ML in modo collaborativo e di ottimo livello, dalla sperimentazione alla produzione, su una scala senza precedenti.
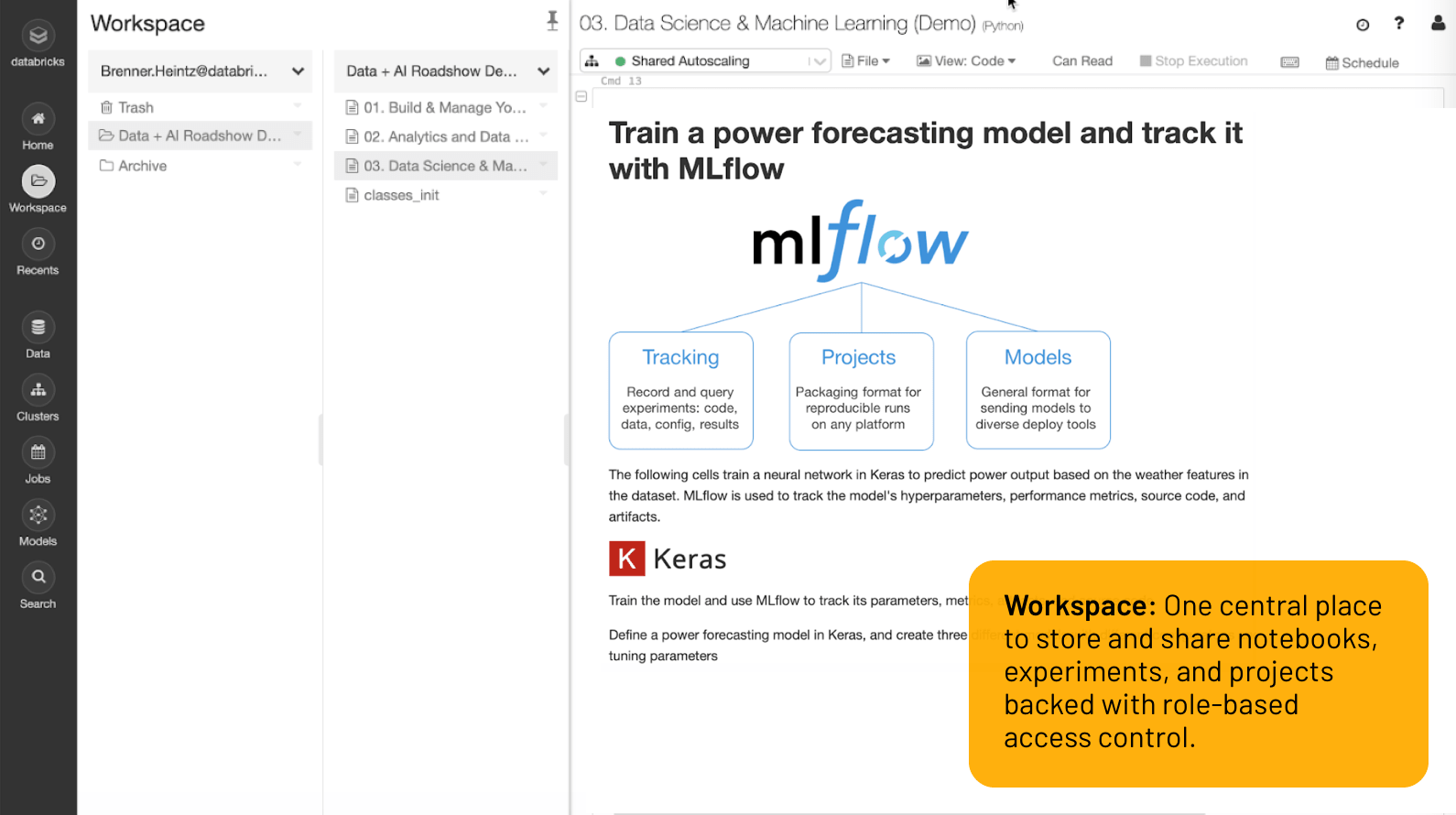
Workspace
Un unico spazio di lavoro centralizzato per memorizzare e condividere notebook, esperimenti e progetti, supportato dal controllo degli accessi per ruoli.
ML dalla sperimentazione alla produzione su una scala senza confronti
Il migliore ambiente per gli sviluppatori
Tutto quello che ti serve è a portata di mouse nel Workspace: set di dati, ambienti ML, notebook, file, esperimenti e modelli sono tutti disponibili in modo sicuro in un unico luogo.
I notebook collaborativi con supporto per più linguaggi (Python, R, Scala, SQL) semplificano il lavoro in team mentre co-authoring, integrazione Git, gestione delle versioni, controllo degli accessi per ruoli e altre funzioni ti aiutano a tenere tutto sotto controllo. Altrimenti puoi usare strumenti familiari come Jupyter Lab, PyCharm, IntelliJ, RStudio con Databricks per beneficiare di storage ed elaborazione di dati illimitati.
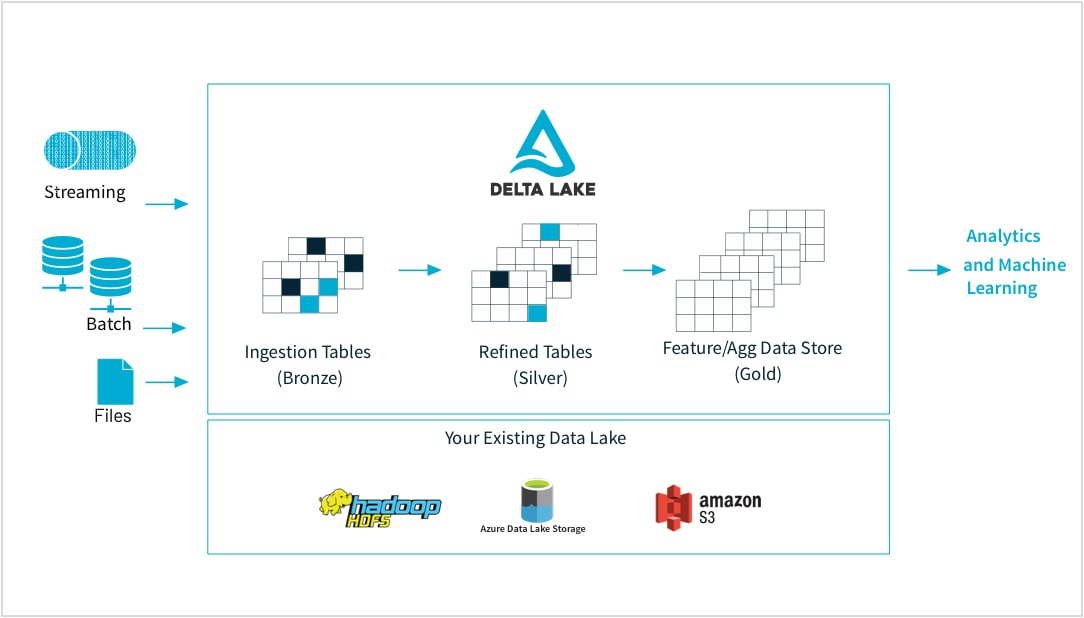
Dai dati grezzi al negozio di funzionalità di alta qualità
I professionisti del machine learning addestrano i modelli tramite un'ampia gamma di forme e formati di dati: set piccoli e grandi, DataFrame, testi, immagini, batch o streaming. Tutti richiedono pipeline e trasformazioni specifiche.
Databricks consente di acquisire dati grezzi praticamente da qualunque sorgente, unire i dati in batch e in streaming, programmare trasformazioni, gestire diverse versioni delle tabelle ed eseguire controlli di qualità per assicurare che i dati siano impeccabili e pronti per essere analizzati da ogni reparto dell'organizzazione. In questo modo puoi lavorare in modo trasparente e affidabile su qualsiasi dato, file CSV o acquisizione massiccia da data lake, secondo le tue esigenze.

Il posto migliore per eseguire Scikit-Learn, TensorFlow, PyTorch e altro…
I framework di ML si evolvono molto rapidamente, rendendo difficile la manutenzione degli ambienti ML. Databricks ML Runtime fornisce ambienti ML pronti all'uso e ottimizzati, inclusi i framework ML più diffusi (Scikit-Learn, TensorFlow ecc.), oltre al supporto di Conda.
AutoML integrato e regolazione degli iperparametri aiutano a ottenere risultati più velocemente, mentre il dimensionamento semplificato consente di aumentare senza difficoltà il volume di dati (da "small" a "big" data) senza più essere limitati dalla capacità di calcolo disponibile. Ad esempio, si possono addestrare modelli di deep learning più velocemente distribuendo il calcolo su tutti i cluster con HorovodRunner e ottenere massime prestazioni da ogni GPU del cluster eseguendo la versione di TensorFlow ottimizzata per CUDA.
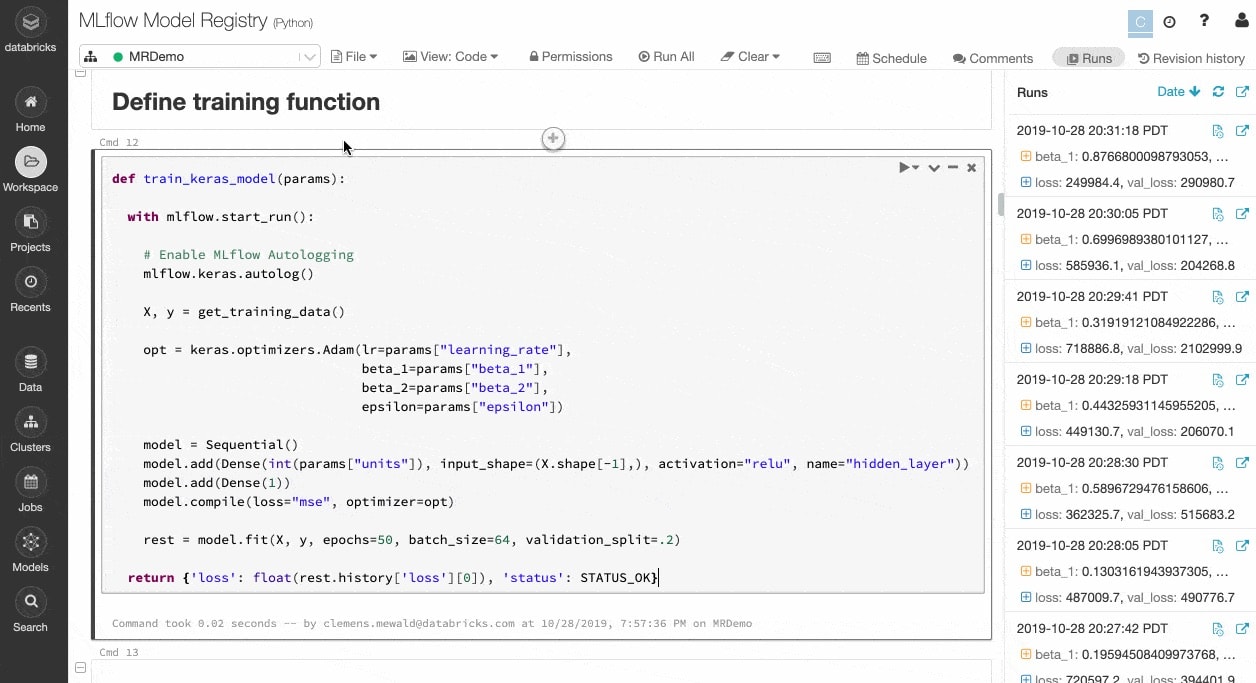
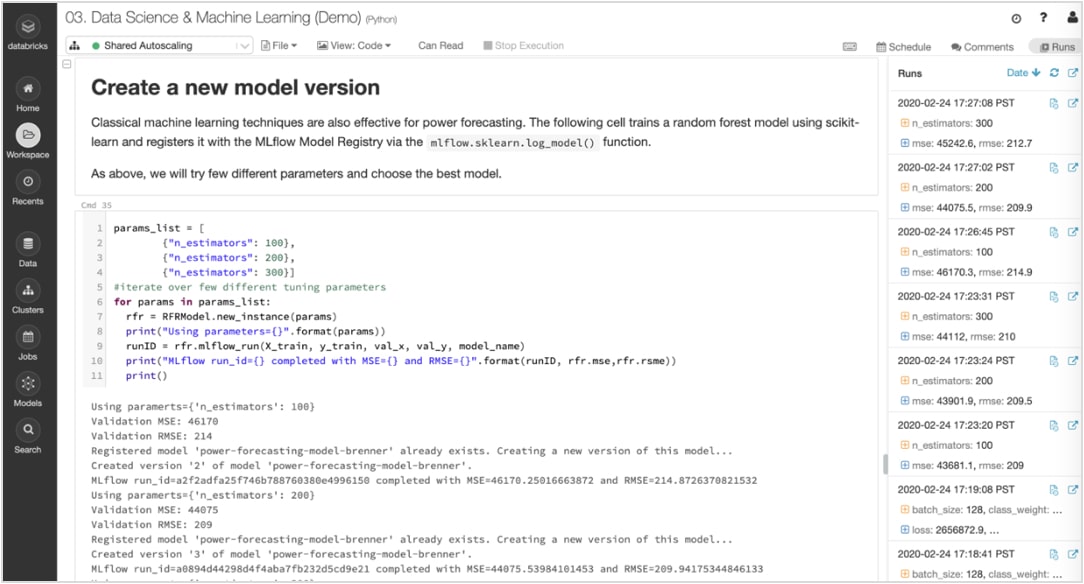
Traccia esperimenti e artefatti per riprodurre le esecuzioni in un secondo momento
Gli algoritmi di ML hanno decine di parametri configurabili e, che si lavori da soli o in team, è difficile tenere traccia di quali parametri, quale codice e quali dati sono stati utilizzati in ciascun esperimento per produrre un modello.
MLflow traccia automaticamente gli esperimenti insieme ad artefatti quali dati, codice, parametri e risultati per ogni ciclo di addestramento eseguito dai notebook. Così puoi visualizzare velocemente i cicli precedenti, confrontare i risultati e ripristinare una versione precedente del codice se necessario. Una volta individuata la versione migliore di un modello per la produzione, puoi registrarlo in un repository centrale e renderlo disponibile per l'implementazione e per semplificare i passaggi di consegne.
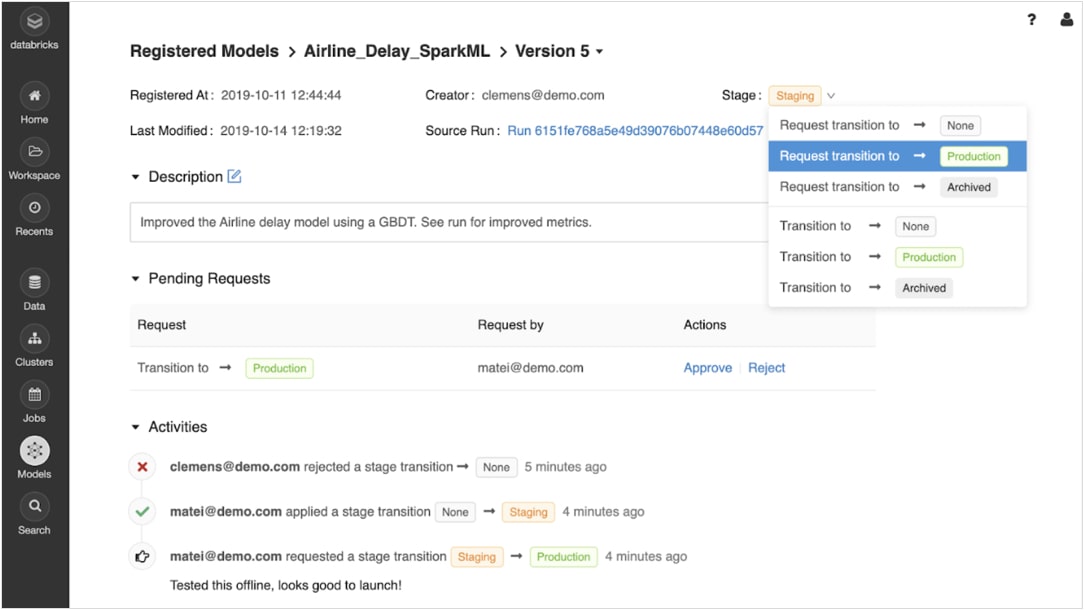
Passa dalla prototipazione alla produzione senza preoccupazioni
Una volta registrati, i modelli addestrati possono essere gestiti in maniera collaborativa lungo tutto il ciclo di vita con il registro dei modelli di MLflow.
Si possono gestire diverse versioni e i modelli possono passare attraverso diversi stadi, ad esempio sperimentazione, staging, produzione e archiviazione. Tutti i soggetti coinvolti possono commentare e inviare richieste di cambiamento di fase. Tutta la gestione del ciclo di vita si integra con i flussi di lavoro di approvazione e governance, con controlli di accesso basati sui ruoli.
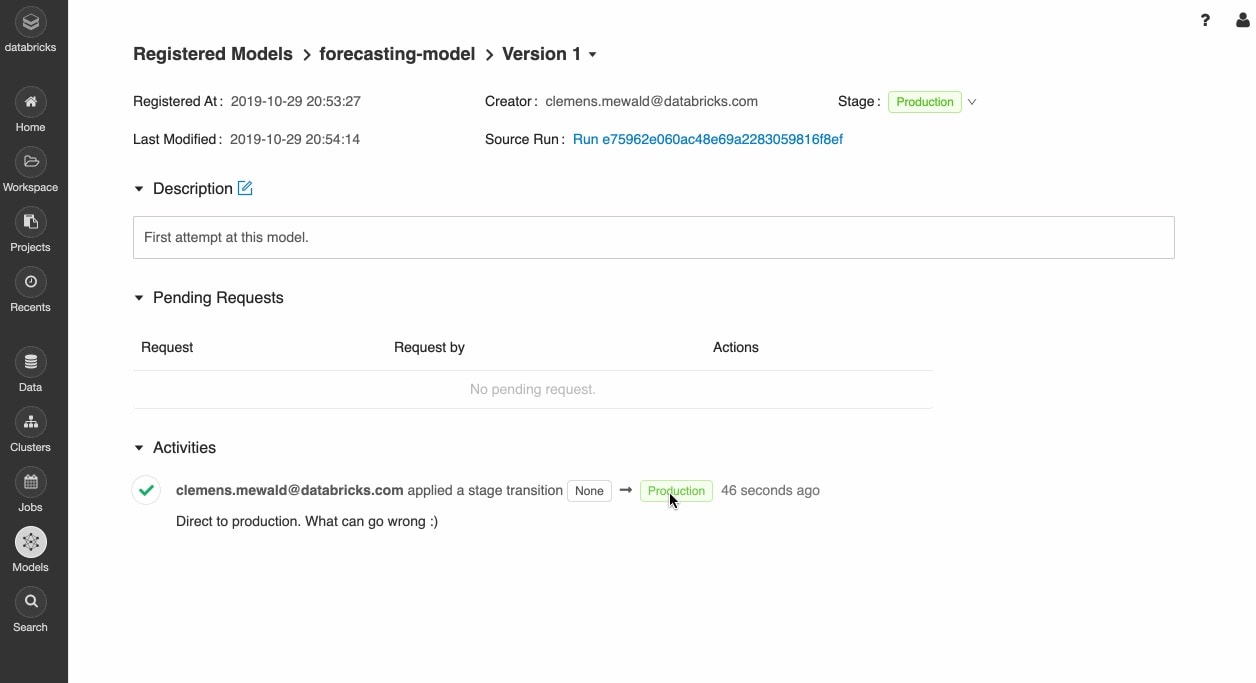
Implementa modelli ovunque
Implementa velocemente modelli in produzione per l'inferenza in batch su Apache Spark™ o come API REST utilizzando l'integrazione con contenitori Docker, Azure ML e Amazon SageMaker.
Operazionalizza i modelli in produzione utilizzando Jobs Scheduler e cluster autogestiti per scalare la soluzione in base alle esigenze dell'azienda.
Rendi velocemente operative le versioni più recenti dei modelli e monitora la deriva dei modelli con Delta Lake e MLflow.
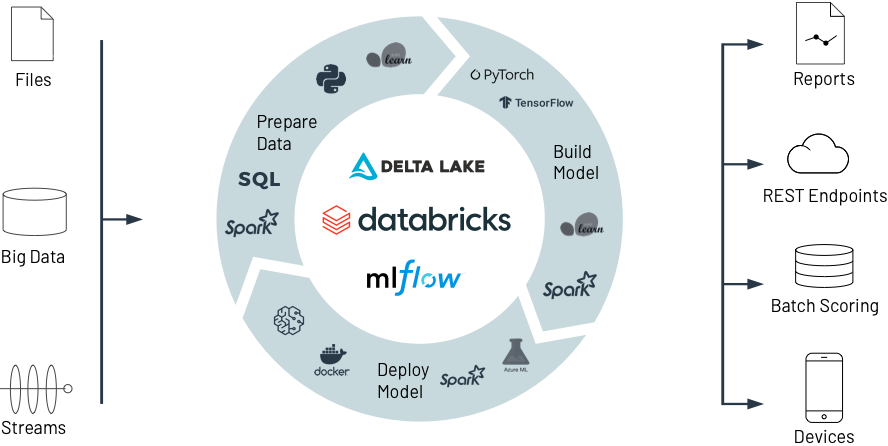
Come funziona
Gestione dell'intero ciclo di vita del machine learning su Databricks
Risorse
Report

eBook

eBook

Ready to get started?