TensorFlow™ su Databricks

Calcolo distribuito con TensorFlow
TensorFlow supporta il calcolo distribuito, consentendo di elaborare porzioni del grafo su diversi processi che possono essere localizzati su server diversi. Inoltre, il calcolo può essere distribuito su server con GPU potenti, mentre altri calcoli possono essere effettuati su server con più memoria, e così via. L'interfaccia è però un po' complicata, pertanto partiamo dall'inizio.
Ecco il nostro primo script, che eseguiremo su un singolo processo, per poi passare a processi multipli:
Per ora questo script non ci dovrebbe spaventare troppo. Abbiamo una costante e tre equazioni elementari. Alla fine viene stampato il risultato (238).
TensorFlow funziona in modo simile a un modello client-server. L'idea è creare un gruppo di "worker" che eseguiranno il lavoro pesante. Successivamente si crea una sessione su uno di questi worker, che a sua volta elaborerà il grafo, eventualmente distribuendone alcune parti ad altri cluster sul server.
Per fare questo, il worker principale, detto "master", deve essere a conoscenza degli altri worker. Questa condizione viene soddisfatta creando un ClusterSpec, che deve essere passato a tutti i worker. Il ClusterSpec viene costruito utilizzando un dizionario, dove la chiave è un "job name" e ogni job contiene molti worker.
Il processo è illustrato nello schema successivo.
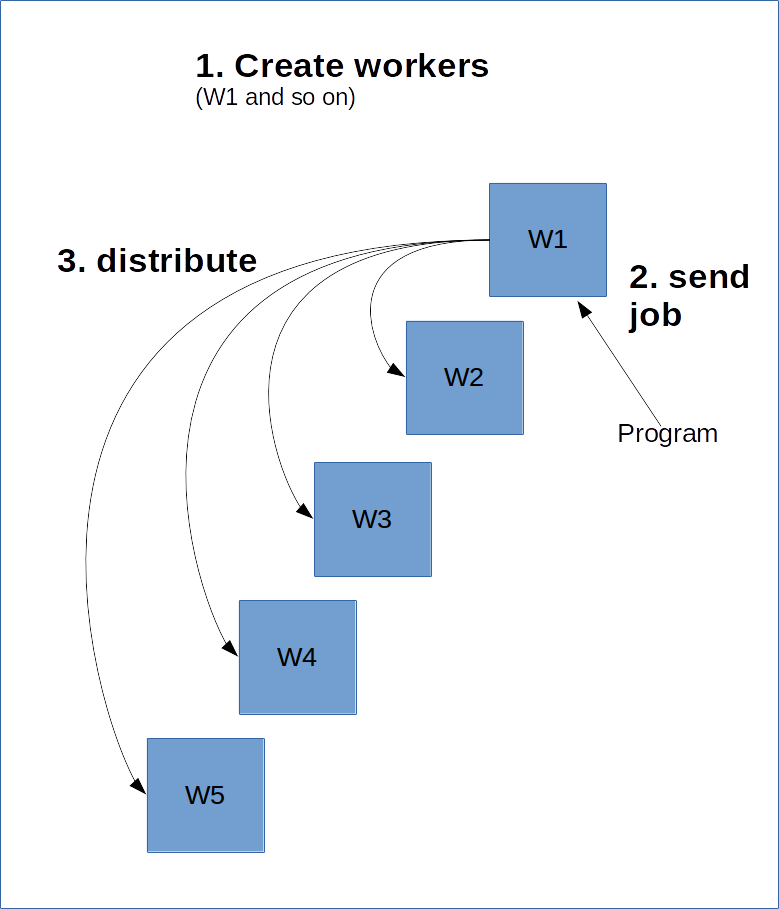
Il codice seguente crea un ClusterSpec con job name "local" e due processi worker.
Bisogna notare come i processi non vengano avviati da questo codice, semplicemente viene creato un riferimento al loro avvio futuro.
Il passo successivo è avviare il processo. Per farlo, creiamo un grafo di uno di questi worker e avviamolo:
Il codice precedente avvia il worker “localhost:2223” sotto il job “local”.
Qui sotto riportiamo uno script che può essere eseguito dalla riga di comando per avviare i due processi. Salva il codice sul computer come create_worker.py ed eseguilo con python create_worker.py 0 e poi python create_worker.py 1. Per farlo serviranno terminali separati, poiché gli script non terminano in maniera autonoma (restano in attesa di istruzioni).
Fatto questo, i server saranno in esecuzione sui due terminali. Siamo pronti a distribuire!
Il modo più semplice per distribuire il lavoro è creare una sessione su uno di questi processi, dove poi viene eseguito il grafo. Basta sostituire la riga "session" precedente con la seguente:
Ora, questa operazione non avvia la distribuzione vera e propria, ma semplicemente invia il job a quel server. TensorFlow potrebbe distribuire l'elaborazione ad altre risorse nel cluster, ma potrebbe anche non farlo. Questo comportamento può essere forzato specificando i dispositivi (come abbiamo fatto con le GPU nella lezione precedente):
Ora stiamo effettivamente distribuendo! La procedura funziona allocando compiti o attività (task) ai worker, in base al nome e al numero del task. Il formato è:
/job:JOB_NAME/task:TASK_NUMBER
Con job multipli (cioè per i computer con grandi GPU), possiamo distribuire l'elaborazione in diversi modi.
Mappatura e riduzione
MapReduce è un paradigma molto diffuso per elaborare operazioni di grande entità. È articolato in due fasi principali (anche se in realtà il processo prevede più passaggi).
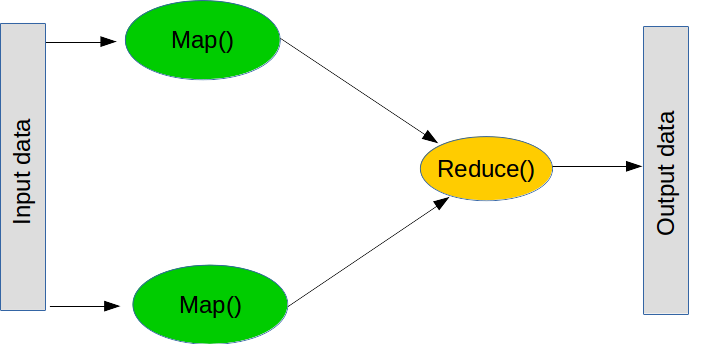
Il primo passaggio è la cosiddetta mappatura, che significa “prendi questo elenco di oggetti e applica questa funzione a ciascuno”. La mappatura può essere eseguita in normale linguaggio Python nel modo seguente:
Il secondo passaggio è detto riduzione, che significa “prendi questo elenco di oggetti e combinali usando questa funzione”. Un'operazione di riduzione comune è l'addizione, cioè "prendi questo elenco di numeri e raggruppali sommandoli fra loro”, che può essere eseguita creando una funzione che somma due numeri. La funzione Reduce prende i primi due valori dell'elenco, esegue la funzione, prende il risultato e poi esegue nuovamente la funzione con il risultato e il valore successivo nella lista. Nel caso dell'addizione, sommiamo i primi due numeri, prendiamo il risultato, lo sommiamo con il numero successivo, e così via fino al termine della lista. Anche la riduzione fa parte del normale linguaggio Python (anche se non è distribuita):
È importante notare che non dovrebbe mai essere veramente necessario utilizzare Reduce: basta usare un ciclo for.
Tornando a TensorFlow distribuito, eseguire operazioni Map e Reduce è un passaggio chiave di molti programmi non banali. Ad esempio, un apprendimento d'insieme (ensemble learning) può inviare singoli modelli di machine learning a molteplici worker e poi combinare le classificazioni per formare il risultato finale. Un altro esempio è un processo che
Ecco un altro script elementare che distribuiremo:
La conversione a una versione distribuita è semplicemente un'alterazione della conversione precedente:
Il calcolo distribuito risulterà molto più semplice se lo si pensa in termini di mappature e riduzioni. Primo: "Come posso suddividere il problema in sottoproblemi che possono essere risolti individualmente?". Questa è la mappatura. Secondo: "Come posso combinare le risposte per ottenere un risultato finale?". Questa è la riduzione.
Nel machine learning, il metodo Map più comune consiste semplicemente nel suddividere i set di dati. Modelli lineari e reti neurali risultano spesso alquanto efficaci in questo caso, perché possono essere addestrati separatamente e poi combinati in un secondo tempo.
1) Sostituisci la parola “local” nel ClusterSpec con un'altra. Che cos'altro bisogna cambiare nello script per farlo funzionare?
2) Lo script che elabora la media attualmente fa affidamento sul fatto che le diverse porzioni hanno tutte le stesse dimensioni. Proviamo con "fette" di dimensioni diverse e osserviamo l'errore. Correggiamolo utilizzando tf.size e la formula seguente per combinare le medie delle fette:
3) Si può specificare un dispositivo su un computer remoto modificando la stringa del dispositivo. Ad esempio, “/job:local/task:0/gpu:0” punterà alla GPU sul job locale. Crea un job che utilizza una GPU remota. Se hai a portata di mano un secondo computer, prova a farlo via rete.